申请评分卡模型数据预处理
一、获取数据
2.1 数据获取
数据的获取途径主要有两个:
- 金融机构自身字段:例用户的年龄,户籍,性别,收入,负债比,在本机构的借款和还款行为等;
- 第三方机构的数据:如用户在其他机构的借贷行为,用户的消费行为数据等。
申请评分卡常用的特征
- 个人信息: 学历、 性别、 收入
- 负债信息: 在本金融机构或者其他金融机构负债情况
- 消费能力: 商品购买纪录、出境游、奢侈品消费
- 历史信用记录: 历史逾期行为
- 新兴数据: 人际社交、 网络足迹、 出行 、个人财务
每一行代表一个样本(一笔成功成交借款),每个样本包含228多个各类字段
本项目一共三个表,下面分别介绍各个表的重要特征字段
Master
Idx: 每一笔贷款的unique key,可以与另外2个文件里的idx相匹配。
UserInfo_: 借款人个人基础信息,例如学历,性别等
WeblogInfo_ : Weblog网络行为相关信息
Education_Info*: 学历学籍相关信息字段
ThirdParty_Info_PeriodN_* : 第三方数据时间段N字段
SocialNetwork_* : 社交网络字段
LinstingInfo : 借款成交时间
Target: 违约标签(1 = 贷款违约,0 = 正常还款)
Log_Info:借款人登录信息
idx: 每一笔贷款的unique key
ListingInfo : 借款成交时间
LogInfo1 : 操作代码
LogInfo2: 操作类别
LogInfo3: 登陆时间
Userupdate_Info:借款人修改的字段信息
idx: 每一笔贷款的unique key
ListingInfo1 : 借款成交时间
UserupdateInfo1: 修改内容
UserupdateInfo2 : 修改时间
2.2 EDA(探索性数据分析)
该步骤主要是获取数据的大概情况,例如每个字段的缺失值情况、异常值情况、平均值、中位数、最大值、最小值、分布情况等。以便制定合理的数据预处理方案。
2.3 数据预处理
数据预处理主要包括数据清洗,变量分箱和 WOE 编码三个步骤。
2.3.1 数据清洗
数据清洗主要是对原始数据中脏数据,缺失值,异常值进行处理。
1.关于对缺失值和异常值的处理
我们采用的方法非常简单粗暴,即删除缺失率超过某一阈值(阈值自行设定,可以为30%,50%,90%等)的变量,将剩余变量中的缺失值和异常值作为一种状态 。
类别变量:将缺失作为一种状态
对于连续变量:缺失率超过30%,删除
或者:
利用随机抽样法填补
剔除极端值后用均值填补
在评分卡模型中,连续变量中的缺失值也可以作为一种状态
2.3.2 特征的分箱
2.3.2.1分箱的定义
将连续变量离散化,将多状态的离散变量合并成少量状态
比如手机号这个特征,每个人的手机号都是不同的,如果有500条数据,就有500个手机号,如果将这500个特征值都输入模型,那么这个时间开销是非常大的。
2.3.2.2分箱的重要性
为什么原本就是连续型的数据,要进行分箱操作,使之变成离散变量?
主要是因为可能会出现以下情况:
Q:客户工资有小范围上涨,对模型的影响?
一般一个评分卡模型的有效持续时间是 1个月左右甚至更长时间,中间也许会有一些客户的数据发生变化,比如一个月之内工资上涨,但是只上涨了100元,客户的工资有1万块,变成1.01万块,实际上对于是否能及时还款并没有多大影响,但是却会导致模型的准确度等发生变化,而这样的波动是没有意义的。
假设我们将工资特征划分为5箱,即<3000, 3000-5000, 5000-8000, 8000-12000, >12000。客户工资从10000→10100,依然在8000-12000中。这样在考虑客户工资变化的前提下,不会因为客户工资的发生变化而变成了另外一个人,保证了模型的稳定性。
Q:如果出现缺失值,也不需要费心思去填补空缺。
让缺失值单独分为一箱。
Q:年龄变量中出现“500岁”这种异常字段该怎样处理?
