CGB2005-京淘15
1.Redis集群说明
1.1 Redis集群数据存储的原理
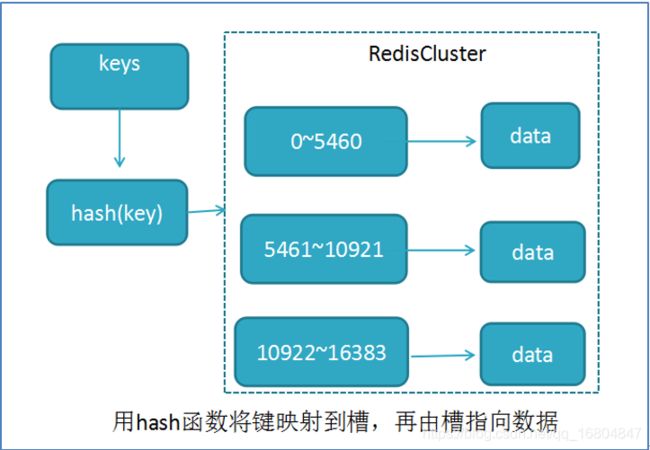
Hash槽算法 分区算法.
说明: RedisCluster采用此分区,所有的键根据哈希函数**(CRC16[key]%16384)**映射到0-16383槽内,共16384个槽位,每个节点维护部分槽及槽所映射的键值数据.根据主节点的个数,均衡划分区间.
算法:哈希函数: Hash()=CRC16[key]%16384

当向redis集群中插入数据时,首先将key进行计算.之后将计算结果匹配到具体的某一个槽的区间内,之后再将数据set到管理该槽的节点中.
1.2 面试题说明
问: Redis集群中最多存储16384个key 错
CRC16(KEY1)%16384 = 2000
CRC16(KEY2)%16384 = 2000
表示key1和key2都归节点1进行管理. 至于节点到底是否能够存储 由内存决定.
问: Redis集群中最多有多少个主机?? 16384台
1.3 Spring整合Redis集群
1.3.1 编辑pro配置文件
#添加redis的配置
#添加单台配置
#redis.host=192.168.126.129
#redis.port=6379
#配置多台的redis信息
#redis.nodes=192.168.126.129:6379,192.168.126.129:6380,192.168.126.129:6381
#配置Redis集群
redis.nodes=192.168.126.129:7000,192.168.126.129:7001,192.168.126.129:7002,192.168.126.129:7003,192.168.126.129:7004,192.168.126.129:7005
1.3.2 编辑配置类
@Configuration //标识我是一个配置类
@PropertySource("classpath:/properties/redis.properties")
public class JedisConfig {
@Value("${redis.nodes}")
private String nodes; //node,node,node
@Bean //实例化集群的对象之后交给Spring容器管理
public JedisCluster jedisCluster(){
Set<HostAndPort> set = new HashSet<>();
String[] nodeArray = nodes.split(",");
for(String node : nodeArray){
//host:port
String[] nodeTemp = node.split(":");
String host = nodeTemp[0];
int port = Integer.parseInt(nodeTemp[1]);
HostAndPort hostAndPort = new HostAndPort(host, port);
set.add(hostAndPort);
}
return new JedisCluster(set);
}
}
1.3.3 修改CacheAOP注入对象

1.3.4 页面效果展现
说明:只要数据可以正确获取 则表示运行成功!!

1.4 Redis持久化策略说明
1.4.1 持久化需求说明
说明:Redis数据都保存在内存中,如果内存断电则导致数据的丢失.为了保证用户的内存数据不丢失,需要开启持久化机制.
什么是持久化: 定期将内存中的数据保存到磁盘中.
1.4.2Redis中持久化介绍
说明:Redis中的持久化方式主要有2种.
方式1: RDB模式 dump.rdb 默认的持久化方式
方式2: AOF模式 appendonly.aof 默认关闭的需要手动的开启.
1.4.3 RDB模式
说明: RDB模式是Redis中默认的持久化策略.
特点:
1. RDB模式可以实现定期的持久化,但是可能导致数据丢失.
2. **RDB模式作的是内存数据的快照,**并且后拍摄的快照会覆盖之前的快照.所以持久化文件较小.恢复数据的速度较快. 工作的效率较高.
命令:
用户可以通过命令要求redis进行持久化操作.
1). save 是同步操作 要求redis立即执行持久化操作. 用户可能会陷入阻塞状态.
2). bgsave 是异步操作, 开启单独的线程执行持久化操作. 持久化时不会影响用户的使用. 不能保证立即马上执行.
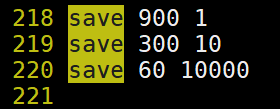
持久化策略说明:
LG: save 900 1 redis在900秒内执行一次set操作时则持久化一次.
用户操作越频繁则持久化的周期越短.
持久化目录: 可以执行持久化文件生成的位置.

