Deep Interest Network for Click-Through Rate Prediction
ABSTRACT
现有CTR常用的DNN架构中将用户特征表示为一个固定长度的embedding向量。固定长度会导致网络很难从用户的历史行为中学习到用户的多种兴趣。文中提出了DIN网络来解决这个问题,该网络设计了一个局部激活单元来自适应地从和某个广告相关的历史行为中学习用户兴趣。这个表示向量会因广告而异,极大地提高了模型的表达能力。此外,作者开发了两种技术:mini-batch aware regularization and data adaptive activation function ,帮助训练工业级的网络。
INTRODUCTION
作者介绍了常用的DNN模型使用固定长度向量表示用户的局限性。以电商网站广告为例,用户兴趣具有多样性。但是如果增加维度来表示用户,那么参数量增大,过拟合风险增加,同时增加计算和存储成本。
另一方面,也没有必要在预测一个广告时将用户所有兴趣都压缩到一个向量中,因为可能只有部分兴趣和该广告有关。据此,作者提出DIN:**Deep Interest Network (DIN), which adaptively calculates the representation vec- tor of user interests by taking into consideration the relevance of historical behaviors given a candidate ad. **
DIN 通过局部激活单元,只关注部分相关兴趣,通过带权sum pooling 来得到用户和该广告相关的兴趣表示。和这个广告相关的历史行为权重高一些,在兴趣表示中作用更大。为了帮助训练,昨天提出的mini-batch aware regularization,只有非零的出现在batch中的参数参与到L2 正则计算。另外,开发了一种自适应数据的激活函数,该函数改进PReLU, 通过根据输入数据的分布自适应地调整纠正点,实验证明对训练带有稀疏特征的DNN模型有帮助。
2 RELATEDWORK
Deep Crossing ,Wide& Deep 模型,youtube 推荐模型。PNN模型在embedding上引入一层product 层,DeepFM模型使用FM作为Wide&deep模型的wide部分。这些方法的共同点是使用embedding层学习稀疏特征的稠密表示,使用DNN学习特征的交叉。
注意力机制在机器翻译中提出,DeepIntent应用到搜索广告领域。该模型使用RNN建模文本,学习到一个隐层向量,可以对query中的不同单词给予不同的注意力。
DEEP INTEREST NETWORK
Feature Representation
CTR预估的数据通常是多组类别形式,比如[weekday=Friday, gender=Female,
visited_cate_ids={Bag,Book}, ad_cate_id=Book]。
形式化地来说,假设有M组特征,那么一个样本可以表示成
x = [ t 1 T , t 2 T , . . . t M T ] T x = [t_1^T , t_2^T , ...t_M^T ]^T x=[t1T,t2T,...tMT]T
t i ∈ R K i t_i \in R^{K_i} ti∈RKi , K i K_i Ki是第i个特征组的维度大小,表示包含 K i K_i Ki个不同的取值。
t i t_i ti中的元素取值为0或1, ∑ j = 1 K i t i [ j ] = k \sum_{j=1}^{K_i} t_i[j] =k ∑j=1Kiti[j]=k k=1 表示one-hot 向量,否则为multi-hot 向量。
一个例子:

阿里巴巴 展示广告 使用的特征如下:

base model
Embedding 层
如果特征组是one-hot向量,则该特征组只有一个embedding向量,
如果特征组是multi-hot向量,则该特征组是一组embedding向量
Pooling layer and Concat layer
由于不同用户的行为数量不同,那么multi hot 特征中的非0个数不同,行为特征(multi hot)中的 embedding 向量的个数也就不同。一般都会通过pooling层转换为固定长度的向量。
e i = p o o l i n g ( e i 1 , e i 2 , . . . e i k ) . e_i =pooling(e_{i1},e_{i2},...e_{ik}). ei=pooling(ei1,ei2,...eik).
最常用的pooling方法是sum 和average。
embedding和pooling都是在组级别上进行操作,最后再全都concat成一个向量。
MLP&Loss
负的对数似然函数


