统计HDFS上Hive数据库表文件大小及数据历史范围
一、获取Hive表名、HDFS路径、时间字段、分区信息、分区时间
from pyspark.sql.types import StructType, StructField, LongType, StringType,DoubleType
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("DataFrame").getOrCreate()
table_dict ={
}
#hive表名存放到列表中
table_list=[]
#获取hive数据库表名
database_data = spark.sql("show databases").collect()
for i in database_data:
database_name = i[0]
sql = "use %s" % (database_name)
a=spark.sql(sql).collect()
table_data=spark.sql("show tables").collect()
if len(table_data) == 0:
pass
else:
for j in table_data:
database_name2 = j[0]
table_name2 = j[1]
name_all = database_name2 + "." + table_name2
table_list.append(name_all)
#获取部分表
#table_list = table_list[1000:1250]
#第一部分获取hive表HDFS路径
#第二部分获取时间字段
#第三部分获取最早和最晚时间分片
for table_name in table_list:
table_sql = "desc extended %s" % (table_name)
e=spark.sql(table_sql).collect()
#获取表在HDFS上的路径,分为两种,hdfs或pfs,可以把表的路径存放到表中
path = []
if 'hdfs' in e[-5][1]:
elif 'hdfs' in e[-6][1]:
path.append(e[-6][1])
elif 'pfs' in e[-5][1]:
path.append(e[-5][1])
elif 'pfs' in e[-6][1]:
path.append(e[-6][1])
else:
path.append('路径不在倒数列表倒数第5或第6个元素里,在其他元素中')
table_dict[table_name]=path
#获取hive表时间字段,可以规范时间字段命名从而省略这一步骤
table_sql = "desc extended %s" % (table_name)
field_info=spark.sql(table_sql).collect()[0:-15]
field_list = []
for i in field_info:
for j in list(i):
if j and ('create_time' in j or 'creattime' in j or 'producttime' in j or 'createtime' in j or 'servertime' in j or 'collect_time' in j or 'insert_time' in j or 'begda' in j or 'aedtm' in j or 'datetime' in j or 'createdate' in j):
field_list.append(j)
time_field = ",".join(field_list)
table_dict[table_name].append(time_field)
#获取分区表最早最晚时间分片
try:
sql = "show partitions %s" % (table_name)
a=spark.sql(sql).collect()
begin_partition = a[0][0]
begin_partition = begin_partition.split('/')
begin_date = begin_partition[0][5:13]
begin_hour = begin_partition[1][5:7]
begin_minute = begin_partition[2][8:10]
last_partition = a[-1][0]
last_partition = last_partition.split("/")
last_date = last_partition[0][5:13]
last_hour = last_partition[1][5:7]
last_minute = last_partition[2][8:10]
table_dict[table_name].extend(['True',begin_date,begin_hour,begin_minute,last_date,last_hour,last_minute])
except:
table_dict[table_name].extend(['False','','','','','',''])
#汇总数据按照表名,路径,时间字段,是否分区表,时间分片存放到列表中
table_all_info = []
for key,value in table_dict.items():
value.insert(0,key)
table_all_info.append(value)
#转化为dataframe存入到hive表中
table_all_info = spark.sparkContext.parallelize(table_all_info)
pingo_table_fields = [
StructField("table_name", StringType(), True),
StructField("table_path", StringType(), True),
StructField("time_field", StringType(), True),
StructField("partition_table", StringType(), True),
StructField("partition_begin_date", StringType(), True),
StructField("partition_begin_hour", StringType(), True),
StructField("partition_begin_minute", StringType(), True),
StructField("partition_last_date", StringType(), True),
StructField("partition_last_hour", StringType(), True),
StructField("partition_last_minute", StringType(), True)
]
pingo_table_schema = StructType(pingo_table_fields)
table_all_info_df = spark.createDataFrame(table_all_info,pingo_table_schema)
#打印展示
#table_all_info_df.show(10)
#覆盖写入表中
spark.sql("set hive.exec.dynamic.partition.mode=nonstrict")
table_all_info_df.write.insertInto("test.pingo_table_base_info", overwrite=True)
如下图所示:
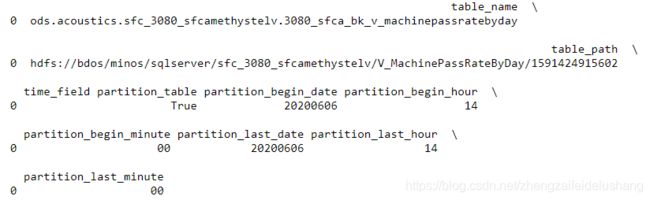
二、处理HDFS路径,多线程获取HDFS上Hive表大小