持久化文件名称的设定

1.4.3 AOF模式
特点:
1. AOF模式默认的条件下是关闭状态,需要手动的开启.
2. AOF模式记录的是用户的执行的状态.所以持久化文件占用空间相对较大.恢复数据的速度较慢.所以效率较低.
3. 可以保证用户的数据尽可能不丢失.
配置:
1.开启AOF配置
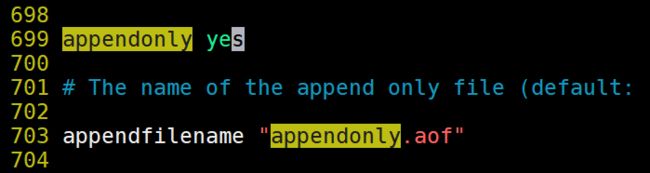
2.AOF模式的持久化策略
appendfsync always 如果用户执行的了一次set操作则持久化一次
appendfsync everysec aof每秒持久化一次
appendfsync no 不主动持久化.
1.4.4 关于RDB/AOF模式特点
1.如果用户可以允许少量的数据丢失可以选用RDB模式(快).
2.如果用户不允许数据丢失则选用AOF模式.
3.实际开发过程中一般2种方式都会配置. 一般主机开启RDB模式,从机开启AOF模式.
1.4.5 情景题
假设你是项目组长,手下一个特别漂亮的妹子在线上执行了flushALL命令.问:如果是你应该怎么办??
A: 严厉训斥 自己背锅 B: 批评教育,自己快速解决 C:严厉的训斥 之后开除员工
解决方案: 应该将AOF模式中flushAll删除,之后重启redis即可.
1.5 关于Redis内存优化的说明
1.5.1 背景说明
Redis可以当做内存使用,但是如果一直往里存储不删除数据,则必然导致内存溢出.
想法:如何可以实现内存数据的维护呢? 可以让用户永远都可以存数据.
1.5.2 LRU算法
LRU是Least Recently Used的缩写,即最近最少使用,是一种常用的页面置换算法,选择最近最久未使用的页面予以淘汰。该算法赋予每个页面一个访问字段,用来记录一个页面自上次被访问以来所经历的时间 t,当须淘汰一个页面时,选择现有页面中其 t 值最大的,即最近最少使用的页面予以淘汰。
维度:时间T
LRU算法是当下实现内存清理的最优算法.
1.5.3 LFU算法
LFU(least frequently used (LFU) page-replacement algorithm)。即最不经常使用页置换算法,要求在页置换时置换引用计数最小的页,因为经常使用的页应该有一个较大的引用次数。但是有些页在开始时使用次数很多,但以后就不再使用,这类页将会长时间留在内存中,因此可以将引用计数寄存器定时右移一位,形成指数衰减的平均使用次数。
维度: 引用次数
1.5.3 Random算法
1.5.3 TTL算法
说明:监控剩余的存活时间,将存活时间少的数据提前删除.
1.5.4 Redis内存优化策略
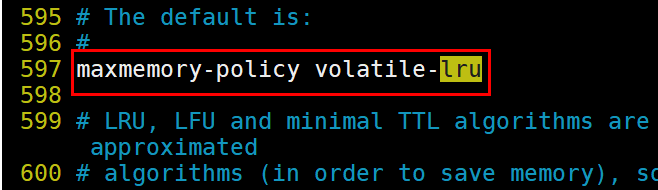
1.volatile-lru 在设定了超时时间的数据中,采用lru算法.
2.allkeys-lru 所有数据采用lru算法
3.volatile-lfu 在超时的数据中采用lfu算法
4.allkeys-lfu -> 所有数据采用lfu算法
5.volatile-random -> 设定超时时间的数据采用随机算法
6.allkeys-random -> 所有数据随机删除
7.volatile-ttl -> 删除存活时间少的数据
8.noeviction -> 不会删除数据,如果内存溢出报错返回.
2 京淘项目前台搭建
2.1 京淘项目架构图设计
说明:在分布式的条件下,有web服务器向后端的业务服务器获取数据.通过http请求协议利用远程调用的方式获取业务数据,将来采用更加通用的json方式返回.实现跨系统之间的数据访问.
并且每个节点根据用户访问量的不同搭建不同规模的集群.从而实现用户的高并发的访问.
tomcat 经过调优大约可以支持 1000/秒 跳大tomcat运行的内存即可.

