Python 自动化之 UnitTest 框架实战
文章目录
-
- 1 UnitTest 基本用法
-
- 1.1 UnitTest 初体验
- 1.2 UnitTest 自动化实现实战
- 2 UnitTest 结合 DDT(data-driver tests) 自动化
-
- 2.1 ddt 中的 data 与 unpack
- 2.2 ddt 数据驱动
- 3 yml 文件的使用
- 4 UnitTest 断言用法
- 5 UnitTest.skip()用法
- 5 UnitTest测试套件及runner应用
- 6 UnitTest+HTMLTestRunner 自动化实现
1 UnitTest 基本用法
UnitTest 框架是 Python 自带的一个作为单元测试的测试框,相当于 Java中的 JUnit,随着自动化技术的成熟,UnitTest 成为了测试框架第一选择,可以完整的结合 Selenium、Requests 来实现 Ul 和接口的自动化,由 UnitTest 再衍生出 PyTest,PyTest 可以完美结合 UnitTest 来实现自动化。
基本应用:
- 环境搭建,Python 中已经直接加载了 UnitTest 框架,无须额外安装
- 四大组件:
a. test fixture:setUp(前置条件)、tearDown(后置条件),用于初始化测试用例及清理和释放资源
b. test case:测试用例,通过集成 unttest.TestCase,来实现用例的继承,在 Unitfest 中,测试用例都是通过 test 来识别的,测试用例命名 test_XXX
c. test suite:测试套件,也称之为测试用例集
d. test runner:运行器,一般通过 runner 来调用 suite 去执行测试 - UnitTest 运行机制:通过在 main 函数中,调用 unitest.main() 运行所有内容
1.1 UnitTest 初体验
本节知识:1. 对 UnitTest 有直观感受
讲了这么多,也完全不明白,没关系,通过实例先有个直观的了解,UnitTest 是个什么东西
import unittest
# 通过继承 unittest。TestCase 来实现用例
class forTest(unittest.TestCase):
# 类的初始化
@classmethod
def setUpClass(cls) -> None:
print('class')
# 类的释放
@classmethod
def tearDownClass(cls) -> None:
print('tclass')
# 测试用例初始化
def setUp(self) -> None:
print("setUp")
# 测试用例释放
def tearDown(self) -> None:
print("teadDown")
# 测试用例
def test_a(self):
print("a")
# 测试用例
def test_b(self):
print("b")
# 函数
def add(self, a, b):
return a + b
# 测试用例
def test_c(self):
c = self.add(1, 3)
print('c =', c)
if __name__ == "__main__":
unittest.main(verbosity=2) # 参数 verbosity=2 的目的是为了让打印的信息更加完整,也可以不要
对上面的程序进行讲解:
-
类的初始化与释放
- def setUpClass(cls) -> None 表示类的初始化,在执行测试用例之前执行,只执行一次,函数参数为 cls 表示这是一个类方法
- def tearDownClass(cls) -> None 表示类的释放,在执行测试用例之后执行,只执行一次
-
测试用例的初始化与释放
- def setUp(self) -> None 用于测试用例的初始化,在每个测试用例之前都会执行,有多少个测试用例,就会执行多少次
- def tearDown(self) -> None 用于测试用例释放,在每个测试用例执行之后执行,有多少个测试用例,就会执行多少次
注意:方法 setUpClass,tearDownClass,setUp,def tearDown 的方法名是固定的,不能改动,不然框架无法识别
-
测试用例的定义
- 测试用例的命名规则为 test_xxx,这样测试用例就会自动执行
注意:只有测试用例才会被执行,不以test_xxx 命名的函数是方法,方法是不能被执行的
-
执行测试用例
- 通过在 main 函数中,调用 unitest.main() 运行所有内容
运行结果如下:
- 类的初始化方法 setUpClass(cls) 在所有的测试用例之前执行,类的释放函数 tearDownClass(cls) 在所有的测试用例之后执行
- 测试用例的初始化在每个测试用例之前都会执行,测试用例的释放在每个测试用例之后都会执行
