JAVA线程池学习总结
原文来自:林炳文Evankaka原创作品。转载请注明出处http://blog.csdn.net/evankaka
https://blog.csdn.net/evankaka/article/details/51610635 Callable、Future、FutureTask、CompletionService
https://blog.csdn.net/evankaka/article/details/51489322 线程池
一些自己的总结,原文更详细。还有源码应该是JDK1.6的(相比于8有改变但是大体思路是一样的),有点老了 。
线程池
线程池,可以理解为体现创建好若干线程,有要执行的任务的时候直接将任务交给线程池里面的线程执行,不用一个任务就创建一个线程。那使用线程池有什么好处呢?
一、减少在创建和销毁线程上所花的时间以及系统资源的开销 。
二、将当前任务与主线程隔离,能实现和主线程的异步执行,特别是很多可以分开重复执行的任务。但是,一味的开线程也不一定能带来性能上的,线池休眠也是要占用一定的内存空间,所以合理的选择线程池的大小也是有一定的依据。
线程池的种类
Java类库提供了许多静态方法来创建一个线程池:
a、newFixedThreadPool 创建一个固定长度的线程池,当到达线程最大数量时,线程池的规模将不再变化。
b、newCachedThreadPool 创建一个可缓存的线程池,如果当前线程池的规模超出了处理需求,将回收空的线程;当需求增加时,会增加线程数量;线程池规模无限制。
c、newSingleThreadPoolExecutor 创建一个单线程的Executor,确保任务对了,串行执行
d、newScheduledThreadPool 创建一个固定长度的线程池,而且以延迟或者定时的方式来执行,类似Timer;
小结一下:在线程池中执行任务比为每个任务分配一个线程优势更多,通过重用现有的线程而不是创建新线程,可以在处理多个请求时分摊线程创建和销毁产生的巨大的开销。当请求到达时,通常工作线程已经存在,提高了响应性;通过配置线程池的大小,可以创建足够多的线程使CPU达到忙碌状态,还可以防止线程太多耗尽计算机的资源。
示例
//示例用的类,线程池执行的类需要实现Runnable接口
class Handler implements Runnable{
}
//定义一个线程池newCachedThreadPool()可以换成其他的(四种中的一种)
ExecutorService executorService = Executors.newCachedThreadPool();
//比如换成固定的
int cpuNums = Runtime.getRuntime().availableProcessors(); //获取当前系统的CPU 数目
ExecutorService executorService =Executors.newFixedThreadPool(cpuNums * POOL_SIZE); //ExecutorService通常根据系统资源情况灵活定义线程池大小
//往线程池添加待执行的任务
while(true){
executorService.execute(new Handler(socket));
// class Handler implements Runnable{
或者
executorService.execute(createTask(i));
//private static Runnable createTask(final int taskID)
}execute(Runnable对象)方法其实就是对Runnable对象调用start()方法(当然还有一些其他后台动作,比如队列,优先级,IDLE timeout,active激活等)
| newCachedThreadPool() | -缓存型池子,先查看池中有没有以前建立的线程,如果有,就reuse.如果没有,就建一个新的线程加入池中 -缓存型池子通常用于执行一些生存期很短的异步型任务 因此在一些面向连接的daemon型SERVER中用得不多。 -能reuse的线程,必须是timeout IDLE内的池中线程,缺省timeout是60s,超过这个IDLE时长,线程实例将被终止及移出池。 注意,放入CachedThreadPool的线程不必担心其结束,超过TIMEOUT不活动,其会自动被终止。 |
| newFixedThreadPool | -newFixedThreadPool与cacheThreadPool差不多,也是能reuse就用,但不能随时建新的线程 -其独特之处:任意时间点,最多只能有固定数目的活动线程存在,此时如果有新的线程要建立,只能放在另外的队列中等待,直到当前的线程中某个线程终止直接被移出池子 -和cacheThreadPool不同,FixedThreadPool没有IDLE机制(可能也有,但既然文档没提,肯定非常长,类似依赖上层的TCP或UDP IDLE机制之类的),所以FixedThreadPool多数针对一些很稳定很固定的正规并发线程,多用于服务器 -从方法的源代码看,cache池和fixed 池调用的是同一个底层池,只不过参数不同: fixed池线程数固定,并且是0秒IDLE(无IDLE) cache池线程数支持0-Integer.MAX_VALUE(显然完全没考虑主机的资源承受能力),60秒IDLE |
| ScheduledThreadPool | -调度型线程池 -这个池子里的线程可以按schedule依次delay执行,或周期执行 |
| SingleThreadExecutor | -单例线程,任意时间池中只能有一个线程 -用的是和cache池和fixed池相同的底层池,但线程数目是1-1,0秒IDLE(无IDLE) |
ScheduledThreadPool其实等于newFixedThreadPool(1);既固定线程池中只固定一个线程
newScheduledThreadPool
第四种要特殊一点,他可以实现线程执行的先后间隔及执行时间等,功能比上面的三个强大了一些。
ScheduledThreadPoolExecutor的定时方法主要有以下四种:
