利用pyecharts库对京津冀上广深空气质量数据进行可视化
本文以当前热门编程语言Python作为开发工具,利用Python的BeautifulSoup库进行网页爬虫以获取空气质量数据(AQI、PM2.5),然后综合运用第三方库Pandas进行数据处理,最后利用Python的pyecharts库对空气质量数据进行可视化图形的呈现,该设计具体实现了京津冀上广深空气质量数据的爬取、处理以及图形的输出。
本文将简单介绍整个流程,重点介绍可视化部分。
目录
-
- 1 数据获取
-
- 1.1 网页爬取
- 1.2 数据存储
- 1.3 数据处理
- 2 数据可视化
-
- 2.1 数据可视化步骤
-
- 2.1.1 导入相关包或类库
- 2.1.2 读取京津冀上广深六个城市的.csv文件
- 2.1.3 获取文件中所需要的信息
- 2.1.4 统计月均PM2.5
- 2.1.5 设置横纵坐标
- 2.1.6 添加标题
- 2.1.7 添加相关数据
- 2.1.8 在根目录下生成.html文件
- 2.2 数据可视化结果
- 3 地图可视化
-
- 3.1 导入相关地图库
- 3.2 导入地址和相应的PM2.5数据
- 3.3 设置地图名字以及画布大小
- 3.4 设置可视化点的大小和动态效果以及颜色条显示范围
- 3.5 生成.html格式的文件
- 3.6 可视化地图结果
1 数据获取
选取天气后报网,进行相关数据的爬取。该网页最大的优点是可以查询历史数据,天气数据种类丰富,数据清楚,包含的城市甚至城镇都较为全面,方便查询所需要的数据。其中,历史天气中可以查询每日的天气状况和气温等;空气质量可以查询AQI和PM2.5的历史数据和空气质量等级,很方便 大家日常生活中的读取,数据清晰简洁。
1.1 网页爬取
利用BeautifulSoup解析器解析URL(互联网上的每个文件都有唯一的URL)包含的文本信息,分析网页HTML文本和页面的设置规则,导入相关库
抓取目标数据,获取需要的数据信息:日期、质量等级、AQI指数、PM2.5等
1.2 数据存储
将所获取的数据信息组合生成.csv文件格式,最终实现结果是抓取到的数据信息形成了一个二维表,方便后面进行数据处理
1.3 数据处理
导入Numpy包,用于进行科学计算,包括了一个强大的N维数组对象Array,并且拥有成熟的函数库,比如矩阵数据类型和矢量处理
导入Pandas数据分析包,它包含了许多高级数据结构和操作工具,能够使得数据分析更加容易与快捷
2 数据可视化
2.1 数据可视化步骤