The structure of Deep Interest Network
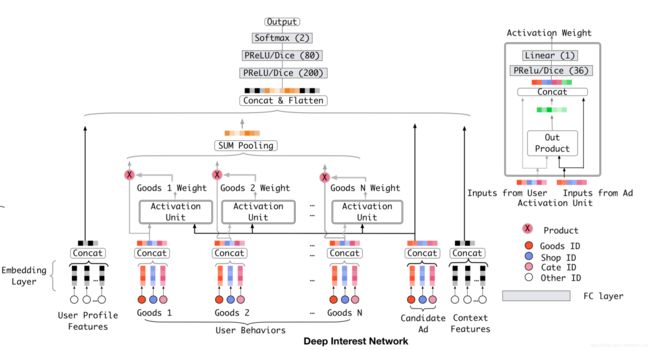
上图是DIN的模型结构图,与base model的主要区别在于局部激活单元,其他地方都一样,该激活单元在用户行为特征上完成带权求和pooling(weighted sum pooling),这样可以自适应地计算在给定候选广告A的情况下用户的表示 v U v_U vU

e 1 , e 2 , . . . , e H {e_1,e_2,...,e_H} e1,e2,...,eH是用户U的行为对应的embedding向量列表,H是行为个数。 v A v_A vA是广告A的embedding向量。这样的话对不同的广告A, v U ( A ) v_{U}(A) vU(A) 的表示就会不同。 a ( . ) a(.) a(.)就是一个前向网络,输出当前行为在候选广告A下面的权重。同时,作者也把 两个输入embedding向量的外积也作为注意力网络的输入(
这里有个疑问,向量的外积(https://zh.wikipedia.org/wiki/外积)是一个矩阵,如何将矩阵作为dnn的输入,难不成要展开成向量,同时,两个输入向量是指候选广告A和当前行为的embedding向量吗?
)
局部激活单元和注意力网络很相似,但是也有不同:
1.没有 ∑ i w i = 1 {\sum_i w_i =1} ∑iwi=1 的限制;这样可以保留用户兴趣的强度;
这个是说最后 a ( . ) a(.) a(.)输出时去掉了用于归一化的softmax层。相反, ∑ i w i \sum_i w_i ∑iwi可以一定程度上可以近似看做激活了的用户兴趣的强度。比如一个用户的历史行为包含90%的衣服和10%的电子产品,那么给定一个T恤和一个手机,T恤激活了大部分的属于衣服的历史行为,可能 v U v_U vU 的值比手机更大,表示更强的兴趣。传统的注意力网络通过对输出层的归一化失去了the resolution on the numerical scaleofvU
作者也尝试使用LSTM 建模用户历史行为数据,但是没有提升。不同于NLP任务中文本受限于语法,用户历史行为数据包含了用户的多种兴趣,Rapid jumping and sudden ending over these interests causes the sequence data of user behaviors to seem to be noisy. A possible direction is to design special structures to model such data in a sequence way. We leave it for future research.
2.TRAINING TECHNIQUES
Mini-batch Aware Regularization
工业级的神经网络训练中过拟合问题比较棘手,比如我们向模型中加入一个6亿的商品id 特征(包含用户访问过的商品id和广告的商品id),那么如果没有正则,模型性能在第一个epoch之后就会急剧下降。而在输入是稀疏特征,包含 千万级特征的网络上,直接应用l1、l2正则一般也不实用。以l2 正则为例。在没有正则的神经网络中,如果使用sgd之类的优化算法,只有batch中非0的的特征对应的权重才会被更新。但是,加上l2 正则之后,对每个batch,所有参数都要被更新。此时,计算量很大,对千万级参数来说不可接受。
文中提出了一种mini-batch aware regularizer,只计算batch中出现过的稀疏特征的l2 范数。实际上,在ctr网络上,主要是embedding占据了大多数的参数。假设embedding 矩阵 W ∈ R D ∗ K W\in R^{D*K} W∈RD∗K表示整个embedding字典。D是embedding向量长度,k是特征取值个数。
对应的L2正则为:

w j ∈ R D w_j\in R^D wj∈RD是第j个embedding向量, I ( x j ≠ 0 ) I(x_j\ne 0) I(xj̸=0)表示样本x是否含有特征j, n j n_j nj表示特征j在所有特征中出现的次数。上述等式可以转换成min-batch的形式:

B是min-batch的总数, B m B_m Bm表示第m个batch,令 α m j = m a x ( x , y ) ∈ B m I ( x j ≠ 0 ) \alpha_{mj}=max_{(x,y)\in B_m} I(x_j \ne 0) αmj=max(x,y)∈BmI(xj̸=0) 表示 B m B_m Bm中是否至少有一个样本包含特征j。那么等式5可以近似成如下形式:

根据以上分析,我们可以推导出一个minin-batch维度的L2正则的近似版本:
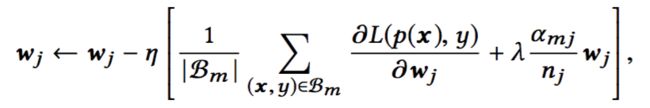
即只有 B m B_m Bm中出现过的特征才会参与到正则的计算
5.2 Data Adaptive Activation Function
PReLU是常用的激活函数, 表达式如下:

p ( s ) = I ( s > 0 ) p(s)=I(s>0) p(s)=I(s>0)是一个指示函数,控制f(s)取值为s还是 α s \alpha s αs, α \alpha α是一个学习参数。作者将p(s)称作控制函数,该函数在原点0 对激活函数做强制修改,可能在不同层具有不同数据分布的情况下并不合适。
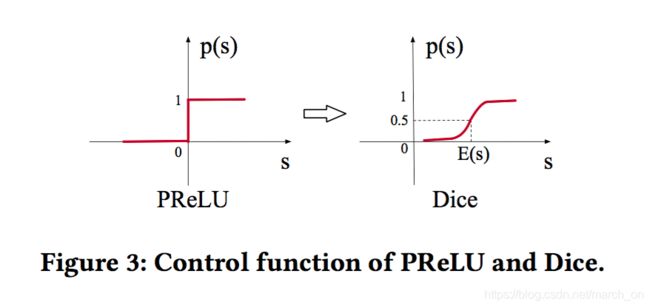
作者设计的函数Dice:
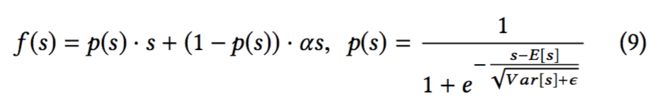
在训练阶段,E(s)和var(s)是mini-batch的均值、方差。在测试阶段,是E(s)和var(s)的移动平均(不太懂这个怎么算) ϵ \epsilon ϵ 是一个常数,通常设置为 1 0 − 8 10^{-8} 10−8.
Dice可以看做PRELU的推广。可以根据数据分布自适应的调整校正点。
EXPERIMENTS
Datasets and Experimental Setup
Amazon Dataset
作者选取了Electronics 子集 ,包含192,403 users, 63,001 goods, 801 categories and 1,689,188 samples。该数据集中的用户行为比较多,每个用户的商品有超过5个用户评论。特征包括goods_id, cate_id, user reviewed goods_id_list and cate_id_list
假设一个用户的行为是 ( b 1 , b 2 , . . . , b k , . . . b n ) (b_1,b2,...,b_k,...bn) (b1,b2,...,bk,...bn),那么认为就是使用前面k个看过的物品预测第k+1个物品。Training dataset is generated with k = 1, 2, . . . , n 2 for each user。 测试集是使用前面n-1个看过的物品预测最后一个物品。
对所有模型使用 SGD as the optimizer with exponential decay, 学习率从1开始衰减到0.1。min-batch大小为32。
MovieLens Dataset
contains 138,493 users, 27,278 movies, 21 categories and 20,000,263 samples
为是其适合ctr任务,作者将其转换为二分类数据。之前电影评分为0-5,作者将4、5标注为正样本,其余为负样本。根据userId来划分训练集和测试集。mong all 138,493 users, of which 100,000 are randomly selected into training set (about 14,470,000 samples) and the rest 38,493 into the test set (about 5,530,000 samples).
任务变成 根据用户的历史行为,判断用户是否会对某个电影打分超过3分。Features include movie_id, movie_cate_id and user rated movie_id_list, movie_cate_id_list。optimizer, learning rate and mini-batch size 和上一个数据集相同。
Alibaba Dataset.
取自阿里展示广告系统 线上流量,两周做训练集,接下来的一天为测试集。训练集和测试集大小分别为20亿和1.4亿。
For all the deep models, the dimensionality of embedding vector is 12 for the whole 16 groups of features. Layers of MLP issetby192⇥200⇥80⇥2.
由于数据量大,mini-batch size 为5000,Adam 为优化器。同时使用了指数衰减 in which learning rate starts at 0.001 and decay rate is set to 0.9.

