分片逻辑图
上节搭建的分片集群从逻辑上看如下图所示:
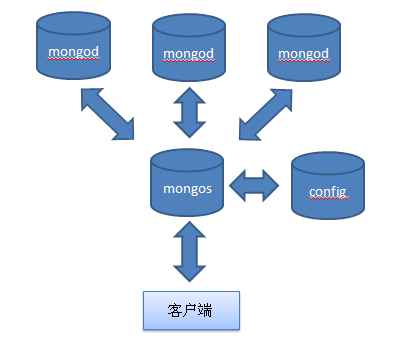
片:可以普通的mongod进程,也可以是副本集。但是即使一片内有多台服务器,也只能有一个主服务器,其他的服务器保存相同的数据。
mongos路由进程:它路由所有请求,然后将结果聚合。它不保存存储数据或配置信息。
配置服务器:存储集群的配置信息。
整个分布式的集群通过mongos对客户端提供了一个透明统一的接口,客户端不需要关系具体的分片细节,所有分片的动作都是自动执行的,那是如何做到透明和自动的。
切分数据
上节中建立好集群后,默认的是不会将存储的每条数据进行分片处理,需要在数据库和集合的粒度上都开启分片功能。开启test库的分片功能:
. ./bin/mongo –port . mongos>. mongos> db.runCommand({:. { :开启user集合分片功能:
. mongos> db.runCommand({:,:{:. { : , : }注意:需要切换到admin库执行命令。
片键:上面的key就是所谓的片键(shard key)。MongoDB不允许插入没有片键的文档。但是允许不同文档的片键类型不一样,MongoDB内部对不同类型有一个排序:

片键的选择至关重要,后面会进行详细的说明。
这时再切换到config库如下查看:
![]()
. mongos>. mongos>. { : , : , : . { : , : , : . { : , : , : . { : , : , : . { : , : , : . mongos>. { : , : { : , : }, : ObjectId(), : , : { : { : } }, : { : { : } }, : }![]()
Chunks:理解MongoDB分片机制的关键是理解Chunks。mongodb不是一个分片上存储一个区间,而是每个分片包含多个区间,这每个区间就是一个块。
. mongos>. mongos>. { : , : . ……平衡:如果存在多个可用的分片,只要块的数量足够多,MongoDB就会把数据迁移到其他分片上,这个迁移的过程叫做平衡。Chunks默认的大小是64M200M,查看config.settings可以看到这个值:
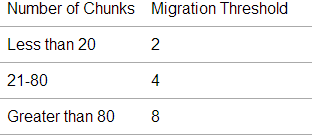
只有当一个块的大小超过了64M200M,MongoDB才会对块进行分割(但根据我的实践2.4版本块分割的算法好像并不是等到超过chunkSize大小就分割,也不是一分为二,有待继续学习),并当最大分片上的块数量超过另一个最少分片上块数量达到一定阈值会发生所谓的chunk migration来实现各个分片的平衡 (如果启动了balancer进程的话)。这个阈值随着块的数量不同而不同:
这带来一个问题是我们测开发测试的时候,往往希望通过观察数据在迁移来证明分片是否成功,但64M200M显然过大,解决方法是我们可以在启动mongos的时候用—chunkSize来制定块的大小,单位是MB。
. ./bin/mongos --port --configdb .: --logpath log/mongos.log --fork --chunkSize我指定1MB的块大小重新启动了一下mongos进程。
或者向下面这要修改chunkSize大小:
. mongos>. mongos> db.settings.save( { _id:, value: } )2.4版本之前MongoDB基于范围进行分片的(2.2.4会介绍基于哈希的分片),对一个集合分片时,一开始只会创建一个块,这个块的区间是(-∞,+∞),-∞表示MongoDB中的最小值,也就是上面db.chunks.find()我们看到的$minKey,+∞表示最大值即$maxKey。Chunck的分割是自动执行的,类似于细胞分裂,从区间的中间分割成两个。
分片测试
现在对上面我们搭建的MongoDB分片集群做一个简单的测试。目前我们的集群情况如下(为了方面展示我采用了可视化的工具MongoVUE):
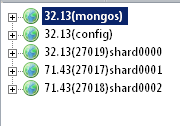
像上面提到那样为了尽快能观察到测试的效果,我么启动mongos时指定的chunkSize为1MB。
我们对OSSP10库和bizuser集合以Uid字段进行分片:
. mongos>. mongos> db.runCommand({:. { : . mongos> db.runCommand({:,:{:. { : , : }在插入数据之前查看一下config.chunks,通过查看这个集合我们可以了解数据是怎么切分到集群的:
. mongos>. { : , : { : , : }, : ObjectId(), : , : { : { : } }, : { : { : } }, : }开始只有一个块,区间(-∞,+∞)在shard0000(192.168.32.13:27019)上,下面我们循环的插入100000条数据:
. mongos>. mongos> (i=;i<;i++){ db.bizuser.insert({:i,:,:,: Date()}); }完成后我们在观察一下config.chunks的情况:
![]()
. mongos>. { : , : { : , : }, : ObjectId(), : , : { : { : } }, : { : }, : . { : , : { : , : }, : ObjectId(), : , : { : }, : { : }, : . { : , : { : , : }, : ObjectId(), : , : { : }, : { : { : } }, : }![]()