下面将主要来具体讲讲scheduleAtFixedRate和scheduleWithFixedDelay
scheduleAtFixedRate 按指定频率周期执行某个任务
间隔指的是连续两次任务开始执行的间隔。对于scheduleAtFixedRate方法,当执行任务的时间大于我们指定的间隔时间时,它并不会在指定间隔时开辟一个新的线程并发执行这个任务。而是等待该线程执行完毕。
public ScheduledFuture scheduleAtFixedRate(Runnable command,
long initialDelay,
long period,
TimeUnit unit);
command:执行线程
initialDelay:初始化延时
period:两次开始执行最小间隔时间
unit:计时单位
scheduleWithFixedDelay 周期定时执行某个任务/按指定频率间隔执行某个任务(注意)
间隔指的是连续上次执行完成和下次开始执行之间的间隔。
public ScheduledFuture scheduleWithFixedDelay(Runnable command,
long initialDelay,
long delay,
TimeUnit unit);
command:执行线程
initialDelay:初始化延时
period:前一次执行结束到下一次执行开始的间隔时间(间隔执行延迟时间)
unit:计时单位
常用示例
设置每天晚上9点执行
/**
* 每天晚上9点执行一次
* 每天定时安排任务进行执行
*/
public static void executeEightAtNightPerDay() {
ScheduledExecutorService executor = Executors.newScheduledThreadPool(1);
long oneDay = 24 * 60 * 60 * 1000;
long initDelay = getTimeMillis("21:00:00") - System.currentTimeMillis();
initDelay = initDelay > 0 ? initDelay : oneDay + initDelay;
executor.scheduleAtFixedRate(
new MyHandle(),
initDelay,
oneDay,
TimeUnit.MILLISECONDS);
}
/**
* 获取指定时间对应的毫秒数
* @param time "HH:mm:ss"
* @return
*/
private static long getTimeMillis(String time) {
try {
DateFormat dateFormat = new SimpleDateFormat("yy-MM-dd HH:mm:ss");
DateFormat dayFormat = new SimpleDateFormat("yy-MM-dd");
Date curDate = dateFormat.parse(dayFormat.format(new Date()) + " " + time);
return curDate.getTime();
} catch (ParseException e) {
e.printStackTrace();
}
return 0;
} submit和execute
submit有返回值,execute没有返回值
有关返回值的问题可以看Callable、Future、FutureTask、CompletionService学习总结
将线程放入线程池中,除了使用execute,也可以使用submit,它们两个的区别是一个使用有返回值,一个没有返回值。submit的方法很适应于生产者-消费者模式,通过和Future结合一起使用,可以起到如果线程没有返回结果,就阻塞当前线程等待线程 池结果返回。
它主要有三种方法:
一般用第一种比较多

示例
Future future = executorService.submit(new Task(i));
//Task类要实现Callable接口
这时就可以获取到call函数的返回值
System.out.println(future.get()); 再看submit的源码,其实还是调用的execute执行的
public Future submit(Callable task) {
if (task == null) throw new NullPointerException();
RunnableFuture ftask = newTaskFor(task);
execute(ftask);
return ftask;
} execute()
表示往线程池添加线程,有可能会立即运行,也有可能不会。无法预知线程何时开始,何时线束。
主要源码如下:
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
if (poolSize >= corePoolSize || !addIfUnderCorePoolSize(command)) {
if (runState == RUNNING && workQueue.offer(command)) {
if (runState != RUNNING || poolSize == 0)
ensureQueuedTaskHandled(command);
}
else if (!addIfUnderMaximumPoolSize(command))
reject(command); // is shutdown or saturated
}
}另外还有 shutdown()和shutdownNow()
shutdown()
通常放在execute后面。如果调用 了这个方法,一方面,表明当前线程池已不再接收新添加的线程,新添加的线程会被拒绝执行。另一方面,表明当所有线程执行完毕时,回收线程池的资源。注意,它不会马上关闭线程池!
shutdownNow()
不管当前有没有线程在执行,马上关闭线程池!这个方法要小心使用,要不可能会引起系统数据异常!
