【技术硬核】庖丁解牛 | PostgreSQL与NewSQL大解析(四)
通过上文我们可以知道,NewSQL的优势在于SQL的支持能力、扩展性、实时性和事务的处理能力。在NewSQL蓬勃发展的前提下,许多新兴技术公司开始打造自己的新一代分布式数据库,其设计理念:
一、分布式架构
通过主节点下发任务的模式,每个节点都可以提供服务,在扩展性上,Master不会是瓶颈。
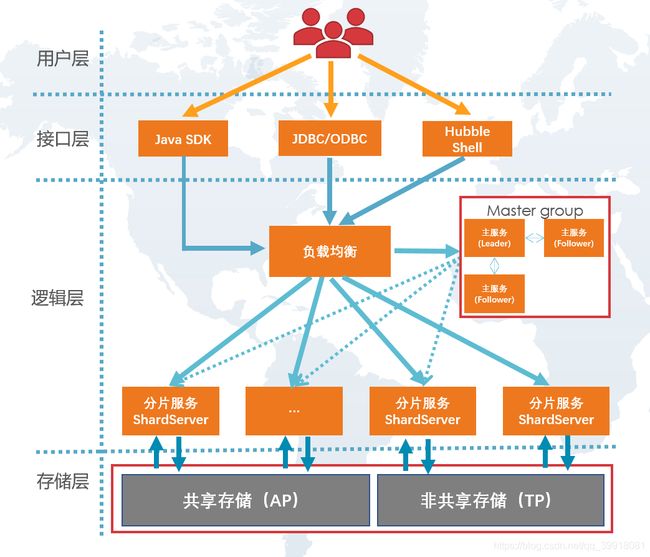
1、客户端通过不同的接口访问形式,直接访问主服务节点服务
2、主服务节点收到服务请求进行分析处理,分配到不同的分配服务节点执行
3、分片服务节点收到执行请求,进行sql解析处理并执行SQL计划
4、SQL执行服务底层存储数据进行处理访问,并反回处理结果
5、通过Raft协议确保服务之间数据同步
6、存储根据AP、TP分为共享存储和非共享存储
而与之相比较,PostgreSQL现在的分布式都是MPP的架构,share nothing,存在增加、减少节点数据重新分配的问题。
二、从分库分表走向Sharding与Partition(分片与分区)
通过我们前面对PostgreSQL的解读,数据分库分表是一种被迫的选择,无奈之举,如果能够不做分库分表,就尽量不要做这方面的设计,因为会对业务提出要求,或者改动业务。所以,我们在NewSQL的设计上,要多做Sharding与Partition(分片与分区)的设计。
数据分区
分区就是把一张表的数据分成N个区块,在逻辑上看最终只是一张表,但底层是由N个物理区块组成的。
什么时候考虑使用分区呢?当一张表的查询速度已经慢到影响使用的时候,数据量大,sql经过优化,表中的数据是分段的,或者对数据的操作往往只涉及一部分数据,而不是所有的数据。
分区解决的问题主要是可以提升查询效率。

数据分片
在分布式存储系统中,数据需要分散存储在多台设备上,数据分片(Sharding)就是用来确定数据在多台存储设备上分布的技术。数据分片要达到三个目的:
01、分布均匀,即每台设备上的数据量要尽可能相近;
02、负载均衡,即每台设备上的请求量要尽可能相近;
03、扩缩容时产生的数据迁移尽可能少。
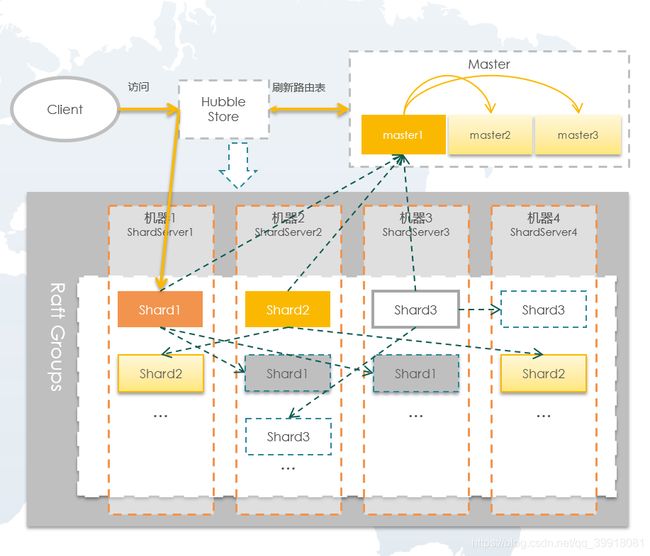
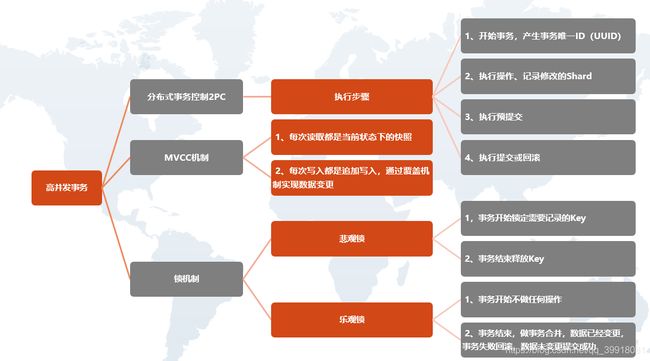
三、数据同步与一致性Raft / Paxos
目前主流的NewSQL数据库的数据同步是基于Raft协议的。

