1.《Spectral Networks and Deep Locally Connected Networks on Graphs》论文理解
1.引言
在欧式空间中使用的CNN卷积具有平移不变性,权值共享,局部连接,分层次表达的特点;但是图网络是一种非欧式结构的数据,网络是不规整的关系型数据,所以其不存在平移不变形(每个节点的周围邻居数不固定),导致图网络无法使用传统的CNN。不使用卷积核卷积的话,只能按照全连接网络的方式进行线性映射,这样又将失去权值共享,局部连接,分层次表达这些优势,需要大量的参数。在《Spectral Networks and Deep Locally Connected Networks on Graphs》 中,作者想办法把传统欧式空间的卷积迁移到图网络中去,作者提出了两个结构,把欧式空间的卷积迁移到了图网络的空间域和频域。
2.空间结构
无向图: G = ( Ω , W ) G=(\Omega,W) G=(Ω,W),其中 Ω \Omega Ω表示图中所有节点的集合,size = m; W W W表示图的邻接矩阵,shape = (m,m),由于是无向图, W W W是一个对称矩阵。 W W W中的值 W i , j W_{i,j} Wi,j表示节点i,j之间的边的权重,为非负值,当这两个节点之间没有边的时候,认为权重值为0。
2.1 节点的邻域
在传统的欧式空间中(以图像为例),在卷积时需要设置一定大小的卷积核,如 kernel = (3,3),就是相当于中心像素点的邻域为周围的8个像素点。
在图中,利用 W W W来确定每个节点的邻域。论文中给出公式:
N δ ( j ) = { i ∈ Ω : W i , j > δ } (1) N_\delta(j)=\{i\in\Omega:W_{i,j}>\delta\}\tag{1} Nδ(j)={ i∈Ω:Wi,j>δ}(1)
N δ ( j ) N_\delta(j) Nδ(j)表示 j j j的邻域,是一个集合;以 δ \delta δ为阈值划分节点 j j j的邻域,权值大于 δ \delta δ才属于 j j j的邻域。
2.3 深度局部连接网络
2.2节中作者在介绍一个传统卷积的分层次表达的特点,这里就不再解释,直接进入2.3节。
在传统的欧式空间中(以图像为例),在卷积时需要设置一定大小的步长,如stride = (3,3),假设input_image.shape = (18,18),kernel = (3,3),out_image.shape = (6,6),这个操作相当于在18×18个像素点中找到了6×6个聚类中心,将其进行聚类操作,每个类中的元素为中心点的邻域元素。将每个类与卷积核对应项相乘求和,得到输出的一个像素点。
在图中,作者给出了以下(2)(3)两个公式:
N k = { N k , i ; i = 1... d k − 1 } (2) N_{k}=\{N_{k,i};i=1...d_{k-1}\}\tag{2} Nk={ Nk,i;i=1...dk−1}(2)
在公式(2)中,k表示第k个尺度,类比传统卷积,意思就是第k层卷积层, Ω k \Omega_{k} Ωk表示第k层输入的节点数目, d k − 1 d_{k-1} dk−1第k-1层中聚类的类数,即 Ω k = d k − 1 \Omega_{k} = d_{k-1} Ωk=dk−1, Ω k + 1 = d k \Omega_{k+1}=d_{k} Ωk+1=dk表示输出的节点数目, N k , i N_{k,i} Nk,i表示第i个节点的类,在这个公式中,作者是以每个输入节点为类中心,以节点邻域为类元素,得到了 Ω k = d k − 1 \Omega_{k} = d_{k-1} Ωk=dk−1个类。
具体如何得到 N k N_{k} Nk如上图所示:(这些公式就没怎么看懂了)
x k + 1 , j = L k h ( ∑ i = 1 f k − 1 F k , i , j x k , j ) ( j = 1... f k ) (3) x_{k+1,j}=L_{k}h(\sum_{i=1}^{f_{k-1}}{F_{k,i,j}x_{k,j}})(j=1...f_{k})\tag{3} xk+1,j=Lkh(i=1∑fk−1Fk,i,jxk,j)(j=1...fk)(3)