- test_a(self) 和 test_b(self) 是测试用例,运行时被自动执行,add(self, a, b) 是函数,不会被自动执行,test_c(self) 是测试用例,调用了 add 函数,这样就可以执行 add 函数了。
class
setUp
a
teadDown
setUp
b
teadDown
setUp
c = 4
teadDown
tclass
相信有了上面的例子,已经对UnitTest 有了一个初步的印象。
下面我们进行一个实战操作
1.2 UnitTest 自动化实现实战
本节知识:1. 自动化测试减少冗余,便于维护,2. ddt数据驱动
- 自动化测试减少冗余,便于维护
- 有了类的初始化与释放,测试用例的初始化与释放,我们可以将多个测试用例中相同的代码提取出来,减少自动化测试冗余,这样便于维护
下面看这样一个例子,我们打开谷歌浏览器,输入百度网址并进行搜索,搜索后关闭浏览器
#coding=utf-8
import unittest
from selenium import webdriver
import time
class forTest(unittest.TestCase):
# 测试用例初始化
# 打开谷歌浏览器,并进入百度
def setUp(self) -> None:
self.driver = webdriver.Chrome()
self.driver.get('http://www.baidu.com')
# 测试用例释放
# 等待 3s,关闭浏览器
def tearDown(self) -> None:
time.sleep(3)
self.driver.quit()
# 输入‘战狼’,并点击搜索
def test_1(self):
pass
self.driver.find_element_by_id('kw').send_keys('战狼')
self.driver.find_element_by_id('su').click()
# 输入‘红海行动’,并点击搜索
def test_2(self):
pass
self.driver.find_element_by_id('kw').send_keys('红海行动')
self.driver.find_element_by_id('su').click()
if __name__ == '__main__':
unittest.main()
上面的案例中,我们将打开谷歌浏览器,进入百度,放在 setUp 中,完成每个测试用例之前的初始化,浏览器的关闭放在tearDown 中,完成测试用例的释放
2 UnitTest 结合 DDT(data-driver tests) 自动化
2.1 ddt 中的 data 与 unpack
- 在实际测试中,单个测试是需要用多种不同的条件(测试数据)对其进行测试的。
- ddt 中最基本的应用;在 class 前定义 @ddt,用于表示要使用 ddt 了,再基于实际的应用。选择对应的装饰器来使用即可,说白了,就是一个装饰器
- data 用于设定参数
- unpack 用于解析参数
直接看例子比较直观
#coding=utf-8
import unittest
from ddt import ddt
from ddt import data # 导入data
# 类之前定义装饰器,表示在类中要使用ddt了
@ddt
class MyTestCase(unittest.TestCase):
def setUp(self) -> None:
print('{:=^20}'.format("测试开始"))
def tearDown(self) -> None:
print("{:=^20}".format('测试结束'))
# data用于设定参数
@data('战狼', '哪吒', '流浪地球', '复仇者联盟')
def test_1(self, txt):
print(txt)
if __name__ == '__main__':
unittest.main(verbosity=2)
运行结果:
========测试开始========
战狼
========测试结束========
========测试开始========
哪吒
========测试结束========
========测试开始========
流浪地球
========测试结束========
========测试开始========
复仇者联盟
========测试结束========
可以看到测试用例 def test_1(self, txt) 被执行了四次,data 用于设定参数,将参数依次放入测试用例中进行测试。
我们改变一下设定的参数,将 data 设定的参数改为 ((‘战狼’, ‘哪吒’), (‘流浪地球’, ‘复仇者联盟’)),再进行测试,如下所示
#coding=utf-8
import unittest
from ddt import ddt
from ddt import data
# 类之前定义装饰器,表示在类中要使用ddt了
@ddt
class MyTestCase(unittest.TestCase):
def setUp(self) -> None:
print('{:=^20}'.format("测试开始"))
def tearDown(self) -> None:
print("{:=^20}".format('测试结束'))
# data 用于设定参数,将包 ('战狼', '哪吒') 作为一个整体赋值给 txt
@data(('战狼', '哪吒'), ('流浪地球', '复仇者联盟'))
def test_1(self, txt):
print(txt)
if __name__ == '__main__':
unittest.main(verbosity=2)
运行结果如下:
========测试开始========
('战狼', '哪吒')
========测试结束========
========测试开始========
('流浪地球', '复仇者联盟')
========测试结束========
可以看到,传入参数 ((‘战狼’, ‘哪吒’), (‘流浪地球’, ‘复仇者联盟’)) 时,将包 (‘战狼’, ‘哪吒’) 和 (‘流浪地球’, ‘复仇者联盟’) 作为一个整体,传递给测试用例了,如果我们希望将包里面的数据解开,传递给测试用例不同的参数,就需要用到 unpack 进行解包。
加入解包后的代码如下所示:
#coding=utf-8
import unittest
from ddt import ddt
from ddt import data
from ddt import unpack # 导入unpack
# 类之前定义装饰器,表示在类中要使用ddt了
@ddt
class MyTestCase(unittest.TestCase):
def setUp(self) -> None:
print('{:=^20}'.format("测试开始"))
def tearDown(self) -> None:
print("{:=^20}".format('测试结束'))
@data(('战狼', '哪吒'), ('流浪地球', '复仇者联盟'))
# 解包,将 ('战狼', '哪吒') 解包,'战狼' 赋值给 txt1,'哪吒'赋值给 txt2
@unpack
def test_3(self, txt1, txt2):
print(txt1)
print(txt2)
if __name__ == '__main__':
unittest.main(verbosity=2)
执行结果如下:
========测试开始========
战狼
哪吒
========测试结束========
========测试开始========
流浪地球
复仇者联盟
========测试结束========
可以看到,unpack 对每次传入的包进行解包,例如将 (‘战狼’, ‘哪吒’) 解包,‘战狼’ 赋值给 txt1,'哪吒’赋值给 txt2
上面的例子中,我们将输入的参数直接固定了,其实也可以通过文件读取,读取结果决定
#coding=utf-8
import unittest
from ddt import ddt
from ddt import data
from ddt import unpack
def readFile():
params = []
file = open('ddt.txt', 'r', encoding = 'gbk')
for line in file.readlines():
params.append(line.strip('\n').split(','))
return params
# 类之前定义装饰器,表示在类中要使用ddt了
@ddt
class MyTestCase(unittest.TestCase):
def setUp(self) -> None:
print('{:=^20}'.format("测试开始"))
def tearDown(self) -> None:
print("{:=^20}".format('测试结束'))
# 从文件中读取
@data(*readFile())
@unpack
def test_1(self, txt1, txt2):
print(txt1)
print(txt2)
if __name__ == '__main__':
unittest.main(verbosity=2)
ddt.txt 文件中的内如下:
战狼,哪吒
流浪地球,复仇者联盟
运行结果:
函数 readFile 从文件中读取数据,unpack 进行解包
========测试开始========
战狼
哪吒
========测试结束========
========测试开始========
流浪地球
复仇者联盟
========测试结束========
上面从文件中读取数据时先读取文件,再处理读取的结果,下面介绍一个直接操作文件的方法
从 ddt 中导入 file_data,导入 yaml,读取数据的文件类型必须为 .yml 类型的文件。
#coding=utf-8
import unittest
from ddt import ddt
from ddt import data
from ddt import unpack