在Raft中三种角色
Leader :负责接收客户端的请求,将日志复制到其他节点并告知其他节点何时应用这些日志是安全的
Candidate:用于选举Leader的一种角色
Follower:负责响应来自Leader或者Candidate的请求
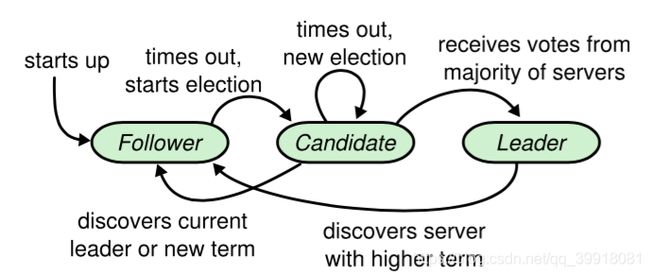
所有节点初始状态都是Follower角色
超时时间内没有收到Leader的请求则转换为Candidate进行选举
Candidate收到大多数节点的选票则转换为Leader;发现Leader或者收到更高任期的请求则转换为Follower
Leader在收到更高任期的请求后转换为Follower
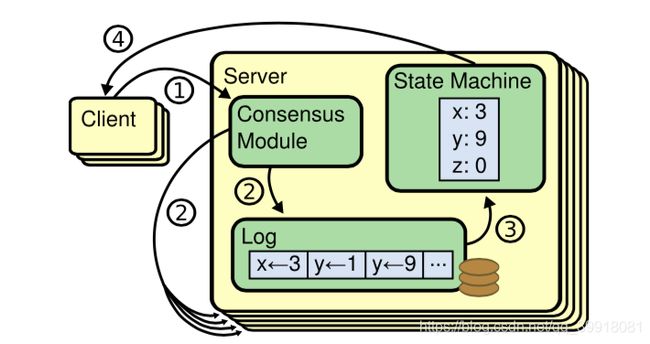
Raft状态机
所有一致性算法都会涉及到状态机,而状态机保证系统从一个一致的状态开始;
以相同的顺序执行一些列指令最终会达到另一个一致的状态;
所有的节点以相同的顺序处理日志,那么最终x、y、z的值在多个节点中都是一致的。
在这一点上,PostgreSQL-X2的架构是以主备的模式来确定的。
四、分布式事务
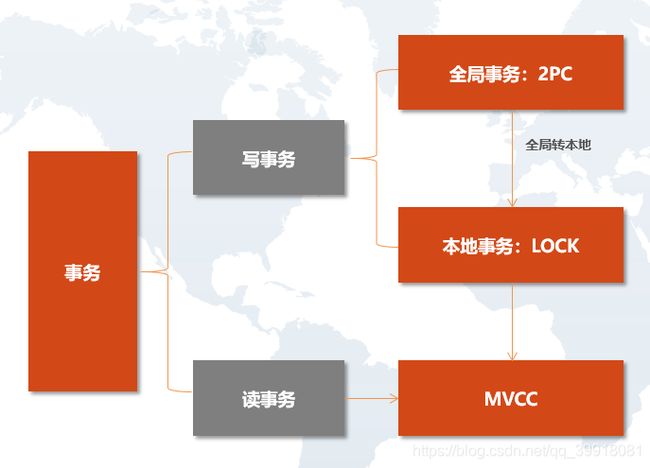
事务开始,记录事务唯一ID,执行操作,记录修改的shard,执行预提交动作,提交或回滚
写入时当前采用锁机制
读取使用快照读取,存储层每次写入都是追加写入,通过覆盖机制进行数据变更
这样的好处是,数据的鲜活性可以实时保证,数据更新插入和分析可以一起完成,像实时数仓、实时统计汇总计算就能够实现了。而在PostgreSQL的OLAP虽然可以通过批量或者插入的方式实现更新,但要人工做优化,持续投入人力干预,性能被动式保证。
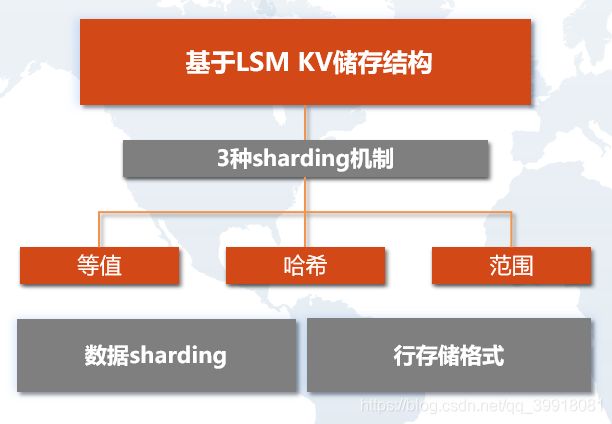
五、存储层 —— Kv存储
在存储方面,我们有两种选择:
堆存:数据可以通过key获取,同时可以直接读取数据
非堆存:数据只能通过key来获取,无法直接读取到数据
非堆存储只能通过key来获取数据,会导致不断的离散的读取,所以不能适应于AP的场景。
· 客户端通过不同的接口访问形式,直接访问主服务节点服务
· 主服务节点收到服务请求进行分析处理,分配到不同的分配服务节点执行
· 分片服务节点收到执行请求,进行sql解析处理并执行SQL计划
· SQL执行服务底层存储数据进行处理访问,并反回处理结果
· Zookeeper保证相关服务应用的高可用
· HDFS持久化底层存储数据,并利用三副本技术保证数据不丢失
与之相比较,PostgreSQL是本地化存储,存储也可以分为列存和行存等。
六、多源异构与数据邦联
NewSQL的数据多源异构,要兼顾考虑对过去数据库的全面支持,尤其是NoSQL和Hadoop生态体系,因为毕竟这两者已经非常普及。

在多源异构方面,PostgreSQL是通过FDW支持多源异构,可访问Oracle、PG、MySQL、MongoDB等,对Hadoop体系和NoSQL支持力度低,效率和性能也较难做到极致。