在公式(3)中, f k − 1 f_{k-1} fk−1表示k-1层的滤波器个数,也是k层中每个节点的特征维数。 x k = ( x k , i ; i = 1... f k − 1 ) x_{k}=(x_{k,i};i=1...f_{k-1}) xk=(xk,i;i=1...fk−1), x k x_{k} xk.shape = ( d k − 1 , f k − 1 d_{k-1},f_{k-1} dk−1,fk−1),表示输入数据; x k , i x_{k,i} xk,i.shape = ( d k − 1 d_{k-1} dk−1,1),表示 d k − 1 d_{k-1} dk−1个节点的第i个特征拼接形成的向量。 F k , i , j F_{k,i,j} Fk,i,j.shape = ( d k − 1 , d k − 1 d_{k-1},d_{k-1} dk−1,dk−1),表示第k层第j个滤波器的i个值, F k , i , j F_{k,i,j} Fk,i,j的值与 N k N_{k} Nk有关,表示第k层第j个滤波器的i个特征的映射关系,x节点和y节点不是邻域关系则对应的 F k , i , j ( x , y ) F_{k,i,j}(x,y) Fk,i,j(x,y)的值将为0,和 W W W类似。
∑ i = 1 f k − 1 F k , i , j x k , j \sum_{i=1}^{f_{k-1}}{F_{k,i,j}x_{k,j}} ∑i=1fk−1Fk,i,jxk,j部分完成了卷积的工作(类比传统的卷积的话,可以认为卷积的模式选择了same,stride = 1),卷积后输出和输入节点数一样,输出 ( d k − 1 , 1 ) (d_{k-1},1) (dk−1,1)的向量, h ( ∗ ) h(*) h(∗)为非线性激励函数, L k ( ∗ ) L_{k}(*) Lk(∗)为池化操作,将 ( d k − 1 , 1 ) (d_{k-1},1) (dk−1,1)的向量池化为 ( d k , 1 ) (d_{k},1) (dk,1)的向量,即 x k + 1 , j . s h a p e = ( d k , 1 ) x_{k+1,j}.shape = (d_{k},1) xk+1,j.shape=(dk,1),然后,如果第k层有 f k f_{k} fk个滤波器的话,那么第k层的输出为 x k + 1 = ( x k + 1 , i ; i = 1... f k ) x_{k+1}=(x_{k+1,i};i=1...f_{k}) xk+1=(xk+1,i;i=1...fk)。
图上的空间域卷积如下图所示:
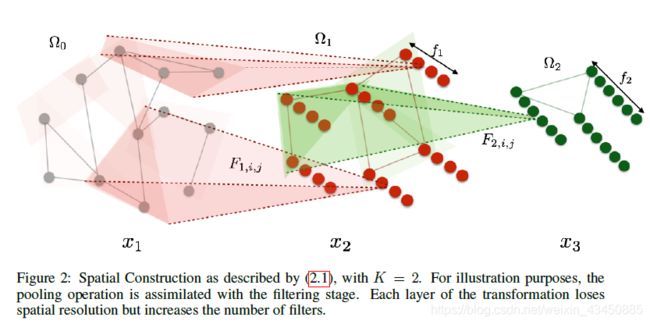
k =1时:
n u m ( Ω 0 ) = 12 , x 1 . s h a p e = ( 12 , f 0 ) , f 1 = 4 , F 1 , i , j . s h a p e = ( 12 , 12 ) , 1 ≤ i ≤ f 0 , 1 ≤ j ≤ f 1 , d 1 = 6 num(\Omega_{0})=12,x_{1}.shape=(12,f_{0}),f_{1}=4,F_{1,i,j}.shape=(12,12),1 \leq i \leq f_{0},1 \leq j \leq f_{1},d_{1}=6 num(Ω0)=12,x1.shape=(12,f0),f1=4,F1,i,j.shape=(12,12),1≤i≤f0,1≤j≤f1,d1=6
k =2时:
n u m ( Ω 1 ) = d 1 = 6 , x 2 . s h a p e = ( 6 , f 1 ) , f 2 = 6 , F 2 , i , j . s h a p e = ( 6 , 6 ) , 1 ≤ i ≤ f 1 = 4 , 1 ≤ j ≤ f 2 , d 2 = 3 num(\Omega_{1})=d_{1}=6,x_{2}.shape=(6,f_{1}),f_{2}=6,F_{2,i,j}.shape=(6,6),1 \leq i \leq f_{1}=4,1 \leq j \leq f_{2},d_{2}=3 num(Ω1)=d1=6,x2.shape=(6,f1),f2=6,F2,i,j.shape=(6,6),1≤i≤f1=4,1≤j≤f2,d2=3