四、ThreadPoolExecutor技术内幕
经过上面的过程,基本上可以掌握线程池的一些基本用法。下面再来看看JAVA中线程池的源码实现。
首先是其继承关系如下:
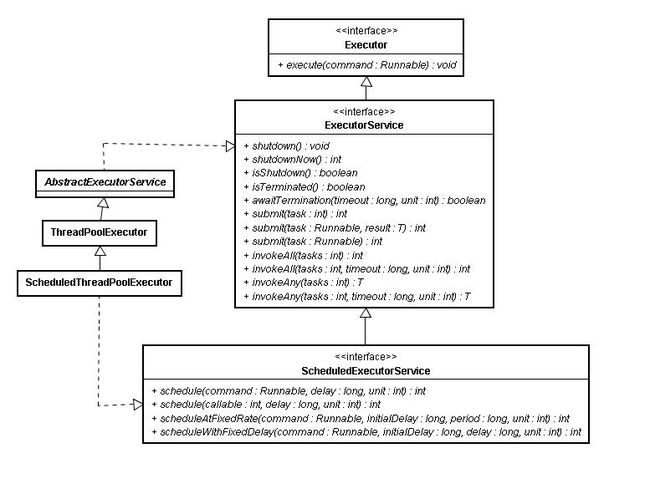
构造函数
通过观察上面四种线程池的源码:
如:newFixedThreadPool
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue());
}
如:newCachedThreadPool
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue());
}
如:newSingleThreadExecutor
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue()));
}
可以发现,其实它们调用的都是同一个接口ThreadPoolExecutor方法,只不过传入参数不一样而已。下面就来看看这个神秘的
public ThreadPoolExecutor(int corePoolSize,//核心线程大小
int maximumPoolSize,//最大线程大小
long keepAliveTime,//线程缓存时间
TimeUnit unit,//前面keepAlive
BlockingQueue workQueue,//缓存队列
ThreadFactory threadFactory,//线程工大
RejectedExecutionHandler handler)//拒绝策略 ThreadPoolExecutor。
首先来看看它的一些基本参数:
public class ThreadPoolExecutor extends AbstractExecutorService {
//运行状态标志位
volatile int runState;
static final int RUNNING = 0;
static final int SHUTDOWN = 1;
static final int STOP = 2;
static final int TERMINATED = 3;
//线程缓冲队列,当线程池线程运行超过一定线程时并满足一定的条件,待运行的线程会放入到这个队列
private final BlockingQueue workQueue;
//重入锁,更新核心线程池大小、最大线程池大小时要加锁
private final ReentrantLock mainLock = new ReentrantLock();
//重入锁状态
private final Condition termination = mainLock.newCondition();
//工作都set集合
private final HashSet workers = new HashSet();
//线程执行完成后在线程池中的缓存时间
private volatile long keepAliveTime;
//核心线程池大小
private volatile int corePoolSize;
//最大线程池大小
private volatile int maximumPoolSize;
//当前线程池在运行线程大小
private volatile int poolSize;
//当缓冲队列也放不下线程时的拒绝策略
private volatile RejectedExecutionHandler handler;
//线程工厂,用来创建线程
private volatile ThreadFactory threadFactory;
//用来记录线程池中曾经出现过的最大线程数
private int largestPoolSize;
//用来记录已经执行完毕的任务个数
private long completedTaskCount;
................