2.2 京淘项目web创建
2.2.1 web项目创建说明
1.端口号: 8092
2.域名: http://www.jt.com
3.web服务器不需要链接数据库.
4.打包: war (JSP页面)
5.注意事项: 继承父级jt/依赖工具APIjt-common/配置maven插件.
2.2.2 创建jt-web项目

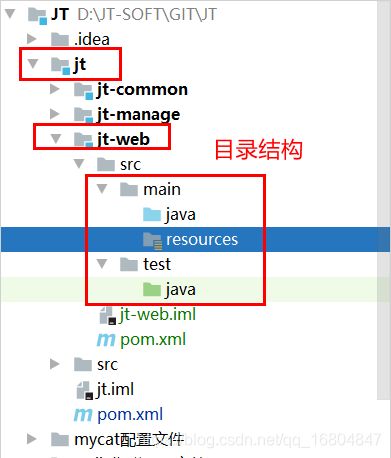
2.2.3 添加继承/依赖/插件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<artifactId>jt-web</artifactId>
<!--设定打包方式-->
<packaging>war</packaging>
<!--添加继承-->
<parent>
<artifactId>jt</artifactId>
<groupId>org.example</groupId>
<version>1.0-SNAPSHOT</version>
</parent>
<!--添加依赖项-->
<dependencies>
<dependency>
<groupId>org.example</groupId>
<artifactId>jt-common</artifactId>
<version>1.0-SNAPSHOT</version>
</dependency>
</dependencies>
<!--添加插件-->
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
2.2.4 导入静态资源文件
说明:将课前资料中的静态资源文件,进行导入.
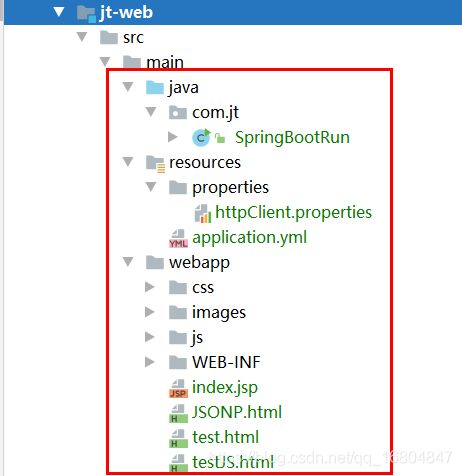
2.2.5 配置web项目启动项
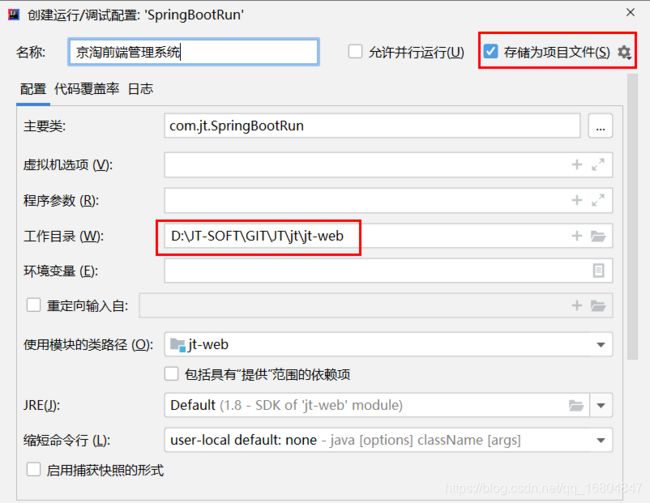
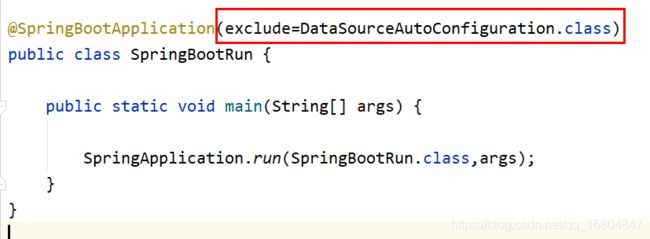
2.2.6 关于web项目配置数据源的说明
SpringBoot特点: 开箱即用!!!
报错说明:由于jt-web继承jt所以web服务器启动时,会加载数据源的自动化配置.但是由于web不需要链接数据库,所以导致程序异常.