网络输出:
x 3 . s h a p e = ( d 2 , f 2 ) = ( 3 , 6 ) x_{3}.shape=(d_{2},f_{2})=(3,6) x3.shape=(d2,f2)=(3,6)
3.频域结构
离散域的卷积公式: ( f ∗ g ) = ∑ τ = − ∞ ∞ f ( τ ) g ( n − τ ) (f*g)=\sum_{\tau=-\infty}^{\infty}{f(\tau)g(n-\tau)} (f∗g)=∑τ=−∞∞f(τ)g(n−τ)
离散傅里叶变换公式(DFT): X ( k ) = F ( x ( n ) ) = ∑ n = 0 N − 1 x ( n ) e − j k 2 π N n X(k)=F(x(n))=\sum_{n=0}^{N-1}{x(n)e^{-jk\frac{2\pi}{N}n}} X(k)=F(x(n))=∑n=0N−1x(n)e−jkN2πn , k ∈ [ 0 , N − 1 ] k\in[0,N-1] k∈[0,N−1],表示的是 x ( n ) x(n) x(n)与 { e − j k 2 π N n } \{e^{-jk\frac{2\pi}{N}n}\} { e−jkN2πn}的内积,也可以认为是将 x ( n ) x(n) x(n)映射为 { e − j k 2 π N n } \{e^{-jk\frac{2\pi}{N}n}\} { e−jkN2πn}基向量空间的 X ( k ) X(k) X(k)。
离散傅里叶逆变换公式(IDFT): x ( n ) = F − 1 ( X ( k ) ) = 1 N ∑ k = 0 N − 1 X ( k ) e j k 2 π N n x(n) = F^{-1}(X(k))=\frac{1}{N}\sum_{k=0}^{N-1}{X( k)e^{jk\frac{2\pi}{N}n}} x(n)=F−1(X(k))=N1∑k=0N−1X(k)ejkN2πn , n ∈ [ 0 , N − 1 ] n\in[0,N-1] n∈[0,N−1]。
由于时域卷积等于频域相乘,所以卷积公式的频域表达:
( f ∗ g ) = F − 1 [ F [ f ] ⨀ F [ g ] ] (4) (f*g)=F^{-1}[F[f]\bigodot F[g]]\tag{4} (f∗g)=F−1[F[f]⨀F[g]](4)
⨀ \bigodot ⨀表示哈达玛乘积,指的是两个矩阵(或向量)的逐点乘积。
在图网络中,定义了度矩阵 D D D, D D D为对角矩阵,对角线上的值为各个节点连接的边的数目, W W W为图的邻接矩阵,图中的拉普拉斯矩阵定义为 L = D − W L=D-W L=D−W,对 L L L进行矩阵的特征分解,得到: L = V Λ V T L=V\Lambda V^{T} L=VΛVT, V = ( v 1 , . . . , v i , . . . v n ) , v i V=(v_{1},...,v_{i},...v_{n}),v_{i} V=(v1,...,vi,...vn),vi是 L L L的特征向量, Λ = d i a g ( λ 1 . . . λ i . . . λ n ) \Lambda=diag(\lambda_{1}...\lambda_{i}...\lambda_{n}) Λ=diag(λ1...λi...λn), λ i \lambda_{i} λi是 L L L的特征值。所以:
L v i = λ i v i (5) Lv_{i}=\lambda_{i}v_{i}\tag{5} Lvi=λivi(5)
而所有的基向量 { e − j k 2 π N n } \{e^{-jk\frac{2\pi}{N}n}\} { e−jkN2πn}都满足亥姆霍兹方程(Helmholtz Equation):
∇ 2 f = ∂ 2 e − j k 2 π N n ∂ n 2 = − ( k 2 π N ) 2 e − j k 2 π N n = − w 2 f (6) \nabla^{2}f=\frac{\partial^{2} e^{-jk\frac{2\pi}{N}n}}{\partial n^{2}}=-(k\frac{2\pi}{N})^{2}e^{-jk\frac{2\pi}{N}n}=-w^{2}f\tag{6} ∇2f=∂n2∂2e−jkN2πn=−(kN2π)2e−jkN2πn=−w2f(6)