2.1.1 导入相关包或类库
import numpy as np
import pandas as pd
from pyecharts import Line2.1.2 读取京津冀上广深六个城市的.csv文件
citys=['beijing','tianjin','shijiazhuang','shanghai','guangzhou','shenzhen']
v=[]
for i in range(6):
filename=citys[i]+'_2018.csv'
df=pd.read_csv(filename,header=None,names=["Date","Quality_grade","AQI","AQI_rank","PM"])2.1.3 获取文件中所需要的信息
dom=df[['Date','PM']]
list1=[]
for j in dom['Date']:
time=j.split('-')[1]
list1.append(time)
df['month']=list1注:
1、split()方法通过指定分隔符对字符串进行切片。time=j.split(’-’)[1]表示以’-'为分隔符,并取序列为1的项
2、list.append(obj)表示在列表末尾添加新的对象
2.1.4 统计月均PM2.5
month_message=df.groupby(['month'])
month_com=month_message['PM'].agg(['mean'])
month_com.reset_index(inplace=True)
month_com_last=month_com.sort_index()注:
1、groupby是pandas中的一个分组函数,对原DataFrame进行打包分组。df.groupby([‘month’])表示按照月份进行分组
2、DataFrame对象groupby.agg方法为聚合(其操作包括max、min、std、sum、count)month_message[‘AQI’].agg([‘mean’])表示根据Dataframe的列’AQI’进行划分,再进行均值聚合操作
3、pandas中inplace参数为True,表示不创建新的对象,直接对原始对象进行修改
4、reset_index表示还原索引,变为默认的整型索引
5、month_com.sort_index()方法表示按month_com的行索引进行排序
2.1.5 设置横纵坐标