我们可以看见刚开始的块分裂成了三块分别是(-∞,0)在shard0002上,[0,6747)在shard0000上和[6747,+ ∞)在shard0001上。
说明:这里需要说明的是MongoDB中的区间是左闭右开的。这样说上面第一个块不包含任何数据,至于为什么还不清楚,有待继续调研。
我们持续上面的插入操作(uid从0到100000)我们发现块也在不停的分裂:
![]()
. mongos>. { : , : { : , : }, : ObjectId(), : , : { : { : } }, : { : }, : . { : , : { : , : }, : ObjectId(), : , : { : }, : { : }, : . { : , : { : , : }, : ObjectId(), : , : { : }, : { : }, : . { : , : { : , : }, : ObjectId(), : , : { : }, : { : { : } }, : . { : , : { : , : }, : ObjectId(), : , : { : }, : { : }, : }![]()
分片的规则正是上面提到的块的自动分裂和平衡,可以发现不同的块是分布在不同的分片上。
注意:这里使用Uid作为片键通常是有问题的,2.3对递增片键有详细说明。
Note:通过sh.status()可以很直观的查看当前整个集群的分片情况,类似如下:

对已有数据进行分片
面的演示都是从零开始构建分片集群,但是实际中架构是一个演进的过程,一开始都不会进行分片,只有当数据量增长到一定程序才会考虑分片,那么对已有的海量数据如何处理。我们在上节的基础上继续探索。《深入学习MongoDB》中有如下描述:

我们现在来尝试下(也许我使用的最新版本会有所有变化),先在192.168.71.43:27179上再启一个mongod进程:
. numactl --interleave=all ./bin/mongod --dbpath data/shard3/ --logpath log/shard3.log --fork --port现在我们像这个mongod进程中的OSSP10库的bizuser集合中插入一些数据:
. (i=;i<;i++){ db.bizuser.insert({:i,:,:,: Date()}); }我们这个时候尝试将这个mongod加入到之前的集群中去:
. mongos> db.runCommand({addshard:. : . : . }果然最新版本依旧不行。我们删除OSSP10库,新建个OSSP20库再添加分片则可以成功。
. { : , : }那么看来我们只能在之前已有的数据的mongod进程基础上搭建分片集群,那么这个时候添加切片,MongoDB对之前的数据又是如何处理的呢?我们现在集群中移除上面添加的切片192.168.71.43:27019,然后在删除集群中的OSSP10库。
这次我们尽量模拟生产环境进行测试,重新启动mongos并不指定chunksize,使用默认的最优的大小(64M200M)。然后在192.168.71.43:27019中新建OSSP10库并向集合bizuser中插入100W条数据:
. (i=;i<;i++){ db.bizuser.insert({:i,:,:,: Date()}); }然后将此节点添加到集群中,并仍然使用递增的Uid作为片键对OSSP10.bizuser进行分片:
. mongos>. mongos> db.runCommand({:. { : . mongos> db.runCommand({:,:{:. { : , : }观察一下config.chunks可以看见对新添加的切片数据进行切分并进行了平衡(每个分片上一个块),基本是对Uid(0~1000000)进行了四等分,当然没那精确:
![]()
. mongos>. mongos>. { : , : { : , : }, : ObjectId(), : , : { : { : } }, : { : }, : . { : , : { : , : }, : ObjectId(), : , : { : }, : { : }, : . { : , : { : , : }, : ObjectId(), : , : { : }, : { : { : } }, : . { : , : { : , : }, : ObjectId(), : , : { : }, : { : }, : . { : , : { : , : }, : ObjectId(), : , : { : }, : { : }, : }![]()
MongoDB这种自动分片和平衡的能力使得在迁移老数据的时候变得非常简单,但是如果数据特别大话则可能会非常的慢。
Hashed Sharding
MongoDB2.4以上的版本支持基于哈希的分片,我们在上面的基础上继续探索。
交代一下因为环境变动这部分示例操作不是在之前的那个集群上,但是系统环境都是一样,逻辑架构也一样,只是ip地址不一样(只搭建在一台虚拟机上),后面环境有改动不再说明:
配置服务器:192.168.129.132:10000
路由服务器:192.168.129.132:20000
分片1:192.168.129.132:27017
分片2:192.168.129.132:27018
……其他分片端口依次递增。
我们重建之前的OSSP10库,我们仍然使用OSSP10.bizuser不过这次启动哈希分片,选择_id作为片键:
. mongos>. mongos> db.runCommand({:. { : . mongos> db.runCommand({:,:{:. { : , : }我们现在查看一下config.chunks
![]()
