神经网络
原理
神经网络从大脑的工作原理得到启发,可用于解决通用的学习问题。神经网络的基本组成单元是神经元(neuron)。每个神经元具有一个轴突和多个树突。每个连接到本神经元的树突都是一个输入,当所有输入树突的兴奋水平之和超过某一阈值,神经元就会被激活。激活的神经元会沿着其轴突发射信号,轴突分出数以万计的树突连接至其他神经元,并将本神经元的输出并作为其他神经元的输入。数学上,神经元可以用感知机的模型表示。
参数设置
import numpy as np
import matplotlib.pyplot as plt
from sklearn.neural_network import MLPClassifier
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
def set_params():
wine = load_wine()
X = wine.data[:, :2]
y = wine.target
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
mlp = MLPClassifier(solver='lbfgs', hidden_layer_sizes=[10, 10], activation='tanh', alpha=1)
mlp.fit(X_train, y_train)
print(mlp)
x_min, x_max = X_train[:, 0].min() - 1, X_train[:, 0].max() + 1
y_min, y_max = X_train[:, 1].min() - 1, X_train[:, 1].max() + 1
# 用不同的色块表示不同的分类
xx, yy = np.meshgrid(np.arange(x_min, x_max, .02),
np.arange(y_min, y_max, .02))
z = mlp.predict(np.c_[(xx.ravel(), yy.ravel())]).reshape(xx.shape)
plt.figure()
plt.pcolormesh(xx, yy, z)
# 用散点图画出训练集和测试数据集
plt.scatter(X[:, 0], X[:, 1], c=y, edgecolors='k', s=60)
# 设定横轴纵轴的范围
plt.xlim(xx.min(), xx.max())
plt.ylim(yy.min(), yy.max())
# 设定图题
plt.title('MLPClassifier:solver=lbfgs')
plt.show()
运行结果
MLPClassifier(activation='tanh', alpha=1, batch_size='auto', beta_1=0.9,
beta_2=0.999, early_stopping=False, epsilon=1e-08,
hidden_layer_sizes=[10, 10], learning_rate='constant',
learning_rate_init=0.001, max_iter=200, momentum=0.9,
n_iter_no_change=10, nesterovs_momentum=True, power_t=0.5,
random_state=None, shuffle=True, solver='lbfgs', tol=0.0001,
validation_fraction=0.1, verbose=False, warm_start=False)
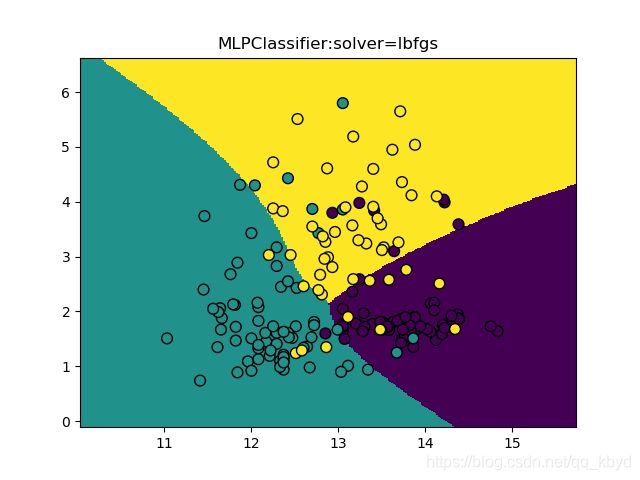
参数调节主要有:activation 是将隐藏单元进行非线性化的方法,共有 4 种,identity、logistic、tanh、relu。alpha 是一个L2惩罚项,用来控制正则化的程度,值越大,正则化程度越大,模型越简单。hidden_layer_sizes 用来指定隐藏层的层数和节点数。
手写图片识别
from sklearn.datasets import fetch_mldata
from sklearn.model_selection import train_test_split
from sklearn.neural_network import MLPClassifier
from PIL import Image
import numpy as np
def handwriting():
mnist = fetch_mldata('MNIST original')
print('-----------')
print('样本数量:{},样本特征数:{}'.format(mnist.data.shape[0], mnist.data.shape[1]))
print('-----------')
X = mnist.data/255.
y = mnist.target
X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=5000, test_size=1000, random_state=62)
nlp = MLPClassifier(solver='lbfgs', hidden_layer_sizes=[100, 100], activation='relu', alpha=1e-5, random_state=62)
nlp.fit(X_train, y_train)
print('-----------')
print('测试数据集得分:{:.2f}%'.format(nlp.score(X_test, y_test)*100))
print('-----------')
# 识别图片
image = Image.open('3.png').convert('F')
image = image.resize((28, 28))
arr = []
for i in range(28):
for j in range(28):
pixel = 1.0 - float(image.getpixel((j, i)))/255.
arr.append(pixel)
arr1 = np.array(arr).reshape(1, -1)
print('图中的数字是:{:.0f}'.format(nlp.predict(arr1)[0]))
运行结果
-----------
样本数量:70000,样本特征数:784
-----------
-----------
测试数据集得分:93.60%
-----------
图中的数字是:5
需要注意的是,需要将被识别的图像大小重设为 28 * 28 的比例。实际上我放置的是手写的数字 3 ,结果识别成了 5。看来识别效果并不是很好。