from ddt import file_data
import yaml
# 类之前定义装饰器,表示在类中要使用ddt了
@ddt
class MyTestCase(unittest.TestCase):
def setUp(self) -> None:
print('{:=^20}'.format("测试开始"))
def tearDown(self) -> None:
print("{:=^20}".format('测试结束'))
# 直接的文件读取,直接操作一个文件
@file_data('ddt2.yml')
def test_5(self, txt):
print(txt)
if __name__ == '__main__':
unittest.main(verbosity=2)
ddt2.yml 文件内容如下:
name: 'skx'
info: 'hust'
运行结果:
========测试开始========
skx
========测试结束========
========测试开始========
hust
========测试结束========
2.2 ddt 数据驱动
打开浏览器进入百度查询的例子中我们发现除了输入的参数不同,test_1(self) 和 test_2(self) 完全相同,这里我们就要通过 data 设定参数实现在一个测试用例中输入不同的参数
#coding=utf-8
import unittest
from selenium import webdriver
import time
from ddt import ddt
from ddt import data
# 在 class 前定义 @ddt,用于表示要使用 ddt 了
@ddt
class forTestTest(unittest.TestCase):
def setUp(self):
self.driver = webdriver.Chrome()
self.driver.get('http://www.baidu.com')
def tearDown(self):
time.sleep(3)
self.driver.quit()
# data 用于设定参数
@data('战狼', '哪吒', '流浪地球')
def test_1(self, txt):
self.driver.find_element_by_id('kw').send_keys(txt)
self.driver.find_element_by_id('su').click()
if __name__ == "__main__":
unittest.main()
运行结果,谷歌浏览器被打开三次,进入百度,分别输入 ‘战狼’, ‘哪吒’, ‘流浪地球’,每次浏览器关闭之后,才打开下一次,再进行搜索
上面的例子中,我们将输入的参数直接固定了,其实也可以通过文件读取,决定进入哪一个 url 和输入的参数
#coding=utf-8
import unittest
from selenium import webdriver
import time
from ddt import ddt
from ddt import data
from ddt import unpack
def readFile():
params = []
file = open('forTest3.txt', 'r', encoding = 'gbk')
for line in file.readlines():
params.append(line.strip('\n').split(','))
return params
@ddt
class forTestTest(unittest.TestCase):
def setUp(self):
self.driver = webdriver.Chrome()
def tearDown(self):
time.sleep(3)
self.driver.quit()
# data 用于设定参数,表示参数由 readFile() 函数的返回值决定
# unpack 用于解析参数,例如将['http://www.baidu.com', '战狼'] 分别 赋值给 url 和 txt
@data(*readFile())
@unpack
def test_1(self, url, txt):
self.driver.get(url)
self.driver.find_element_by_id('kw').send_keys(txt)
self.driver.find_element_by_id('su').click()
if __name__ == "__main__":
unittest.main()
forTest3.txt 文件中的内容如下:
http://www.baidu.com,战狼
http://www.baidu.com,哪吒
分析:
- readFile() 函数打开文件,读取文件的每一行,按逗号 ‘,’ 划分关键字,
- unpack 用于解析参数,ddt 对于数据的解析方式为,解析一个,传参一个,所以函数中 url 和 txt 的参数顺序不能调换。