解决方案:
2.2.7 项目启动效果

2.2.8 配置nginx
需求说明: 用户通过http://www.jt.com的方式访问服务器localhost:8092,修改之后重启nginx即可.
#搭建jt-web服务器
server {
listen 80;
server_name www.jt.com;
location / {
proxy_pass http://localhost:8092;
}
}
2.2.9 修改hosts文件
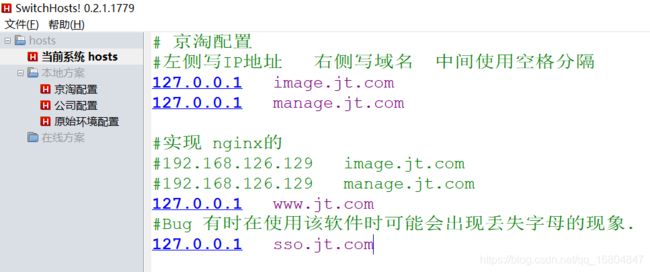
2.3 谷歌浏览器禁用https
步骤说明:
1.浏览器键入 chrome://net-internals/#hsts

2.4 添加web的配置类
2.4.1 编辑配置类
作用:要求springMVC可以拦截以.html为结尾的请求.
@Configuration //配置web.xml配置文件
public class MvcConfigurer implements WebMvcConfigurer{
//开启匹配后缀型配置,为了将来程序实现静态页面的跳转而准备的
@Override
public void configurePathMatch(PathMatchConfigurer configurer) {
configurer.setUseSuffixPatternMatch(true);
}
}
2.5 搜索引擎工作原理
2.5.1 关于.html说明
一般搜索引擎只能检索静态页面信息不能检索.jsp等动态的页面结构,所以一般为了提高网站的曝光率,使得商品更加容易的被用户检索,所以一般的商品页面都是.html的.
2.5.2.搜索引擎的工作原理
需求:假设数据库中有1亿条记录,搜索引擎如何能够在1秒之后检索所有的数据,并且有效的返回呢?
倒排索引: 根据关键字检索文章的位置.
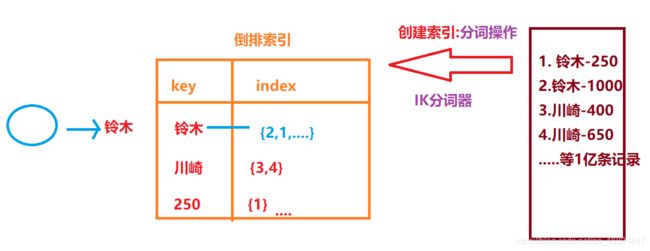
2.5.3 为什么搜索引擎只能记录.html页面
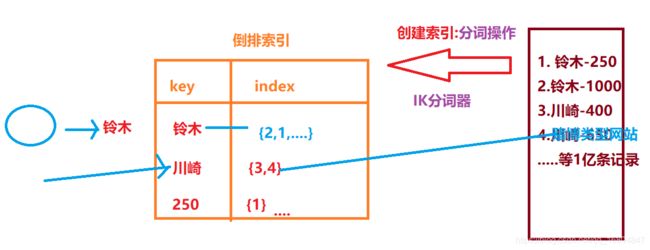
2.5.4 伪静态
伪静态是相对真实静态来讲的,通常我们为了增强搜索引擎的友好面,都将文章内容生成静态页面,但是有的朋友为了实时的显示一些信息。或者还想运用动态脚本解决一些问题。不能用静态的方式来展示网站内容。但是这就损失了对搜索引擎的友好面。怎么样在两者之间找个中间方法呢,这就产生了伪静态技术。伪静态技术是指展示出来的是以html一类的静态页面形式,但其实是用ASP一类的动态脚本来处理的。
概括: 以.html结尾的"动态页面"脚本技术. (.JSP/.html)
扩展知识
前提:在高并发的条件下由于引入缓存但是可能会引发如下的问题,导致数据库服务器宕机,影响用户的体验.
缓存-穿透
特点: 用户高并发的环境下,访问一个数据库中不存在的数据就叫缓存穿透!!!
解决方案: 限制用户单位时间内的访问次数 , 封禁IP地址. 网关过滤.
缓存-击穿
特点: 某些高频的访问数据由于操作不当导致缓存失效.从而使得大量的用户直接访问数据库. (一个)
解决方案: 配置多级缓存
缓存-雪崩
特点: 由于redis中的高频key在同一时间内大量的失效.导致用户的请求直接访问数据库,导致宕机的风险. (flushAll)
解决方案: 配置多级缓存,设定不同的超时时间.
3.作业
1.什么是跨域
2.什么是同源策略
3.解决跨域的常用手段 JSONP CORS