Wide & Deep Learning for Recommender Systems
ABSTRACT
通过特征的向量积(cross-product)对特征交叉的记忆具有可解释性,而泛化又需要更多的特征工程。而DNN通过对稀疏特征学习低维稠密的embedding表示对未出现的特征组合具有良好的泛化性能。但是,当用户物品关系比较稀疏,维度又比较高时,DNN容易过度泛化,推荐一些不相干的物品。文中提出Wide&Deep 学习,同时训练wide 部分和dnn,将记忆性和泛化性结合在一起。作者在google play上进行实验,实验表明W&D 模型与只有wide和只有deep部分相比,可以极大提高app的acquisition。
INTRODUCTION
记忆性可以解释为物品或者特征之间的共现关系并从历史数据中发现这种联系。泛化性是物品关系之间的传递或者转移,可以用来探索历史数据中没有出现或者很少出现的特征组合。 基于记忆性推荐出的商品一般和用户发生过历史行为的物品相关,而泛化性可以提高推荐的多样性。文中着手于google play上的app推荐。
广义线性模型比如LR因为简单、可解释、可扩展,在工业级的推荐和排序问题中广泛使用。一般使用ont-hot编码的二元稀疏 特征来进行训练。记忆性可以通过特征之间的cross-product来完成。比如AND(user_installed_app=netflix, impres- sion_app=pandora”) 只有在用户安装了netflix且看到了pandora app之后该特征的特征值为1。这也解释了一个特征对的共现关系和label之间的关系。泛化性可以通过更粗粒度的特征组合来实现。比如AND(user_installed_category=video, impression_category=music),但是这种需要人工特征工程。One limitation of cross-product trans- formations is that they do not generalize to query-item fea- ture pairs that have not appeared in the training data.
基于Embedding的模型,比如FM或者DNN,可以通过学习query和item特征的低维embedding表示,可以泛化到之前没有出现过的query-item特征对,减少了特征工程。
但是,对于高维稀疏的特征,学习低维表示比较难。
in such cases, there should be no interactions between most query-item pairs, but dense embeddings will lead to nonzero predictions for all query-item pairs, and thus can over-generalize and make less relevant recommendations.

RECOMMENDER SYSTEM OVERVIEW

第一个阶段是检索,返回和查询最匹配的物品列表。
第二个阶段是排序,得分经常是P(Y|X),在特征向量x的条件下用户行为y的概率。
特征向量x包括了用户特征(比如国家、语言、人口统计资料),上下文特征(设备、一天中的小时,一周中的哪一天)、展现特征(app 的存活时间、历史统计数据) 本文专注于排序模型。
WIDE & DEEP LEARNING
The Wide Component
这部分是一个广义线性模型
y = W x + b y=Wx +b y=Wx+b
特征包含原始特征和转换特征,后者最重要的是cross-product 特征:

d是特征个数, c k i c_{ki} cki是一个bool型,当第k个特征转换包含特征i时, c k i c_{ki} cki值为1,否则为0.
对二维特征来说,只有组成特征全为1时,该组合特征的值才1
比如 “AND(gender=female, language=en)” 特征,只有当 (“gender=female” 和 “language=en”全成立时,该特征值才为1. 这种特征捕捉到了二维特征之间的交叉关系,同时对模型增加了非线性。
The Deep Component
即DNN,高维稀疏离散特征通常转换为embedding向量,维度从O(10)到O(100)。
embedding向量作为隐层的输入。每个隐层的计算如下:

Joint Training of Wide & Deep Model
两部分通过 各自输出的log odds 的加权和作为最后的预测, 然后输入给LR损失函数进行联合训练。
这里为什么说是log odds
作者阐述了joint training 和ensemble的区别。
在实验时,wide部分使用L1正则的FTRL 算法来优化,AdaGrad 作为deep部分。
对LR来说,最后的预测是

SYSTEM IMPLEMENTATION
包含三部分:data generation, model training, and model serving
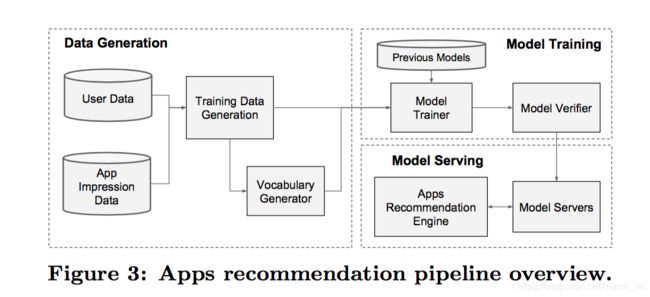
数据生成
在这个阶段,同一时间段内的用户和app展现数据用来生成训练数据。每个样本对应一次曝光(impression)。label是app acquisition, 即展现的app被下载则label为1,否则label 为0。
在这一阶段,还会生成词典(vocabularies), 用来将字符型离散特征映射到整型ID的映射表。系统会计算所有出现次数高于某个阈值的字符型特征 的ID空间。 (必须是字符串类型特征吗 )
连续特征归一化到[0,1]区间,通过把x映射到累积分布函数(cumulative distribution function)P(X<=x),然后划分到 n q n_q nq个桶中。对第i个区间的值来说,归一化后的值为 i − 1 n q − 1 \frac{i-1}{n_q -1} nq−1i−1.分位点也是在这一阶段生成
这个连续特征的处理不是很明白怎么做的
Model Training
模型结构如下:

wide部分是用户安装的app和展现的app的交叉。
有个问题,交叉出来的结果是一个one-hot的向量?
deep部分,每个离散特征embedding到一个32维的向量,所有离散特征的embedding向量和连续特征concat到一起,生成一个差不多1200维的稠密向量。然后接3个ReLu,最后是一个LR输出。
W&D 模型在5000亿样本上进行训练,每次有新数据时模型都要重新训练,如果重头开始训练成本巨大,且从数据到达到模型更新完成 之间会有delay,所以,作者实现了一个暖启动(warm-start)系统,将模型初始化为之前训练出来的模型。
在将模型加载到model server前,模型需要空运行(dry run)一趟,保证在线上流量灭有问题。We empirically validate the model quality against the previous model as a sanity check.(健康性检查)
Model Serving
app按照分数从高到低展现给用户。
为了提高响应速度,作者多线程并行对batch进行预测,而不是对所有的候选app 一次顺序预测。
EXPERIMENT RESULTS
App Acquisitions
线上3周的A/B实验
对照组1%的用户展现LR 的推荐结果,实验组1% 的用户展现W&D模型的推荐结果,特征和对照组相同。
W&D 在线上的效果比线下更显著,作者推测的原因是
One possible reason is that the impressions and labels in offline data sets are fixed, whereas the online system can generate new exploratory recommendations by blending generalization with memorization, and learn from new user responses.
Serving Performance

RELATED WORK
wide 和deep结合的想法受FM启发,FM在线性模型上加上了泛化(generalization),通过将两个特征的交叉 分解为两个embedding向量的内积。本文使用DNN来学习embedding之间的非线性关系,而不是内积,提高了模型capacity。