v1=np.array(month_com_last['mean'])
v1=["{}".format(int(i)) for i in v1]
v.append(v1)
attr = ["{}".format(str(i) + '月') for i in range(1, 13)]2.1.6 添加标题
line=Line("2018年京津冀上广深PM2.5全年走势图",title_pos='center',title_top='0',width=800,height=400)2.1.7 添加相关数据
line.add("北京",attr,v[0],line_color='red',legend_top='8%')
line._option['series'][0]['itemStyle']={
'color': 'red'}其余,天津、石家庄、上海、广州、深圳五个城市的说明与北京类似,只是将线条颜色依次改为’green’、‘pink’、‘purple’、‘blue’、‘orange’
2.1.8 在根目录下生成.html文件
line.render("2018年京津冀上广深PM2.5全年走势图.html")注:pyecharts的一些基本操作
1、add()主要方法,用于添加图表的数据和设置各种配置项
2、render()默认将会在根目录下生成一个 .html 的文件
2.2 数据可视化结果
pyecharts是一个用于生成Echarts图表的类库,包含了很多的图表类型,而Echarts是开源的一个数据可视化JS库,主要用于数据可视化,拥有良好的交互性和精巧的图表设计
gif格式
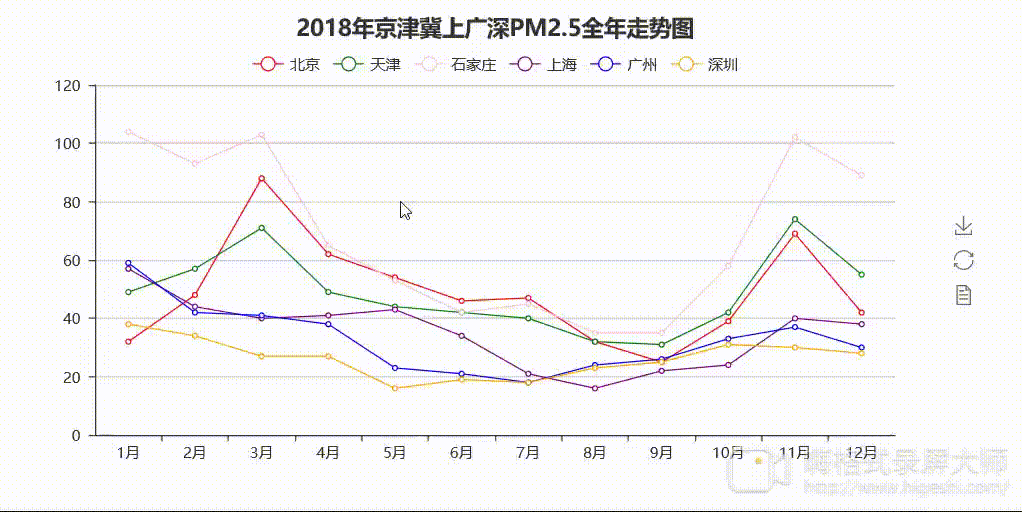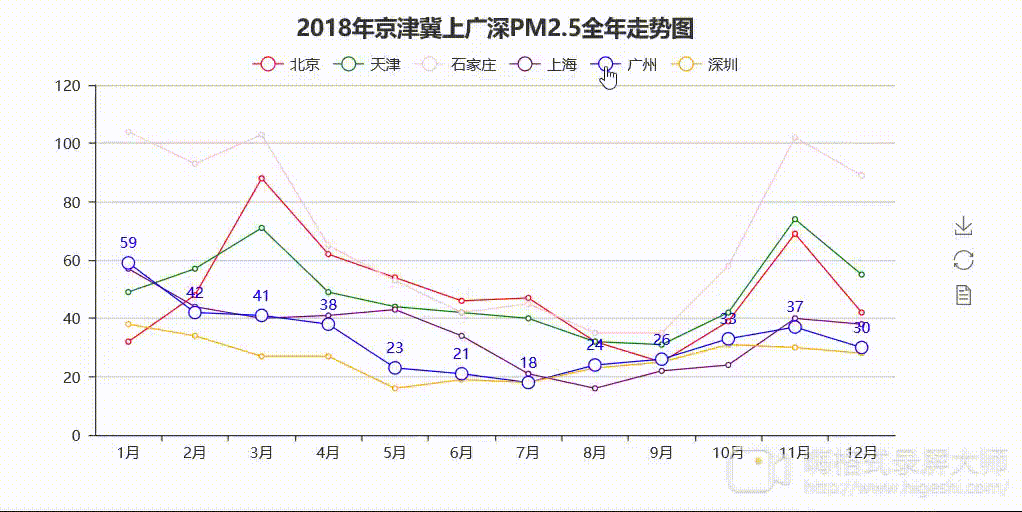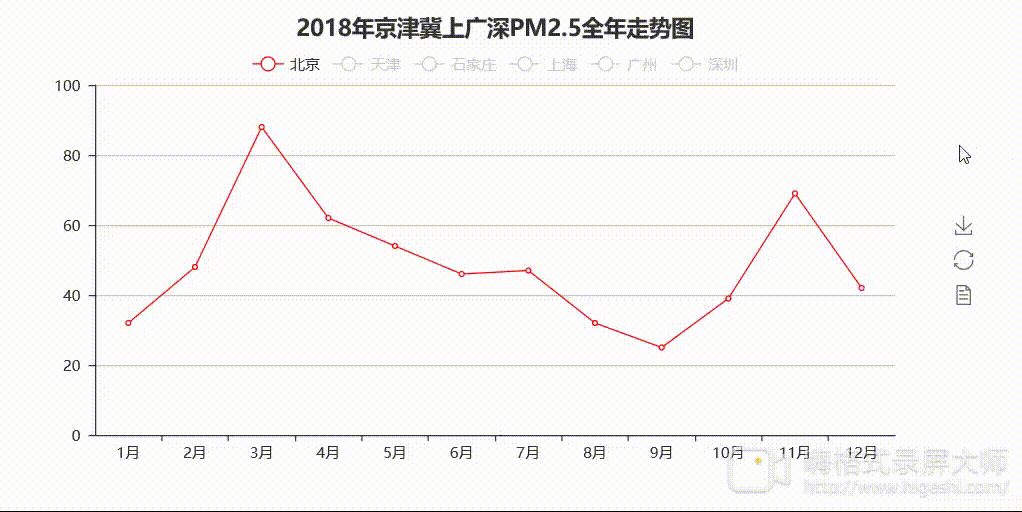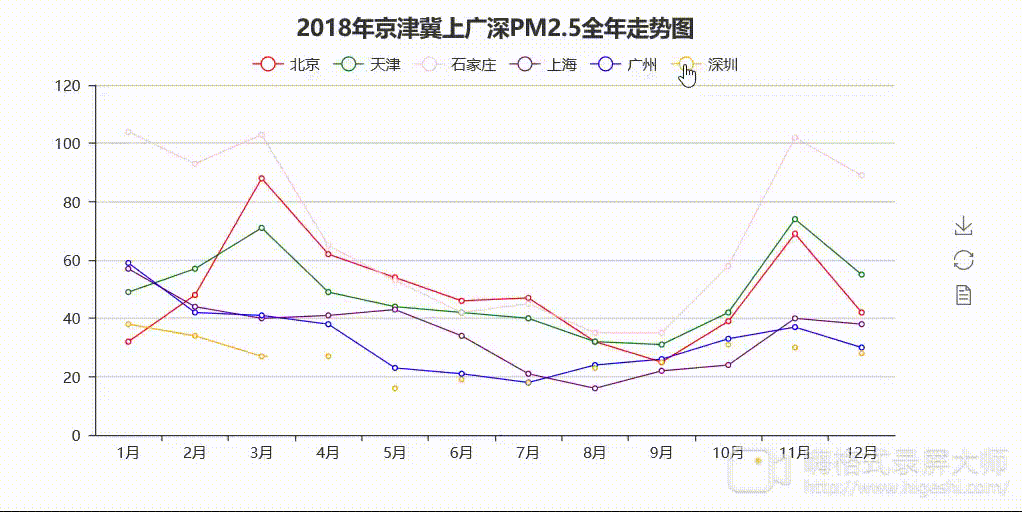
说明:因格式转换器问题,呈现的效果略微模糊,但是程序运行出来的html格式的图是十分清楚的。
常规格式
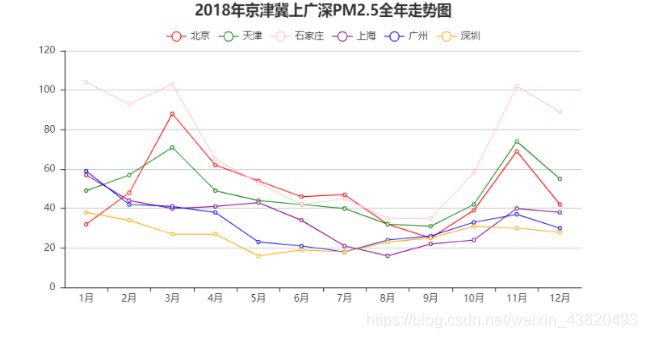