运行结果,谷歌浏览器被打开两次,进入百度,分别输入 ‘战狼’, ‘哪吒’,每次浏览器关闭之后,才打开下一次,再进行搜索
file_data 是 ddt 中用于读取 yml 文件的装饰器
3 yml 文件的使用
这个插入一个小插曲,上面提到了 yml 文件,这里就简单讲解一下 yml 文件怎么使用。
从yml 文件中直接读取数据可以生成字典,列表等,yml 文件由一定的格式,我们通过实例来说明,yml_test.py 从 a.yml 文件中读取文件并打印出来。
- yml_test.py
import yaml
file = open('a.yml', encoding = 'utf-8')
res = yaml.load(file, Loader = yaml.FullLoader)
print(res)
a.yml 文件中的内容如下所示,冒号代表字典,字典结构可以嵌套,也可以生成列表,具体格式参考下面的 a.yml 文件。
- a.yml
name: 'skx'
age: 18
data:
a: 1
b: 2
c: 3
d: 4
list:
- a
- b
- c
- d
打印的结果如下所示,生成四个字典元素,第三个字典元素为嵌套字典结构,第四个字典对应的 value 为列表。
{'name': 'skx', 'age': 18, 'data': {'a': 1, 'b': 2, 'c': 3, 'd': 4}, 'list': ['a', 'b', 'c', 'd']}
如果将 a.yml 文件中的数据改为如下结构,则生成一个纯列表,打印的结果如下所示。
- a.yml
- a
- b
- c
- d
['a', 'b', 'c', 'd']
有了 yml 文件,我们就可以将测试数据放到 yml 文件中,从文件中获取参数,传入测试函数,完成测试。还是通过例子来讲解,yml_test2.yml 中是一个列表,每个列表元素是一个字典,字典中有两个元素,name 和 age,使用 file_data 直接可以将 yml_test2.yml 传入测试用例中。
- read_yml2.py
#coding=utf-8
import unittest
from ddt import ddt
from ddt import file_data
import yaml
# 类之前定义装饰器,表示在类中要使用ddt了
@ddt
class MyTestCase(unittest.TestCase):
def setUp(self) -> None:
print('{:=^20}'.format("测试开始"))
def tearDown(self) -> None:
print("{:=^20}".format('测试结束'))
@file_data('read_yml2_data.yml')
def test_yam(self, **kwargs):
# 获取参数中key 为 name 的 value
print(kwargs["name"])
# 获取为 text 的 value
print(kwargs["age"])
if __name__ == '__main__':
unittest.main(verbosity=2)
- read_yml2_data.yml
-
name: 'Tom'
age: 13
-
name: 'Carl'
age: 20
-
name: 'Edward'
age: 28
运行结果:
========测试开始========
Tom
13
========测试结束========
========测试开始========
Carl
20
========测试结束========
========测试开始========
Edward
28
========测试结束========
4 UnitTest 断言用法
在 UnitTest中,TestCase 已经提供有封装好的断言方法进行断言校验。
断言:用于校验实际结果与预期结果是否匹型,在断言的内容选择上,是有要求的。
断言强调的是对于整个测试流程的结果进行判断,所以断言的内容是极为核心的。
上面的代码
#coding=utf-8
import unittest
from ddt import ddt
from ddt import file_data
import yaml
# 类之前定义装饰器,表示在类中要使用ddt了
@ddt
class MyTestCase(unittest.TestCase):
def setUp(self) -> None:
print('{:=^20}'.format("测试开始"))
def tearDown(self) -> None:
print("{:=^20}".format('测试结束'))
@file_data('read_yml2_data.yml')
def test_yam(self, **kwargs):
# 获取参数中key 为 name 的 value
name = kwargs['name']
print(name)