#分割字典
import itertools
#连接服务器
import paramiko
#连接pymysql数据库
import pymysql
#多线程池
import threadpool
import datetime
# 获取数仓开始状态
def get_pingo_table_info():
sql_db = pymysql.connect(host='10.133.0.19', port=30334, user='rw_etl', password='rw_etl.aac', db='lens_olap')
sql_cursor = sql_db.cursor()
pingo_dict = {
}
pingo_table_dict = {
}
try:
pingo_sql = f"select table_name,table_path,time_field,partition_table,partition_begin_date,partition_begin_hour,partition_begin_minute,partition_last_date,partition_last_hour,partition_last_minute from lens_olap.pingo_table_base_info"
sql_cursor.execute(pingo_sql)
pingo_results = sql_cursor.fetchall()
print(len(pingo_results))
if len(pingo_results) >= 1:
for i in pingo_results:
table_name = i[0]
table_path = i[1]
time_field = i[2]
partition_table = i[3]
partition_begin_date = i[4]
partition_begin_hour = i[5]
partition_begin_minute = i[6]
partition_last_date = i[7]
partition_last_hour = i[8]
partition_last_minute = i[9]
pingo_dict[table_name] = table_path
pingo_table_dict[table_name] = [partition_table,time_field,partition_begin_date,partition_begin_hour,partition_begin_minute,partition_last_date,partition_last_hour,partition_last_minute]
return pingo_table_dict
except Exception as e:
return 0
#处理HDFS路径
#存放路径形式一:hdfs://bdos/minos/sqlserver/iot_2080_mesdcp/2080_lens_bianzu_info/1583819014296
#存放路径形式二:pfs://ruishengpingo-pingo-master-176198623049158656.default.svc.cluster.local:8650/pingo/warehouse/aac_test.db/2080_lens_bianzu_mtf_info
#需要把路径格式转化为/pfs/pingo/warehouse/aac_test.db/2080_lens_bianzu_mtf_info
def del_path(pingo_dict):
for key,value in pingo_dict.items():
if value.startswith("hdfs://"):
pass
elif value.startswith("pfs://"):
pfs_path = value.split("/pingo/")
new_pfs_path = '/pfs' + '/pingo/' + pfs_path[-1]
pingo_dict[key]=new_pfs_path
else:
pass
return pingo_dict
#hive表存放在字典pingo_table_dict中
#切割字典,分片获取hive表空间大小
def splitDict(pingo_table_dict):
pingo_table_list = []
#转化为可迭代对象
pingo_table_iter = iter(pingo_table_dict.items())
#切割字典8次
for i in range(8):
#每次切割600条字典数据出来
pingo_table = dict(itertools.islice(pingo_table_iter,600))
#存放到字典中
pingo_table_list.append(pingo_table)
return pingo_table_list
#服务器执行脚本命令获取HDFS上hive表大小
def exec_ssh_command(ssh_command,ssh):
# 创建一个ssh对象
# 执行shell命令,返回的是一个元组
# ls /opt/bi/kettle/etljobs_svn/lens_olap/
stdin, stdout, stderr = ssh.exec_command(ssh_command)
# 返回shell命令执行结果
# for i in stdout.readlines():
# print(i)
##获取输出结果,decode('utf-8')解码是为了存在中文能够正常显示
result = stdout.read().decode('utf-8')
return result
#处理脚本命令获取到的HDFS上Hive表的大小
def del_value(result):
if result.startswith('0'):
atr = '0 G'
return atr
elif result == "":
atr = '0 G'
return atr
elif 'hdfs' in result:
atr = result.split(" hdfs:")[0]
return atr
elif 'pfs' in result:
atr = result.split(" /pfs")[0]
return atr
else:
return "其他结果情形"
#获取表的空间大小
def search_table_space(new_pingo_dict):
# ps -ef 命令就是列出当前所有的进程信息
ssh = paramiko.SSHClient()
# 如果之前没有连接过的ip,会出现Are you sure you want to continue connecting (yes/no)? yes
# 自动选择yes
key = paramiko.AutoAddPolicy()
ssh.set_missing_host_key_policy(key)
# 连接服务器
ssh.connect(
hostname='10.133.0.1', port=22, username='bigdata', password='bigdata.aac', timeout=50
)
new_dict = {
}
for key,value in new_pingo_dict.items():
ssh_command = 'hdfs dfs -du -s -h ' + " " + value
result = exec_ssh_command(ssh_command,ssh)
last_result = del_value(result)
new_dict[key] = [value,last_result]
ssh.close()
return new_dict
#多线程回调函数,得到的Hive表的大小统一放到results中