}
初始化线程池大小 有以下四种方法:
从源码中可以看到其实最终都是调用了以下的方法:
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}
这里很简单,就是设置一下各个参数,并校验参数是否正确,然后抛出对应的异常。
并且各个模式都是通过不同参数进行区别的,如固定线程池的最小最大都是一样的,并且没有keepAliveTime既代表永久,而缓存型则是通过最小为0,最大为int的最大值,设置keepAliveTime为60秒
再来看看execute函数
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
if (poolSize >= corePoolSize || !addIfUnderCorePoolSize(command)) { // 判断1
if (runState == RUNNING && workQueue.offer(command)) { // 判断2
if (runState != RUNNING || poolSize == 0) // 判断3
ensureQueuedTaskHandled(command);
}
else if (!addIfUnderMaximumPoolSize(command)) // 判断4
reject(command); // is shutdown or saturated
}
}总结一下便是
if(当前线程数>=核心线程数||!添加任务给新的线程){
if(线程池在运行&&将任务加入到缓存队列中){
if(线程池没有运行||运行的线程为0){
执行拒绝策略
}
}else if(尝试再启动下该线程){
执行拒绝策略
}
}其中添加任务给新的线程为addIfUnderCorePoolSize方法
private boolean addIfUnderCorePoolSize(Runnable firstTask) {
Thread t = null;
final ReentrantLock mainLock = this.mainLock;//加锁
mainLock.lock();
try {
if (poolSize < corePoolSize && runState == RUNNING)//线程池在运行且当前线程小于核心线程(外面已做了一次相同的判断,确保和外面的一样)
t = addThread(firstTask);//加入线程
} finally {
mainLock.unlock();
}
return t != null;
}添加任务给一个新创建的线程,成功返回true,失败返回false
使用的addThread(Runnable )方法新建线程
private Thread addThread(Runnable firstTask) { //调用这个方法之前加锁
Worker w = new Worker(firstTask);//线程包装成一个work
Thread t = threadFactory.newThread(w);//线程工厂从work创建线程
boolean workerStarted = false;
if (t != null) {
if (t.isAlive()) // 线程应该是未激活状态
throw new IllegalThreadStateException();
w.thread = t;
workers.add(w);//全局set添加一个work
int nt = ++poolSize;//当前运行线程数目加1
if (nt > largestPoolSize)
largestPoolSize = nt;
try {
t.start();//注意,这里线程执行了,但是其实真正调用的是Worker类的run方法!!!!!!!!!
workerStarted = true;
}
finally {
if (!workerStarted)
workers.remove(w);
}
}
return t;
}里面使用的线程池的线程工厂进行新建,并且完成当前线程数加一和更新最大线程数的工作。
其他源码
private boolean addIfUnderMaximumPoolSize(Runnable firstTask) {
Thread t = null;
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
if (poolSize < maximumPoolSize && runState == RUNNING) //如果当前运行线程数目 小于最大线程池大小 并且 线程池在运行,那么启动该线程
t = addThread(firstTask);
} finally {
mainLock.unlock();
}
return t != null;
}一般调用这个方法是发生在缓冲队列已满了,那么线程池会尝试直接启动该线程。当然,它要保存当前运行的poolSize一定要小于maximumPoolSize。否则,最后。还是会拒绝这个线程!
private void ensureQueuedTaskHandled(Runnable command) {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
boolean reject = false;
Thread t = null;
try {
int state = runState;
if (state != RUNNING && workQueue.remove(command)) //线程池没有在运行,且缓冲队列中有这个线程
reject = true;
else if (state < STOP &&
poolSize < Math.max(corePoolSize, 1) &&
!workQueue.isEmpty())
t = addThread(null);
} finally {
mainLock.unlock();
}
if (reject)
reject(command); //根据拒绝策略处理线程
}拒绝策略根据创建线程池的选择来拒绝
总结:
ThreadPoolExecutor中,包含了一个任务缓存队列和若干个执行线程,任务缓存队列是一个大小固定的缓冲区队列,用来缓存待执行的任务,执行线程用来处理待执行的任务。每个待执行的任务,都必须实现Runnable接口,执行线程调用其run()方法,完成相应任务。