Competitors
LR
BaseModel
Wide&Deep
It consists of two parts: i) wide model, which handles the manually designed cross product features, ii) deep model, which automatically extracts nonlinear relations among features and equals to the BaseModel.
Wide&Deep needs expertise feature engineering on the input of the “wide” module. We follow the practice in [10] to take cross-product of user behaviors and candidates as wide inputs. For example, in MovieLens dataset, it refers to the cross-product of user rated movies and candidate movies
用户行为和候选item 的cross-product 作为wide部分的输入。
PNN
DeepFM
It imposes a factorization machines as “wide” module in Wide&Deep saving feature engineering jobs.
Metrics
作者使用的AUC:
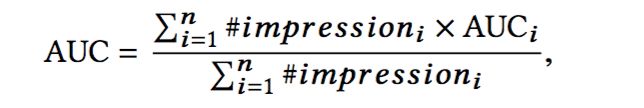
n是用户数, # i m p r e s s i o n i \#impression_i #impressioni and A U C i AUC_i AUCi are the number of impressions and AUC corresponding to the i-th user.
同时,使用RelaImpr 来测量模型间的相对提升幅度。

Result from model comparison on Amazon Dataset and MovieLens Dataset

所有实验重复5次,平均指标作为最终指标。
1.DNN 均超过LR
2.PNN和DeepFM 超过W&D
3.DIN效果最好
尤其在amazon上,作者归因于局部激活单元的作用。
4.Dice 是有效的
Performance of regularization
前两个数据集特征维度在10w维左右,过拟合不严重。但是在阿里数据集上 包含高维稀疏特征,过拟合就是很严重的问题了。比如加入6亿的商品id之后,没有使用正则化的话训练在第一个epoch之后 过拟合就很严重了,如下图的绿线所示。
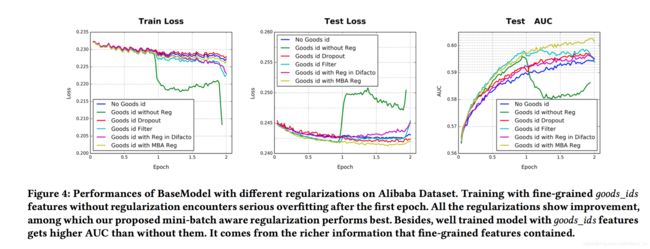
基于此,作者对几种常用的正则化方法做了详细的实验。
DropOut 随机丢弃每个样本中50%的特征id
Filter
按样本中 商品ID的出现频次进行过滤,只保留最频繁的id。
在实验中,作者保留了top 两千万。
RegularizationinDiFacto(这个方法没怎么听说过)
Parametersassociatedwith frequent features are less over-regularized
MBA(Mini-Batch Awarere gularization method)
作者提出的正则化方法
Regularization parameter for both DiFacto and MBA is searched and set to be 0.01.
仔细观察上图。
1.和没有使用商品ID 相比,使用商品ID 的模型在第一轮 测试集的auc指标明显提高。
2.但是,没有使用正则化的模型在第一轮之后过拟合严重。
3.dropout 阻止了过拟合,但是收敛较慢
4.filter 一定程度上减轻了过拟合
5.Regularization in DiFacto sets a greater penalty on oods_id with high frequency, which performs worse than frequency lter.
6.MBA 表现最好
7.加入商品id特征后AUC 有提升,因为 fine-grained features包含丰富的信息。考虑到这一点,虽然 低频过滤比dropout 稍微好一点,但是也丢掉了大部分的低频id,这样模型对fine-grained features 的利用空间会小一些
Result from model comparison on Alibaba Dataset
使用全部特征的模型效果如下:

1.同样的激活函数和正则方法下,DIN效果比baseModel,W&D,PNN和DeepFM 好
再次印证 局部激活单元的有效性。
2.
Training DIN with mini-batch aware regularizer brings additional 0.0031 absolute AUC gain over dropout. Besides, DIN with Dice brings additional 0.0015 absolute AUC gain over PReLU.
It is notable that in commercial advertising systems with hundreds of millions of tra cs, 0.001 absolute AUC gain is signi cant and worthy of model deployment empirically.
Result from online A/B testing
线上在2017-05 进行了一个月的实验,ctr 提升10%, RPM 提升3.8%。现在已经开始服务主流量。
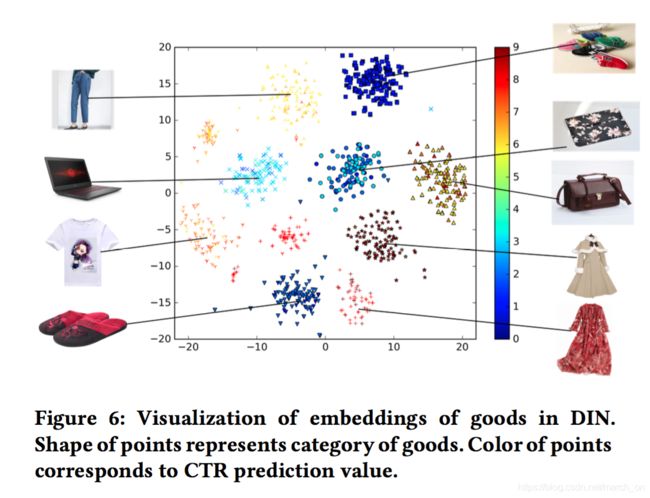
Visualization of DIN
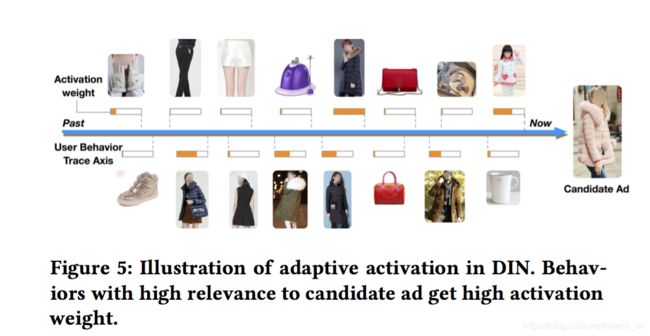
1.在候选广告下不同用户行为的激活权重
As expected, behaviors with high relevance to candidate ad are weighted high.
2.可视化了embedding向量
选择了一位用户 下9个品类,每个品类各100物品作为候选广告。
下图用t-sne可视化了DIN学习到的物品的embedding向量,相同形状的点属于相同的品类。
可以看到相同品类的物品属于同一个聚类,说明DIN 学习到的embedding的聚类属性。