def get_result(request,result):
global results
results.append(result)
#处理多线程结果,拼接数据,一次性把几千条数据插入数据库
def get_sql(results):
for i in results:
for key, value in i.items():
if key in pingo_table_results:
pingo_table_results[key].insert(0,value[1])
pingo_table_results[key].insert(0,value[0])
time_now = str(datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S'))
pingo_table_results[key].append(time_now)
sql_all = ""
table_all_list = []
#把几千条数据拼接成sql,一次性导入数仓
for key,value in pingo_table_results.items():
sql = f'select "{key}","{value[0]}","{value[1]}","{value[2]}","{value[3]}","{value[4]}","{value[5]}","{value[6]}","{value[7]}","{value[8]}","{value[9]}","{value[10]}"'
table_all_list.append(sql)
sql_all = ' union all '.join(table_all_list)
sql_all = 'insert into pingo_table_base_info_bak2 ' + sql_all
sql_db = pymysql.connect(host='10.133.0.19', port=30334, user='rw_etl', password='rw_etl.aac', db='lens_olap')
sql_cursor = sql_db.cursor()
sql_cursor.execute(sql_all)
if __name__ == "__main__":
pingo_table_dict = get_pingo_table_info()
pingo_table_dict = del_path(pingo_table_dict)
table_all = []
pingo_table_list = splitDict(pingo_table_dict)
#存放多线程返回的HDFS上Hive表结果大小
results = []
#多进程运行程序
pool = threadpool.ThreadPool(8)
list_var0 = [pingo_table_list[0]]
list_var1 = [pingo_table_list[1]]
list_var2 = [pingo_table_list[2]]
list_var3 = [pingo_table_list[3]]
list_var4 = [pingo_table_list[4]]
list_var5 = [pingo_table_list[5]]
list_var6 = [pingo_table_list[6]]
list_var7 = [pingo_table_list[7]]
par_list = [(list_var0, None), (list_var1, None), (list_var2, None), (list_var3, None), (list_var4, None),(list_var5, None),(list_var6, None),(list_var7, None)]
#多线程执行任务,参数为函数,
re = threadpool.makeRequests(search_table_space, par_list, get_result)
res = [pool.putRequest(req) for req in re]
pool.wait()
#处理结果,一次性把几千条数据插入数据库
get_sql(results)
结果如下图所示:

三、查询Hive表数据时间范围
import pymssql
sql_db = pymssql.connect(server='10.178.13.1', port=1433, user='rw-etl', password='rw-etl.aac', database='DW')
sql_cursor = sql_db.cursor()
lens_dict = {
}
try:
pingo_sql = f"select table_name,table_path,time_field,partition_table,partition_begin_date,partition_begin_hour,partition_begin_minute,partition_last_date,partition_last_hour,partition_last_minute,table_space from DW.dbo.lens_pingo_table_info"
sql_cursor.execute(pingo_sql)
pingo_results = sql_cursor.fetchall()
if len(pingo_results) >= 1:
for i in pingo_results:
table_name = i[0]
table_path = i[1]
time_field = i[2]
partition_table = i[3]
partition_begin_date = i[4]
partition_begin_hour = i[5]
partition_begin_minute = i[6]
partition_last_date = i[7]
partition_last_hour = i[8]
partition_last_minute = i[9]
table_space = i[10]
max_sql = ''
min_sql = ''
#拼接查询Hive表时间范围的sql语句
#分为分区表和非分区表
if time_field=="":
pass
elif time_field !='' and partition_table=='True':
min_sql = "select min(%s) from %s where date= '%s'" % (time_field, table_name, partition_begin_date)
max_sql = "select max(%s) from %s where date= '%s'" % (time_field, table_name, partition_last_date)
elif time_field !='' and partition_table=='False':
min_sql = "select min(%s) from %s" % (time_field, table_name)
max_sql = "select max(%s) from %s" % (time_field, table_name)
else:
pass
lens_dict[table_name]=[table_path,table_space,partition_table,time_field,partition_begin_date,partition_begin_hour,partition_begin_minute,partition_last_date,partition_last_hour,partition_last_minute,min_sql,max_sql]
except Exception as e:
pass
lens_list = []