∇ 2 \nabla^{2} ∇2是拉普拉斯算子, e − j k 2 π N n e^{-jk\frac{2\pi}{N}n} e−jkN2πn是拉普拉斯算子 ∇ 2 \nabla^{2} ∇2的特征函数, − w 2 -w^{2} −w2是特征函数的特征值。
将式(5)和式(6)对比,可知: e − j k 2 π N n e^{-jk\frac{2\pi}{N}n} e−jkN2πn~ v i v_{i} vi, − w 2 -w^{2} −w2 ~ λ i \lambda_{i} λi。
用 f f f表示时域信号, f ^ \hat{f} f^表示相应的频域信号,将这两个类比带入离散傅里叶变换的公式,得到:
f ^ ( k ) = ∑ n = 0 N − 1 f ( n ) e − j k 2 π N n = ∑ n = 0 N − 1 f ( n ) v k ( n ) = v k T f (7) \hat{f}(k) =\sum_{n=0}^{N-1}{f(n)e^{-jk\frac{2\pi}{N}n}}=\sum_{n=0}^{N-1}{f(n)v_{k}(n)}= v_{k}^{T}f\tag{7} f^(k)=n=0∑N−1f(n)e−jkN2πn=n=0∑N−1f(n)vk(n)=vkTf(7)
由式(7)可知:
f ^ = V T f (8) \hat{f}=V^{T}f\tag{8} f^=VTf(8)
将式(8)带入卷积公式得:
( g ∗ f ) = V [ V T g ⨀ V T f ] (9) (g*f)=V[V^{T}g\bigodot V^{T}f ]\tag{9} (g∗f)=V[VTg⨀VTf](9)
由于 V T g = ( v 1 T g , . . . , v n T g ) T V^{T}g=(v_{1}^{T}g,...,v_{n}^{T}g)^{T} VTg=(v1Tg,...,vnTg)T,所以 V T g ⨀ V T f = d i a g ( v 1 T g , . . . , v n T g ) V T f V^{T}g\bigodot V^{T}f=diag(v_{1}^{T}g,...,v_{n}^{T}g)V^{T}f VTg⨀VTf=diag(v1Tg,...,vnTg)VTf,令 g θ = d i a g ( v 1 T g , . . . , v n T g ) g_{\theta}=diag(v_{1}^{T}g,...,v_{n}^{T}g) gθ=diag(v1Tg,...,vnTg),所以 ( g ∗ f ) ( n ) = V g θ V T f (10) (g*f)(n)=Vg_{\theta}V^{T}f\tag{10} (g∗f)(n)=VgθVTf(10)
论文中所给的频域公式为:
x k + 1 , j = h ( V ∑ i = 1 f k − 1 F k , i , j V T x k , i ) (11) x_{k+1,j}=h(V\sum_{i=1}^{f_{k-1}}{F_{k,i,j}V^{T}x_{k,i}})\tag{11} xk+1,j=h(Vi=1∑fk−1Fk,i,jVTxk,i)(11)
在式(11)中 F k , i , j F_{k,i,j} Fk,i,j就是 g θ g_{\theta} gθ, x k , i 就 是 f x_{k,i}就是f xk,i就是f, f f f相当于输入信号 x x x的一个通道的信号。所以在每个通道求完卷积后,将结果累加,得到输出结果的一个通道的值。 x k , i x_{k,i} xk,i表示第k层所有节点的第i个特征拼接形成的向量。 F k , i , j F_{k,i,j} Fk,i,j表示第k层第j个滤波器的i个值的频域表示(类比于传统卷积的第 j j j个卷积核的第 i i i个通道), h ( ∗ ) h(*) h(∗)依然是非线性激活函数。
论文其他内容:
(1)经常情况下,V只有前d个特征向量起作用,因此取前d个特征向量,以减少参数。
(2)通过样条差值的方法,近似的求出这个操作的解,而使权值参数减少到O(1)。
(3)实验部分。