对于年龄特征我们划分为4段,即18-25, 25-35, 35-55, > 55,我们可以直接把500划分到>55这一个分箱中。另外我们也可以通过一些手段检测出异常值,将异常值单独分为一箱。
总结一下特征分箱的优势:
- 特征分箱可以有效处理特征中的缺失值和异常值。
- 特征分箱后,数据和模型会更稳定,避免你了无意义的波动对评分带来的波动。
- 特征分箱可以简化逻辑回归模型,降低模型过拟合的风险,提高模型的泛化能力。
- 将所有特征统一变换为类别型变量。
- 分箱后变量才可以使用标准的评分卡格式,即对不同的分段进行评分。
- 分箱后避免了极端值的影响,增强了模型的健壮性。
2.3.2.3常见的分箱方法
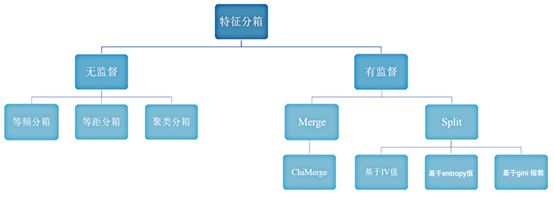
(1)无监督分箱
无监督的分箱主要包括以下几类:
- 等频分箱:把自变量按从小到大的顺序排列,根据自变量的个数等分为k部分,每部分作为一个分箱。
- 等距分箱:把自变量按从小到大的顺序排列,将自变量的取值范围分为k个等距的区间,每个区间作为一个分箱。
- 聚类分箱:用k-means聚类法将自变量聚为k类,但在聚类过程中需要保证分箱的有序性。
由于无监督分箱仅仅考虑了各个变量自身的数据结构,并没有考虑自变量与目标变量之间的关系,因此无监督分箱不一定会带来模型性能的提升。
(2)有监督分箱
包括 Split 分箱和 Merge 分箱
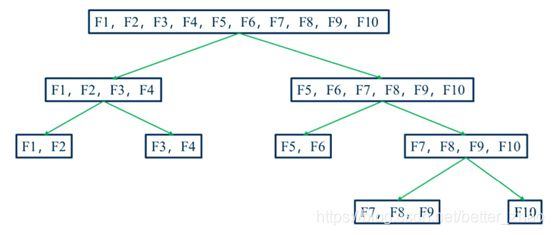
·Split 分箱是一种自上而下(即基于分裂)的数据分段方法。如下图所示,Split 分箱和决策树比较相似,切分点的选择指标主要有 entropy,gini 指数和 IV 值等。
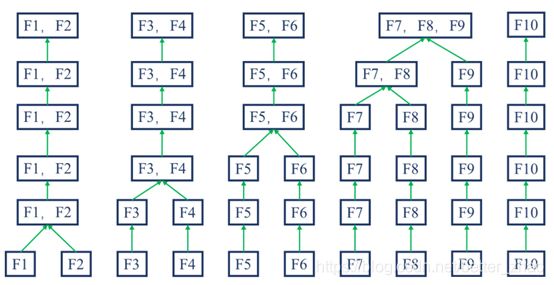
·Merge 分箱,是一种自底向上(即基于合并)的数据离散化方法。如下图所示为Merge 分箱的示意图,
Merge 分箱方法一:Best KS

Merge 分箱方法二:Chimerge
Chimerge 分箱是目前最流行的分箱方式之一
// 基本思想:
如果两个相邻的区间具有类似的类分布,则这两个区间合并;否则,它们应保持分开。Chimerge通常采用卡方值来衡量两相邻区间的类分布情况。
// 具体算法:
step1:预先设定一个卡方的阈值或者最小分箱数n
step2:初始化
1)连续值按升序排列,离散值先转化为坏客户的比率,然后再按升序排列;
2)为了减少计算量,对于状态数大于某一阈值 (建议为100) 的变量,利用等频分箱进行粗分箱。
3)若有缺失值,则缺失值单独作为一个分箱。
step3:合并区间
1)计算每一对相邻区间的卡方值;
2)将卡方值最小的一对区间合并;
step4:重复以上两个步骤,直到分箱数量不大于n,或者各个箱内阈值不小于初始设定的阈值。
step5:输出:分箱后的数据和分箱区间。
// 卡方阈值的确定:
根据显著性水平和自由度得到卡方值
自由度比类别数量小1。例如,有3类,自由度为2,则90%置信度(10%显著性水平)下,
卡方的值为4.6。