. mongos>. mongos>. { : , : { : , : }, : ObjectId(), : , : { : { : } }, : { : NumberLong() }, : . { : , : { : , : }, : ObjectId(), : , : { : NumberLong() }, : { : NumberLong() }, : . { : , : { : , : }, : ObjectId(), : , : { : NumberLong() }, : { : NumberLong() }, : . { : , : { : , : }, : ObjectId(), : , : { : NumberLong() }, : { : { : } }, : }![]()
MongoDB的哈希分片使用了哈希索引:
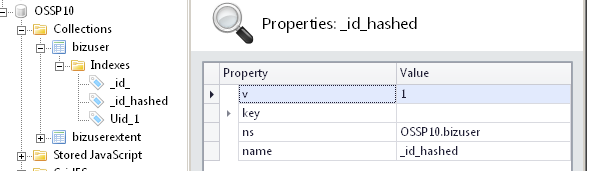
哈希分片仍然是基于范围的,只是将提供的片键散列成一个非常大的长整型作为最终的片键。官方文中描述如下:
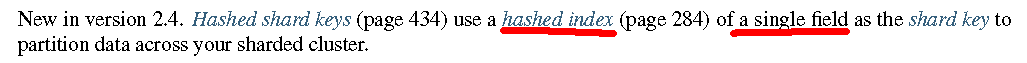
不像普通的基于范围的分片,哈希分片的片键只能使用一个字段。
选择哈希片键最大的好处就是保证数据在各个节点分布基本均匀,下面使用_id作为哈希片键做个简单的测试:
. mongos> db.runCommand({:. db.runCommand({:,:{:. mongos>. mongos> (i=;i<;i++){ db.mycollection.insert({:i,:,:,:new Date()}); }
通过MongoVUE观察三个切片上的数据量非常均匀:
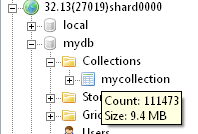
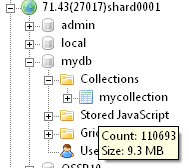
上面是使用官方文档中推荐的Objectid作为片键,情况很理想。如果使用一个自增长的Uid作为片键呢:
. db.runCommand({:,:{:. (i=;i<;i++){ db.mycollection.insert({:i,:,:,:new Date()}); }故障恢复
先不考虑集群中每个分片是副本集复杂的情况,只考虑了每个分片只有一个mongod进程,这种配是只是不够健壮还是非常脆弱。我们在testdb.testcollection上启动分片,然后向其中插入一定量的数据(视你的chunkSize而定),通过观察config.chunks确保testdb.testcollection上的数据被分布在了不同的分片上。
![]()
. mongos> db.runCommand({:. mongos> db.runCommand({:,:{:. (i=;i<;i++){ db.testcollection.insert({:i,:,:,. mongos>. mongos> db.chunks.. { : , : { : , : }, : ObjectId(), : , : { : }, : { : }, : . { : , : { : , : }, : ObjectId(), : , : { : }, : { : }, : . { : , : { : , : }, : ObjectId(), : , : { : }, : { : }, : }![]()
这时我们强制杀掉shard2进程:
. [root@localhost mongodb-.]# -ef |. root : ? :: ./bin/mongod --dbpath data/shard3/ --logpath log/shard3.log --fork --port . -我们尝试用属于不同范围的Uid对testdb.testcollection进行写入操作(这里插入一条记录应该不会导致新的块迁移):
![]()
. [root@localhost mongodb-.]# -ef |. mongos> db.testcollection.insert({:,:,:,. mongos> db.testcollection.insert({:,:,:,. mongos> db.testcollection.insert({:,:,:,. socket exception [CONNECT_ERROR] .:. mongos> db.testcollection.({Uid:. mongos> db.testcollection.({Uid: . mongos> db.testcollection.({Uid: . : . : . : . Sat Apr ::. : . : . : . } at src/mongo/shell/query.js:L180![]()
可以看到插入操作涉及到分片shard0002的操作都无法完成。这是顺理成章的。
下面我们重新启动shard3看集群是否能自动恢复正常操作:
![]()
. ./bin/mongod --dbpath data/shard3/ --logpath log/shard3.log --fork --port . mongos>. mongos> db.shards.. { : , : . { : , : . { : , : }![]()
重复上面的插入和读取shard0002的操作:
. mongos> db.testcollection.insert({:,:,:,. db.testcollection.({Uid: . { : ObjectId(), : , : , : , : ISODate(. ##没有问题总结:当集群中某个分片宕掉以后,只要不涉及到该节点的操纵仍然能进行。当宕掉的节点重启后,集群能自动从故障中恢复过来。
这一节在前一节搭建的集群基础上做了一些简单的测试,下一节的重点是性能和优化相关。