# 这里做断言,当断言不相等的时候返回 msg
self.assertEqual(name, 'Tom', msg = 'NotEqual')
# 获取为 text 的 value
print(kwargs["age"])
if __name__ == '__main__':
unittest.main()
-
name: 'Tom'
age: 13
-
name: 'Carl'
age: 20
-
name: 'Edward'
age: 28
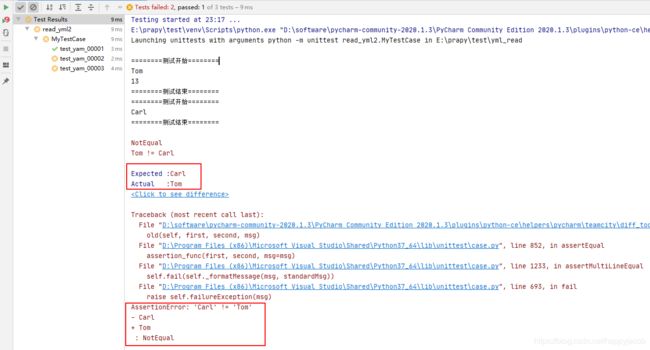
可以看到第一个例子执行正确,后面的例子,执行结果和预期不一致,返回 NotEqual,左侧的日志可以看到第一个用例执行成功,后面两个例子执行失败。
unittest 框架的 TestCase 类提供以下方法用于测试结果的判断
| 方法 | 检查 |
|---|---|
| assertEqual(a, b) | a ==b |
| assertNotEqual(a, b) | a !=b |
| assertTrue(x) | bool(x) is True |
| assertFalse(x) | Bool(x) is False |
| assertIs(a, b) | a is b |
| assertIsNot(a, b) | a is not b |
| assertIsNone(x) | x is None |
| assertIsNotNone(x) | x is not None |
| assertIn(a, b) | a in b |
| assertNotIn(a, b) | a not in b |
| assertIsInstance(a, b) | isinstance(a,b) |
| assertNotIsInstance(a, b) | not isinstance(a,b) |
5 UnitTest.skip()用法
假设我们有很多测试用例,有些我们需要执行,有些我们不想执行,不想执行的测试用例如何才能不执行呢,这就需要用到 skip。
Skip用法:
- 在 Case 中,对于不需要运行的用例或者特定条件下不执行的用例,可以应用 skip() 来实现有条件执行,或者绝对性跳过,用于对指定用例进行不执行操作
- skip通过装饰器进行使用
还是通过案例进行讲解,下面有 6 个测试用例,2-5测试用例被屏蔽了,使用的方法不同,
- @unittest.skip(“xxx”)是无条件跳过,xxx为跳过的理由
- unittest.skipIf(1 < 2, ‘xxx’),条件为 True 时跳过
- @unittest.skipUnless(1 > 2, ‘xxx’),条件为 False 时跳过,和 skipIf 更好相反
- @unittest.expectedFailure,如果用例执行失败,则不计入失败的case数中
直接看例子更加直观
- skip_t.py
#coding=utf-8
import unittest
class MyTestCase(unittest.TestCase):
def setUp(self) -> None:
pass
def tearDown(self) -> None:
pass
def test_1(self):
print('1')
# 无条件跳过该条用例
@unittest.skip("不想运行")
def test_2(self):
print('2')
# 有条件跳过操作,条件为True跳过
@unittest.skipIf(1 < 2, '1 < 2 为True,条件成立,跳过执行')
def test_3(self):
print('3')
# 有条件执行跳过,条件为False跳过
@unittest.skipUnless(1 > 2, 'Unless的理由,条件为False,跳过执行')
def test_4(self):
print('4')
# 如果用例执行失败,则不计入失败的case数中
@unittest.expectedFailure
def test_5(self):
print('5')
self.assertEqual(4, 3, msg = 'NotEqual')
def test_6(self):
print('6')
if __name__ == "__main__":
unittest.main()
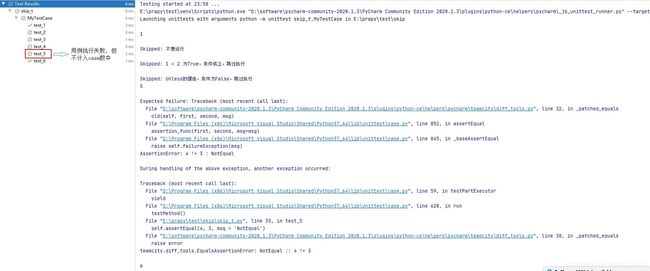
执行结果如下,可以看到,test_2,test_3,test_4 跳过,test_5执行失败,但是不计入case数中
5 UnitTest测试套件及runner应用
测试套件 Suite 作用:
- 用于给测试用例进行排序
- 管理测试用例
通过例子讲解最容易理解,看一个最简单的例子,下面的代码中有五个测试用例,程序运行的结果和测试用例在代码中位置是没有关系的,结果永远打印 1 2 3 4 5,这是因为测试用例的执行顺序默认是按照字典顺序执行的,如何才能控制测试用例的执行顺序呢,这就需要使用测试套件了。
- suite_case.py
