Spark入门单机版安装和操作本地和HDFS文件
一、Spark单机版安装
Spark部署模式主要是四种:Local模式(单机模式,是本文讲的方式,仅供熟悉Spark和scala入门用)、Standalone模式(使用Spark自带的简单集群管理器,计算数据不是特别庞大)、YARN模式(使用YARN作为集群管理器,配合hadoop集群使用)和Mesos模式(使用Mesos作为集群管理器,配合docker)。
1.1、Spark的基础环境
Spark和Hadoop可以部署在一起,相互协作,由Hadoop、Hbase等组件负责数据的存储和管理,由Spark负责数据的计算。Spark和Hadoop都可以安装在windows和linux系统的计算机上,但还是推荐Linux中安装和使用。(由于Hadoop单机版教程很多,就不在这赘述)。
Spark最新版2.4运行在Java 8 +,Python 2.7 + / 3.4 +和R 3.1+上。对于Scala API,Spark 2.4.0使用Scala 2.11。您需要使用兼容的Scala版本(2.11.x)。
请注意,自Spark 2.2.0起,对2.6.5之前的Java 7,Python 2.6和旧Hadoop版本的支持已被删除。自2.3.0起,对Scala 2.10的支持被删除。
我的环境:
Linux:centeros6.5
JDK:1.8.45
Hadoop:hadoop-2.6.0-cdh5.12.2
Spark:spark-2.4.0-bin-hadoop2.6(apache)
下面简单说一下spark版本,spark和hadoop一样有apache版(地址:http://spark.apache.org/downloads.html)和cdh这两个常用版本(其余版本就不再赘述了),但cdh版本现在适配都是Spark1.6版本(地址:http://archive.cloudera.com/cdh5/cdh/5/),Spark2.0以上版本支持cdh版本hadoop有限(地址:http://archive.cloudera.com/spark2/),没有完全适配我的cdh版本,就选择了apache版本。
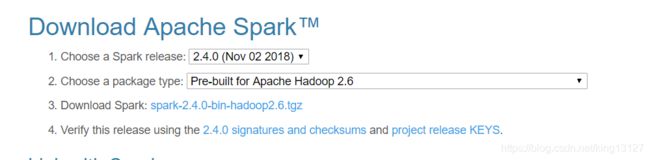
由于我安装hadoop版本是hadoop-2.6.0-cdh5.12.2,直接下载了apache版Spark,如上图,选择适配hadoop2.6通版就可以了。
1.2、Spark的安装
[root@hadoop001 home]# tar -zxvf /home/spark-2.4.0-bin-hadoop2.6.tgz -C /usr/local
[root@hadoop001 home]# cd /usr/local/spark-2.4.0-bin-hadoop2.6/conf/
[root@hadoop001 conf]# cp spark-env.sh.template spark-env.sh
修改配置文件 vim /usr/local/spark-2.4.0-bin-hadoop2.6/conf/spark-env.sh
添加 export SPARK_DIST_CLASSPATH=$(/home/hadoop/hadoop-2.6.0-cdh5.12.2/bin/hadoop classpath)
上面路径为安装的hadoop路径。
测试是否安装成功:
[root@hadoop001 spark]# cd /usr/local/spark-2.4.0-bin-hadoop2.6/
[root@hadoop001 spark]# bin/run-example SparkPi 2>&1 | grep "Pi is roughly"
Pi is roughly 3.1383556917784587说明已经安装成功了。
二、Spark启动和读取文件
[root@hadoop001 spark]# cd /usr/local/spark-2.4.0-bin-hadoop2.6/
[root@hadoop001 spark]# ./bin/spark-shell
2019-01-18 02:28:46 WARN NativeCodeLoader:62 - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at http://hadoop001:4040
Spark context available as 'sc' (master = local[*], app id = local-1547749742799).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.4.0
/_/
Using Scala version 2.11.12 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_131)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
进入这个页面证明启动成功了。
下面读取一个本地文件,并统计文件行数:
scala> val testFile=sc.textFile("file:///home/input/testfile")
testFile: org.apache.spark.rdd.RDD[String] = file:///home/input/testfile MapPartitionsRDD[1] at textFile at :24
scala> testFile.count()
res0: Long = 3 下面读取一个HDFS文件,并统计文件行数:
scala> val testFile=sc.textFile("hdfs://hadoop001:8020/test/testfile")
testFile: org.apache.spark.rdd.RDD[String] = hdfs://hadoop001:8020/test/testfile MapPartitionsRDD[3] at textFile at :24
scala> testFile.count()
res1: Long = 3