Spark机器学习-Java版(二)-相关系数和假设检验
1、相关系数和假设校验概述
相关系数和假设检验是数理统计中的基本概念和统计工具,对于机器学习模型的设定和优化策略有很大帮助。
1.1 相关系数
相关系数是反映两变量间线性相关性关系的統计指标,是一种反映变量之间相关关系密切程度的统计指标,在现实中一般用于对于两组数据的拟合和相似程度进行定量化分析,第用的般是皮尔逊相关系数( pearson),MLlib中默认的相关系数求法也是皮尔逊相关系数法,另还支持斯皮尔曼等级相关系数( spearman)。皮尔逊相关系的值是一个1≤ρxy≤1的数,用以判定两个变量变化是同向还是反向,以便观察这两个变量是呈现正相关还是负相关,甚至为0时的”相互独立”,其数学公式为:

即两变量的协方差除以其标准差,极大程度上规避了单用协方差无法体现相关性的劣势。
斯皮尔曼等级相关系数的公式如下:
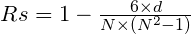
该相关系数没有皮尔逊那么严格。
皮尔逊相关系数代表随着数据量的増加,两组数据的差别将増大,而斯皮尔曼相关系数更注重两组数据的拟合程度,即两组数据随着数据量的増加而増长曲线不变。
1.2 假设校验
假设检验是一种依据一定假设条件计算样本某种并判断是否符合总体规律,或判断两个样本之间是否存在独立性的统计学理论。假设检验的基本思想是小概率反证法思想,小概率思想认为小概率事件在一次实验中基本不可能发生,因此在假设检验中,我们通常先假定一个假设Ho,然后选择它的相反项为螽择假设H1,通常以α=005作为小概率事件的界定线,称之为显著性水平,通过我们的样本数据计算出一个概率值p,如果p≤0.05,那么认为H0是会发生的,也就是说H0的发生是小概率事件,也就是认为当p ≤ 0.05时,否定原假设H0
常用的假设检验法有T检验,z检验,卡方检验和F检验。
卡方检验的一种常用的假设检验方法, Spark MLlib目前支持皮尔逊卡方检测,包括“适配度检定”( Goodness of fit)和“独立性检定"( independence)。其中适配度检定是指样本的发生次数(实际值)分配是否服从母体的次数分配(期望),独立性检定偏向于两类变量之间的关系是否居于相关性。
适配度检定举例:全世界上千万人统计人类出生时男孩和女孩的几率是一样的,某医院对2018年100名新生婴儿的性别做了统计,男孩56个,女孩44个,以此判定这个样本是否符合母体的分配规律。
独立性检定举例:性别和习惯用左右手是否有关。
2、调用方式
2.1 相关系数
依据我们输入的类型不同,则其对应的输出类型也不同,如果我们输入的是两个 JavaRDD
生成pearson相关系数:
//输入的seriesX,seriesY是两组JavaRDD类型的数据,代表两个不同的变量
//输出的类型是double
Statistics.corr(seriesX, seriesY,”pearson”);
生成spearman相关系数:
//输入的seriesX,seriesY是两组JavaRDD类型的数据,代表两个不同的变量
//输出的类型是double
Statistics.corr(seriesX, seriesY,”spearman”); 生成pearson相关系数矩阵和spearman相关系数矩阵:
//输入的类型为RDD
Statistics.corr(data,”pearson”);
Statistics.corr(data,” spearman”); 2.2 假设检验
做适配度检定和独立性检定时,需要输入的参数关型不同,适配度检定要求输入的是 Vector.独立性检定要求输入的是Matrix。调用的API是 Statistics.chiSqTest();
配度检定:这里依旧引用上例,新生婴儿的性别是否符合母体规律,(样本为2018年100名新生妥儿的性别做了统计,男孩56个,女孩44个)
Vector v = Vectors.dense(new double[]{56,44});
ChiSqTestResult result = Statistics.chiSqTest(v);独立性检定
原始数据表达:
| 男 | 女 | 小计 | |
| 右手 | 43 | 44 | 87 |
| 左手 | 9 | 4 | 13 |
| 小计 | 52 | 48 | 100 |
//这里要注意矩阵是按列优先填充的,故数据要以列的形式写入
Matrix matrix = Matrixs.dense(2,2,new double[]{43.0,9.0,44.0,4.0});
Statistics.chiSqTest(matrix);3、 Spark中的实践应用
3.1 相关系数的应用
原始文件内容:(文件名为: correlations txt,存放在 src/main/resources),第一列是凝血酶浓度(单位升),第二列是凝血时间(秒),下面探究这两者之间的相性如何?