// 阈值的意义:
类别和属性独立时,有90%的可能性,计算得到的卡方值会小于4.6,这样,大于阈值的卡
方值就说明属性和类不是相互独立的,不能合并。如果阈值选的大,区间合并就会
进行很多次,离散后的区间数量少、区间大。
注:
1,ChiMerge算法推荐使用0.90、0.95、0.99置信度,最大区间数取10到15之间。
2,也可以不考虑卡方阈值,此时可以考虑最小区间数或者最大区间数。指定区间数量的 上限和下限,最多几个区间,最少几个区间。
3,对于类别型变量,需要分箱时需要按照某种方式进行排序 4,对于分箱后某一箱样本占比超过 95% 的箱子进行删除。
5,检查缺失分箱的坏客户比例是否和非缺失分箱相等,如果相等,进行合并 6,一个分箱内不能全为好客户或者全为坏客户
2.3.3 WOE编码
分箱之后我们便得到了一系列的离散变量,下面需要对变量进行编码,将离散变量转化为连续变量。WOE编码是评分卡模型常用的编码方式。
定义:
WOE 称为证据权重(weight of evidence),是一种有监督的编码方式,将预测类别的集中度的属性作为编码的数值。
优势:
- 将特征的值规范到相近的尺度上(经验上,WOE的绝对值波动范围在0.1~3之间);
- 能有体现具体业务含义
缺点:
每个分箱中要同时包含好坏两种类别的样本
对于第 i个箱子的WOE值为:
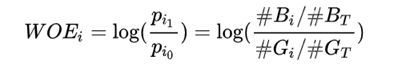

公式中的 log函数的底一般取为e,即为ln
从以上公式中我们可以发现,WOE表示的实际上是“当前分箱中坏客户占所有坏客户的比例”和“当前分箱中好客户占所有好客户的比例”的差异。
对以上公式做一个简单变换,可以得到:
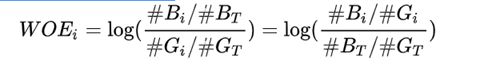
变换以后可以看出,WOE也可以理解为当前分箱中坏客户和好客户的比值,和所有样本中这个比值的差异 (也就是我们随机的坏客户和好客户的比例)。
WOE越大,这种差异越大,当前分组里的坏客户的可能性就越大,WOE越小,差异越小,
这个分组里的样本响应的可能性就越小。当分箱中坏客户和好客户的比例等于随机坏客户和好客户的比值时,说明这个分箱没有预测能力,即WOE=0。
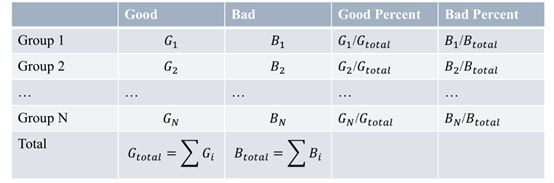
WOE具体计算过程如下表所示:
Q:为什么选择采用WOE编码,而不用其他的one-hot编码方式呢?
one-hot 编码会将原始变量中的每个状态都做为作为一个新的特征,当原始特征状态较多时,数据经过one-hot编码之后特征数量会成倍的增加,同时新特征也会变得过于稀疏。在进行变量筛选的过程中,也会出现原始特征的一部分状态被筛选出来,另一部分状态未被筛选出来,造成特征的不完整。
总结一下WOE编码的优势:
1)可提升模型的预测效果
2)将自变量规范到同一尺度上
3)WOE能反映自变量取值的贡献情况
4)有利于对变量的每个分箱进行评分
5)转化为连续变量之后,便于分析变量与变量之间的相关性
6)与独热向量编码相比,可以保证变量的完整性,同时避免稀疏矩阵和维度灾难