for key, value in lens_dict.items():
value.insert(0,key)
lens_list.append(tuple(value))
for i in lens_list:
print(i)
# # 往数据库执行插入的sql命令
sql = "INSERT INTO DW.dbo.lens_pingo_table_querysql (table_name,table_path,table_space,partition_table,time_field,partition_begin_date,partition_begin_hour,partition_begin_minute,partition_last_date,partition_last_hour,partition_last_minute,min_sql,max_sql) VALUES (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)"
# 批量执行多条插入SQL语句
sql_cursor.executemany(sql,lens_list)
sql_db.commit()
sql_db.close()
得到的查询语句如下所示:

四、查询Hive表数据时间范围
from pyspark.sql.types import StructType, StructField, LongType, StringType,DoubleType
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("DataFrame").getOrCreate()
#查询不是分区表的hive表数据时间范围
time_data=spark.sql("select table_name,table_path,table_space,partition_table,time_field,partition_begin_date,partition_begin_hour,partition_begin_minute,partition_last_date,partition_last_hour,partition_last_minute,min_sql,max_sql from dw.lens.lens_pingo_table_querysql where time_field !='' and partition_table='False'").collect()
#查询是分区表的Hive表数据时间范围
#time_data=spark.sql("select #table_name,table_path,table_space,partition_table,time_field,partition_begin_date,partit#ion_begin_hour,partition_begin_minute,partition_last_date,partition_last_hour,partition_#last_minute,min_sql,max_sql from dw.lens.lens_pingo_table_querysql where time_field !='' #and partition_table='True'").collect()
table_list = []
for i in time_data:
table_name = i[0]
table_path = i[1]
table_space = i[2]
partition_table = i[3]
time_field = i[4]
partition_begin_date = i[5]
partition_begin_hour = i[6]
partition_begin_minute = i[7]
partition_last_date = i[8]
partition_last_hour = i[9]
partition_last_minute = i[10]
min_sql = i[11]
max_sql = i[12]
try:
min_time = spark.sql(min_sql).collect()
min_time = min_time[0][0]
max_time = spark.sql(max_sql).collect()
max_time = max_time[0][0]
except:
min_time = ''
max_time = ''
temp = [table_name,table_path,table_space,partition_table,time_field,partition_begin_date,partition_begin_hour,partition_begin_minute,partition_last_date,partition_last_hour,partition_last_minute,min_time,max_time,min_sql,max_sql]
table_list.append(temp)
#数据放入dataframe中
table_time_info = spark.sparkContext.parallelize(table_list)
pingo_table_time_fields = [
StructField("table_name", StringType(), True),
StructField("table_path", StringType(), True),
StructField("table_space", StringType(), True),
StructField("partition_table", StringType(), True),
StructField("time_field", StringType(), True),
StructField("partition_begin_date", StringType(), True),
StructField("partition_begin_hour", StringType(), True),
StructField("partition_begin_minute", StringType(), True),
StructField("partition_last_date", StringType(), True),
StructField("partition_last_hour", StringType(), True),
StructField("partition_last_minute", StringType(), True),
StructField("min_time", StringType(), True),
StructField("max_time", StringType(), True),
StructField("min_sql", StringType(), True),
StructField("max_sql", StringType(), True)
]
pingo_table_time_schema = StructType(pingo_table_time_fields)
table_time_info_df = spark.createDataFrame(table_time_info,pingo_table_time_schema)
#table_time_info_df.show(10)
#按照表名,数据时间,查询语句,插入到表中
spark.sql("set hive.exec.dynamic.partition.mode=nonstrict")
table_time_info_df.write.insertInto("dw.lens.lens_pingo_table_info", overwrite=False)
至此成功获取到Hive表名、HDFS路径、表空间大小,是否分区表,时间字段,hive表数据的时间范围