import unittest
class MyTestCase(unittest.TestCase):
def setUp(self) -> None:
pass
def tearDown(self) -> None:
pass
def test_2(self):
print("2")
def test_1(self):
print("1")
def test_4(self):
print("4")
def test_3(self):
print("3")
def test_5(self):
print("5")
if __name__ == "__main__":
unittest.main()
运行结果:
1
2
3
4
5
再建一个py 文件
- for_suite.py
#coding=utf-8
import unittest
from suite_case import *
# 创建一个测试套件 list
suite = unittest.TestSuite()
# 方法一,添加测试用例(子元素)到测试套件(集合)
suite.addTest(MyTestCase('test_3'))
suite.addTest(MyTestCase("test_1"))
suite.addTest(MyTestCase("test_5"))
# 套件通过TextTestRunner对象运行,功能相当于unittest.main()
runner = unittest.TextTestRunner()
runner.run(suite)
我们首先创建一个测试套件,然后向测试套件中添加测试用例,最后创建 TextTestRunner 对象,调用 run 函数运行测试用例。这样我们不仅可以控制测试用例的执行顺序,还可以控制运行哪个测试用例。
结果如下:
3
1
5
上面的方法每次添加测试用例都需要调用 addTest 函数,能不能一次添加多个测试用例呢,可以的,将测试用例写成一个列表,通过addTests 函数可以一次添加多个测试用例
#coding=utf-8
import unittest
from suite_case import *
# 创建一个测试套件 list
suite = unittest.TestSuite()
# 方法二,批量添加测试用例
cases = [MyTestCase('test_3'), MyTestCase('test_1'), MyTestCase('test_5')]
suite.addTests(cases)
# 套件通过TextTestRunner对象运行,功能相当于unittest.main()
runner = unittest.TextTestRunner()
runner.run(suite)
如果测试用例非常多,或者有多个文件中的测试用例都需要测试,这样添加也不是很方便,我们好可以按照文件路径,将该路径下需要测试的文件添加进测试套件中
#coding=utf-8
import unittest
from suite_case import *
# 创建一个测试套件 list
suite = unittest.TestSuite()
# 方法三,批量运行多个unittest类
test_dir = './'
# start_dir 参数指定文件路径,pattern 执行规则,'s*.py' 表示以 "s" 开头,".py" 的都加入测试套件中
discover = unittest.defaultTestLoader.discover(start_dir = test_dir, pattern = 's*.py')
runner = unittest.TextTestRunner()
runner.run(discover) # 通过 run 函数运行测试用例
还可以执行类的名字,执行该类下面所有的测试用例,使用 loadTestsFromName 函数或者 loadTestsFromTestCase 都可以,案例如下:
#coding=utf-8
import unittest
from suite_case import *
# 创建一个测试套件 list
suite = unittest.TestSuite()
# 方法四,给出文件名和类名,就能测试所有的测试用例
suite.addTests(unittest.TestLoader().loadTestsFromName('suite.MyTestCase'))
# 套件通过TextTestRunner对象运行,功能相当于unittest.main()
runner = unittest.TextTestRunner()
runner.run(suite)
#coding=utf-8
import unittest
from suite_case import *
# 创建一个测试套件 list
suite = unittest.TestSuite()
# 方法五,给出类名,就能测试所有的测试用例
suite.addTests(unittest.TestLoader().loadTestsFromTestCase(MyTestCase))
