Python-7:几个小Trick
几个小Trick
今天上套路,需要自取。如有疑问,可待讨论。
1. Jieba 词频统计
在如下程序中,bugs1.csv 为源数据,仅有一列,内容为客户评论的文本数据。每一行对应一条评论。输出的wf1.csv 包含三列:前1000个重要的词、词频和有该词出现的总行数。
import pandas as pd
import jieba
import jieba.analyse as anl
#以str格式读入
str_text=open(u'C:/Users/houshunqi/Desktop/bugs1.csv',encoding='gbk',errors='ignore').read()
str_cut=jieba.cut(str_text,cut_all=True)
seg = anl.extract_tags(str_text, topK = 1000, withWeight = True)
#得到词和词频
dflist=pd.DataFrame(seg)
dflist.columns=["word","freq"]
#以DataFrame格式读入
df=pd.read_csv(u'C:/Users/houshunqi/Desktop/bugs1.csv',encoding='gbk')
#统计有该词出现的行数
con=[]
for i in dflist.index:
con.append(len(df[df["psubject"].str.contains(dflist.loc[i]["word"])]))
dflist["con"]=con
#保存结果
dflist.to_csv(u'C:/Users/houshunqi/Desktop/wf1.csv')
2. 中文自然语言文本格式转化
本人实战时,为了应用CountVectorizer(),将自然语言文本预先转化为类似于英文:word+" "+word 的格式。以下代码能实现此效果。如有更好方式,欢迎大佬们提出。
rowd=[]
for indexs in df.index:
rowData=" ".join(set(jieba.cut(str(df.loc[indexs].values[0]),cut_all=True)))
rowd.append(rowData)
df[u'describe']=rowd
3. 二维调参的全局最优
如下代码可建立SVM模型,并对测试集大小和随机种子调整,以观测模型性能。
a=[]
model=LinearSVC()
for i in range(1,40):
b=[]
for j in range(1,40):
#df[u'describe']为经上述处理后的文本,df['emotion']为情感标签
X_train, X_test, y_train, y_test = train_test_split(df[u'describe'], df['emotion'], test_size=i/100,random_state = j)
count_vect = CountVectorizer()
X_train_counts = count_vect.fit_transform(X_train)
tfidf_transformer = TfidfTransformer()
X_train_tfidf = tfidf_transformer.fit_transform(X_train_counts)
clf = LinearSVC().fit(X_train_counts, y_train)
ypred=list()
for k in X_test.index:
ypreda=clf.predict(count_vect.transform([X_test[k]]))
ypreda=ypreda[0]
ypred.append(ypreda)
b.append(np.mean(ypred == y_test))
#print("j=%d" %j)
print("i=%d" %i)
a.append(b)
#绘制三维图
from mpl_toolkits.mplot3d import Axes3D
X=np.arange(1,40,1)
Y=np.arange(1,40,1)
Z=a
fig = plt.figure()
ax = Axes3D(fig)
ax.plot_surface(X, Y, Z, cmap='rainbow')
ax.set_title('Accuracy')
plt.ylabel('random_state',rotation=60,horizontalalignment='right',verticalalignment='center')
plt.xlabel('test_size*100+1')
plt.show()
#寻找三维图的最大值
c=[]
max_row=[]
for m in range(len(a)):
c.append(max(a[m]))
max_row.append(np.where(a[m]==np.max(a[m])))
findmax=pd.DataFrame(max_row,c)
findmax=findmax.reset_index()
findmax.columns=["accuracy","random_state"]
#全局最优点
np.where(a==np.max(a))
三维图如下:
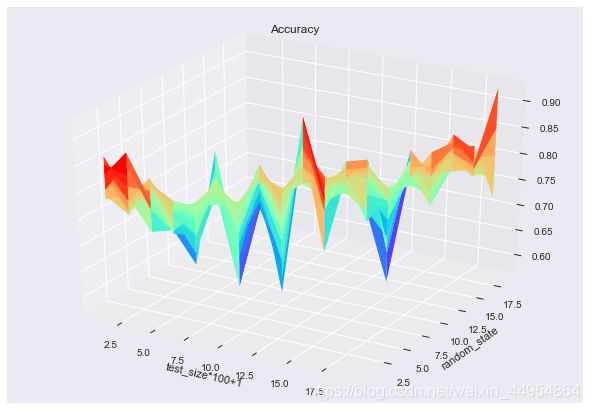
效果海星,不用换模型惹。还可以从findmax(DataFrame)找到最优值。由于循环从1开始,append后的index从0开始,index即 test_size* 100-1。accuracy为相应的test_size* 100-1后的最大准确率,index列为最大值对应的random_state集合。所以test_size=0.16 对应的最大 accuracy为0.824,在random_state=8 时取得。

当然,也可以换成其他参数。
Python语言系列我不知道还能写什么了,欢迎看官们提需求。(也可以换主题 0w0)