1.1 14
1.2 13
1.0 15
0.9 15
1.2 13
1.1 14
0.9 16
0.9 15
1.0 14
0.9 16
1.1 15
0.9 16
1.0 15
1.1 14
0.8 17
相关系数代码实现:
Sparkconf conf = new SparkConf().setMaster("local").setAppName("Correlations");
JavasparkContext jsc = new JavaSparkContext(conf);
JavaRDD lines = jsc.textFile("src/main/resources/correlations.txt");
//将源文件读取进来的第一列作为第一个变量
JavaRDD seriesX =lines.map(x ->x split(" ")).map(x->Double.parseDouble(x[0]));
//将源文件读取进来的第二列作为第二个变量
JavaRDD seriesY =lines.map(x ->x split(" ")).map(x->Double.parseDouble(x[1]));
//调用Statistics包下的corr()即可得到皮尔逊相关系数
double corr = Statistics.corr(seriesX,seriesY,"pearson");
//结果是-0.907,表名两个变量呈现负相关趋势,即一方增高一方降低
System.out.println(corr);
//获取斯皮尔相关系数
double corr2 = Statistics.corr(seriesX,seriesY,"spearman");
//结果是-0.894
System.out.println(corr); 相关系数矩代码实现:
Sparkconf conf = new SparkConf().setMaster("local").setAppName("Correlations");
JavasparkContext jsc = new JavaSparkContext(conf);
JavaRDD lines = jsc.textFile("src/main/resources/correlations.txt");
JavaRDD data =lines.map(x->x split(" ")).map(x ->Vectors. dense(Double. parseDouble(x[0]), Double. parseDouble(x[1])));
//将JavaRDD转化为RDD
RDD data2 = data.rdd();
//调用Statistics包下的corr()得到皮尔逊相关系数矩阵
Matrix corr = Statistics.corr(data2,"pearson");
//结果是
//1.0 -0.9069678578088085
//-0.9069678578088085 1.0
/获取斯皮尔曼相关系数矩阵
Matrix corr = Statistics.corr(data2,"spearman");
//结果是:
//1.0 -0.8942857152857139
// -0.8942857152857139 1.0 3.2 假设检验的应用
3.2.1 适合度检验
背景:只要是质量合格的骰子掷出1~6的几率就应该是相同的,现在有一枚骰子掷出600次,统计出1~6的次数如下:90,85,123,91,86,125,判定该骰子是否有质
原假设Ho:骰子没有问题
显著性水平:a=0.05
代码实现:(如果做适配度检验, Statistics. chiSqTest(v)需要输入的是一个向量)
Sparkconf conf = new SparkConf().setMaster("local").setAppName("GoodnessOfFit");
JavasparkContext jsc = new JavaSparkContext(conf);
//做适配度检定是需要的参数是一个Vector
Vector v = Vectors. dense(new double[] {90, 85, 123, 91, 86, 125});
ChiSqTestResult result = Statistics.chiSqTest(v);
System.out.println(result);
结果显示:
Chi squared test summary:
method: pearson
degrees of freedom = 5
statistic = 17.56
pvalue=0.0035515235818343554
每一个值的输出含义:
method:使用的方法,用的是皮尔逊卡方检验法
degrees of freedom:自由度,一般为样本个数减1
statistic:检验统计量,一个用来决定是否可以拒绝原假设的证据,该值越大表示可以绝句原假设的理由越充分
pValue:根据显著性检验方法得到的一个概率p值,该值<=0.05为显著,通常这个值小于等于0.05,便认为有充足理由可以拒绝原假设
这里的pValue = 0.00355 <= 0.05,则拒绝原假设,说明该骰子有问题。3.2.2 独立性检定
显著性水平:α = 0.05
代码实现:(如果做独立性检验, Statistics. chiSqTest()需要输入的是一个矩阵)
Matrix m = Matrixs.dense(2,2,new double[]{43.0,9.0,44.0,4.0});
//做独立性检验时需要的参数为Matrix
System.out.println(Statistics.chiSqTest(m));
结果为:
Chi squared test summary:
method: pearson
degrees of freedom = 1
statistic = 1.7774150400145103
pvalue=0.1824670652605519
里 pvalue=0.182>0.05,表明可以接受原假设,即说明性别和惯用左右手没有关系。