# 套件通过TextTestRunner对象运行,功能相当于unittest.main()
runner = unittest.TextTestRunner()
runner.run(suite)
6 UnitTest+HTMLTestRunner 自动化实现
通过 HTMLTestRunner 我们可以将测试结果生成 html 文件,通过网页端进行查看。步骤如下:
1. 导入环境
下载 HTMLTestRunner.py 文件,下载地址
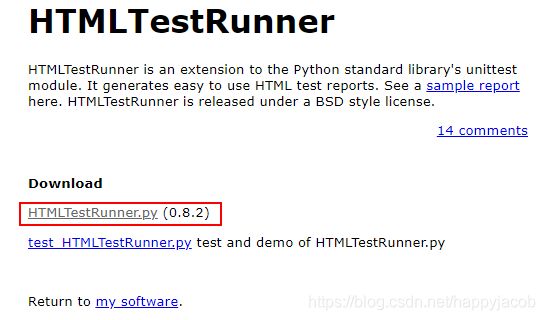
点进入HTMLTestRunner.py,右键另存为就可以下载到本地。
下载后,把HTMLTestRunner.py 文件复制到 Python 安装路径下的 lib 文件夹中(我的安装路径是:C:\Users\Administrator\AppData\Local\Programs\Python\Python38\Lib)。在python3中用HTMLTestRunner.py 报 importError“:No module named 'StringIO’解决办法,原因是官网的是python2语法写的,看官手动把官网的 HTMLTestRunner.py 改成 python3 的语法。
修改内容:
- 第94行,将import StringIO修改成import io
- 第539行,将self.outputBuffer = StringIO.StringIO()修改成self.outputBuffer = io.StringIO()
- 第642行,将if not rmap.has_key(cls):修改成if not cls in rmap:
- 第631行,将print >> sys.stderr, ‘\nTime Elapsed: %s’ % (self.stopTime-self.startTime)修改成print(sys.stderr, ‘\nTime Elapsed: %s’ % (self.stopTime-self.startTime))
- 第766行,将uo = o.decode(‘latin-1’)修改成uo = e
- 第772行,将ue = e.decode(‘latin-1’)修改成ue = e
2. 导包
from HTMLTestRunner import HTMLTestRunner
下面就通过案例进行演示
- suite_case.py 文件
import unittest
class MyTestCase(unittest.TestCase):
def setUp(self) -> None:
pass
def tearDown(self) -> None:
pass
def test_2(self):
print("2")
def test_1(self):
print("1")
def test_4(self):
print("4")
def test_3(self):
print("3")
def test_5(self):
print("5")
if __name__ == "__main__":
unittest.main()
- create_html_res.py
#coding=utf-8
import unittest
from suite_case import MyTestCase
from HTMLTestRunner import HTMLTestRunner
import os
suite = unittest.TestSuite()
report_path = './report/'
report_file = report_path + 'report.html'
# 路径不存在就创建一个文件夹
if not os.path.exists(report_path):
os.mkdir(report_path)
else:
pass
report_name = '测试报告名称'
report_title = '测试报告标题'
report_desc = '测试报告描述'
with open(report_file, 'wb') as report:
suite.addTests(unittest.TestLoader().loadTestsFromTestCase(MyTestCase))
# 套件结合 TextTestRunner 对象进行运行,相当于 unittest.mian()
# 如果结合 HTMLTestRunner 使用,则需要调用 HTMLTestRunner 中的运行器
runner = HTMLTestRunner(stream = report, title = report_title, description = report_desc)
runner.run(suite)
运行 就会成成 report.html 文件,浏览器打开该文件,如下所示:
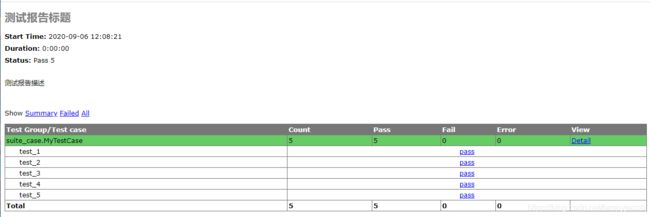
这样就生成一个比较直观的测试报告