分析:从图1中可以看出,2018年南北部地区月均PM2.5值差异明显。京津冀地区的PM2.5值“名列前茅”,位居前三,走势较为一致,呈现秋冬高值春夏低值的特点。其中石家庄夺得“桂冠”,较为“高调”,全年PM2.5值走势最为突出,1月份达到最大值104,8、9月份达到最低值35。根据空气质量标准,石家庄全年都差不多在「优」(0~35)以下了。上广深情况较为乐观,走势一致且较为平稳,最高值均出现在1月份。上海和广州情况差不多(5、6月份除外),5、6月份上海月均PM2.5值高于广州且相差较大,广州情况相对较好。深圳情况最为乐观,1月份达到最大值38,5月份达到最低值16,PM2.5月均值都在40以下,全年空气质量等级差不多都在「优」,与石家庄形成了鲜明对比。较南部地区而言,北部地区空气质量有待改善。
3 地图可视化
3.1 导入相关地图库
from pyecharts import Geo3.2 导入地址和相应的PM2.5数据
data = [
("北京", 88),("天津", 74), ("石家庄", 104),("上海", 57), ("广州", 59), ("深圳", 38)
]3.3 设置地图名字以及画布大小
geo = Geo(
"京津冀上广深城市空气质量",
"data from pm2.5",
title_color="#fff",
title_pos="center",
width=1200,
height=600,
background_color="#404a59",
)3.4 设置可视化点的大小和动态效果以及颜色条显示范围
attr, value = geo.cast(data)
geo.add(
" ",# 注意与""的区别,在图顶部中间的scatter点
attr,
value,
type="effectScatter",
is_random=True,
# symbol="pin",
symbol_size=10,
effect_scale=5,
effect_period=2.5,
is_more_utils=True,
is_visualmap=True,
visual_range=[0, 120],
visual_text_color="#fff",
)3.5 生成.html格式的文件
geo.show_config()
geo.render(path="2018年京津冀上广深PM2.5.html")3.6 可视化地图结果

分析:我们可以清楚看到京津冀上广深每一城市在地图上的位置,以及它们的经纬度(前两个数据代表经纬度,第三个数据是2018年每个城市最大月均PM2.5值)。根据颜色的映射,京津冀地区的PM2.5污染较为严重,而上广深的空气质量较为良好。
注:该图在本人另一篇博客基于Python的京津冀上广深空气质量可视化分析是以gif格式进行展示的,可以看到其动态的一个效果。