ThreadPoolExecutor对象初始化时,不创建任何执行线程,当有新任务进来时,才会创建执行线程。
构造ThreadPoolExecutor对象时,需要配置该对象的核心线程池大小和最大线程池大小:
当目前执行线程的总数小于核心线程大小时,所有新加入的任务,都在新线程中处理
当目前执行线程的总数大于或等于核心线程时,所有新加入的任务,都放入任务缓存队列中
当目前执行线程的总数大于或等于核心线程,并且缓存队列已满,同时此时线程总数小于线程池的最大大小,那么创建新线程,加入线程池中,协助处理新的任务。
当所有线程都在执行,线程池大小已经达到上限,并且缓存队列已满时,就rejectHandler拒绝新的任务
几种block queue策略
ArrayBlockingQueue : 有界的数组队列
LinkedBlockingQueue : 可支持有界/无界的队列,使用链表实现
PriorityBlockingQueue : 优先队列,可以针对任务排序
SynchronousQueue : 队列长度为1的队列,和Array有点区别就是:client thread提交到block queue会是一个阻塞过程,直到有一个worker thread连接上来poll task。拒绝策略
当线程池的任务缓存队列已满并且线程池中的线程数目达到maximumPoolSize,如果还有任务到来就会采取任务拒绝策略,通常有以下四种策略
ThreadPoolExecutor.AbortPolicy:丢弃任务并抛出RejectedExecutionException异常。
ThreadPoolExecutor.DiscardPolicy:也是丢弃任务,但是不抛出异常。
ThreadPoolExecutor.DiscardOldestPolicy:丢弃队列最前面的任务,然后重新尝试执行任务(重复此过程)
ThreadPoolExecutor.CallerRunsPolicy:由调用线程处理该任务示例
定义一个线程池,为第三者拒绝策略
核心线程数为2,最大线程数为4,线程缓存时间为3秒,缓冲队列的容量设置为3。线程工厂设置为默认
ThreadPoolExecutor threadPool = new ThreadPoolExecutor(2, 4, 3,TimeUnit.SECONDS, new ArrayBlockingQueue(3),Executors.defaultThreadFactory(),new ThreadPoolExecutor.DiscardOldestPolicy()); package com.func.axc.executors;
import java.io.Serializable;
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.Executors;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
/**
* 功能概要:
*
* @author linbingwen
* @since 2016年6月7日
*/
public class MyThreadPoolTest {
private static int produceTaskSleepTime = 2;
private static int produceTaskMaxNumber = 10;
public static void main(String[] args) {
// 构造一个线程池
ThreadPoolExecutor threadPool = new ThreadPoolExecutor(2, 4, 3,TimeUnit.SECONDS, new ArrayBlockingQueue(3),Executors.defaultThreadFactory(),new ThreadPoolExecutor.DiscardOldestPolicy());
for (int i = 1; i <= produceTaskMaxNumber; i++) {
try {
// 产生一个任务,并将其加入到线程池
String task = "task@ " + i;
System.out.println("put " + task);
threadPool.execute(new ThreadPoolTask(task));
// 便于观察,等待一段时间
Thread.sleep(produceTaskSleepTime);
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
/**
* 线程池执行的任务
*/
class ThreadPoolTask implements Runnable, Serializable {
private static final long serialVersionUID = 0;
private static int consumeTaskSleepTime = 2000;
// 保存任务所需要的数据
private Object threadPoolTaskData;
ThreadPoolTask(Object tasks) {
this.threadPoolTaskData = tasks;
}
public void run() {
// 处理一个任务,这里的处理方式太简单了,仅仅是一个打印语句
System.out.println(Thread.currentThread().getName());
System.out.println("start .." + threadPoolTaskData);
try {
// //便于观察,等待一段时间
Thread.sleep(consumeTaskSleepTime);
} catch (Exception e) {
e.printStackTrace();
}
threadPoolTaskData = null;
}
public Object getTask() {
return this.threadPoolTaskData;
}
} 执行结果
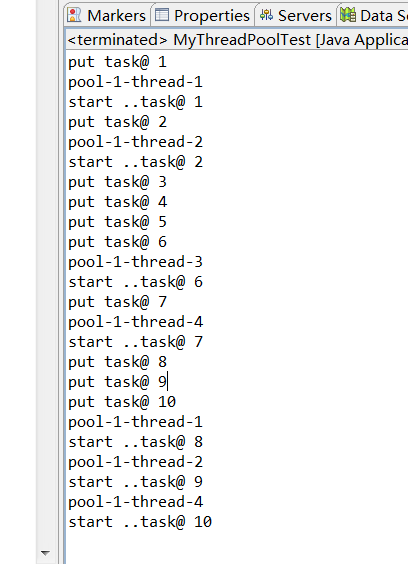
可以看出有几个任务是被丢弃了的