R语言数据分析系列六
—— by comaple.zhang
上一节讲了R语言作图,本节来讲讲当你拿到一个数据集的时候怎样下手分析,数据分析的第一步。探索性数据分析。
统计量,即统计学里面关注的数据集的几个指标。经常使用的例如以下:最小值,最大值,四分位数,均值,中位数,众数,方差,标准差。极差,偏度,峰度
先来解释一下各个量得含义,浅显就不说了,这里主要说一下不常见的
众数:出现次数最多的
方差:每一个样本值与均值的差得平方和的平均数
标准差:又称均方差,是方差的二次方根。用来衡量一个数据集的集中性
极差:最大值与最小值仅仅差
偏度:相对于正态分布而言假设波峰出如今左边,就表明长尾出如今右边。成为右偏态(正偏态)偏度值>0,分布反之为左偏太(负偏态)偏度值<0
峰度:也是相对于正太分布的。正态分布的峰度为3。假设峰度>3图形越胖,越矮。称为厚尾。峰度<3 图形越瘦,越高,称为瘦尾
本节数据集:
我们採用MASS包的Insurance数据集,该数据集为某保险公司的车险数据。
"District" "Group" "Age" "Holders" "Claims"
按列一次表示:家庭住址区域。投保汽车排量,投保人年龄,投保人数量,要求索赔的数量
安装包与载入数据集:
install.pacakges('MASS') # 安装包
library(MASS) #载入包
data(Insurance) # 载入数据集
ins <- Insurance #拷贝一份数据
探索行数据分析
R包自带的函数summary能够给出数据的概括:
summary(ins)
District Group Age Holders Claims
1:16 <1l :16 <25 :16 Min. : 3.00 Min. : 0.00
2:16 1-1.5l:16 25-29:16 1st Qu.: 46.75 1st Qu.: 9.50
3:16 1.5-2l:16 30-35:16 Median : 136.00 Median : 22.00
4:16 >2l :16 >35 :16 Mean : 364.98 Mean : 49.23
3rd Qu.:327.50 3rd Qu.: 55.50
Max. :3582.00 Max. :400.00
我们发现对于因子类型向量该方法给出了频度分布,对于连续型变量该方法给出了,最小值。第一四分位数。中位数,均值,第三四分位数,最大值
从结果中我们能够看到Holders列的数据中位数明显远小于均值,这说明这个数据集是个偏数据集,总体数据集中在3——327.5之间。我们能够通过点图来继续查看:
plot(ins$Holders) 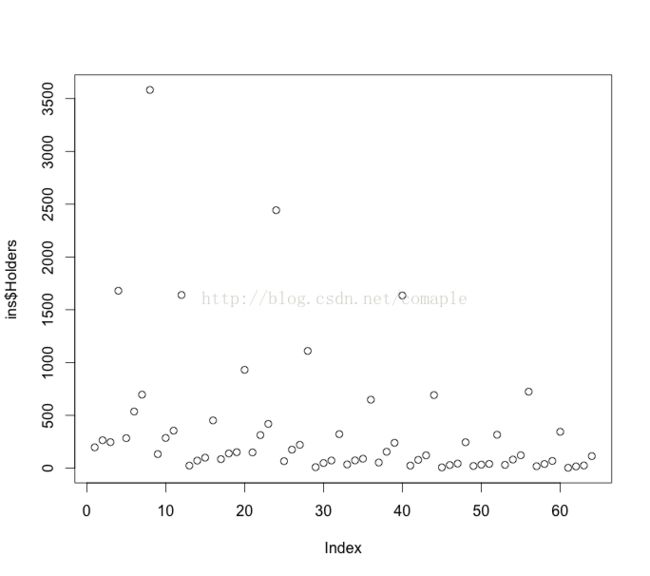
点图看的可能不是非常直观,我们期望直观的看到数据的变化,能够通过直方图来展示:
col <- c(brewer.pal(9,'YlOrRd')[1:9])
h<-hist(ins$Holders,breaks=12,col=col)
xfit <-seq(min(ins$Holders),max(ins$Holders),length=40)
yfit <-dnorm(xfit,mean=mean(ins$Holders),sd=sd(ins$Holders))
yfit <- yfit*diff(h$mids[1:2]) *length(ins$Holders)
lines(xfit,yfit,col='red',lwd=2) 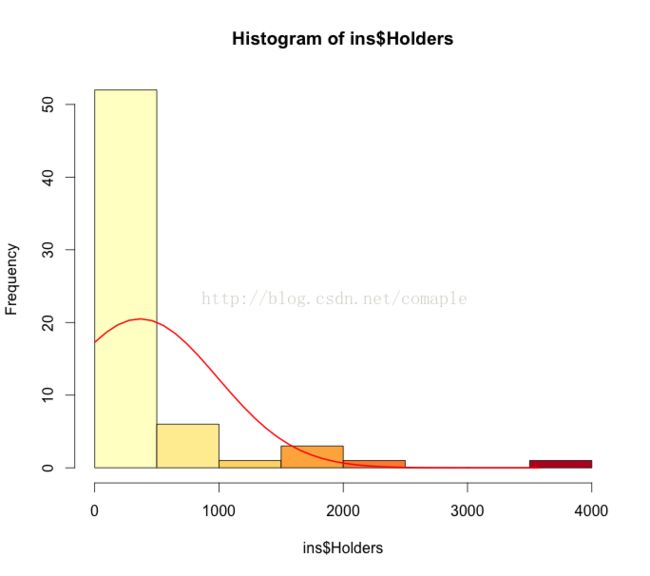
方差与标准差
来计算Holders列的方差和标准差:
var(ins$Holders)
sd(ins$Holders)事实上单变量的方差和标准差是没有太大意义的。对照才干够看出数据集的异同。
假设我们要分析用户依照年龄分组后的统计值该怎样计算呢。aggregate函数为我们提供了非常好的方法例如以下:
agg<-aggregate(ins[4:5],by=list(age=ins$Age),sd)
pie(agg$Claims,labels=agg$age)
agg
age Holders Claims
1 <25 80.41797 16.55181
2 25-29 141.11414 22.63184
3 30-35 177.34353 24.23694
4 >35 941.66603 103.52228
相当于依照age列 group by 后的分组统计量。

偏度和峰度:
为了计算偏度和峰度我们能够自己实现函数stat例如以下:
stat <- function(x,na.omit=F){
if(na.omit) x <- x[!is.na(x)]
m<- mean(x)
n<- length(x)
s<- sd(x)
skew <- sum((x-m)^3/s^3)/n
kurt <- sum((x-m)^4/s^4)/n - 3
return(c(n=round(n),mean=m,stdev=s,skew=skew,kurtosis=kurt))
}
sapply(ins[4:5],stat)
Holders Claims
n 64.000000 64.000000
mean 364.984375 49.234375
stdev 622.770601 71.162399
skew 3.127833 2.877292
kurtosis 10.999610 9.377258
我们能够看到,Holders和Claims的偏度都是大于零的,那么就是说明,这两个变量都是正偏态分布也就是说数据偏向左边,而峰度值都非常高。那么说明这两个变量都存在离群点。
同样,我们可以使用的开箱图观察,本节已经介绍,这里不再赘述。
版权声明:本文博主原创文章,博客,未经同意不得转载。