Hadoop 实验:Join 操作
Hadoop 实验:Join 操作
一. 实验背景:
1.概述
我们这次学习是在hadoop中使用MapRedce进行Join的操作时同时耗时,但是由于hadoop的分布式设计理念的特殊性,因此对于join的操作也同样具备一定的特殊性。
2. 原理
使用 MapReduce 实现 Join 操作有多种实现方式:
在 Reduce 端连接为最为常见的模式:
Map 端的主要工作:为来自不同表(文件)的 key/value 对打标签以区别不同来源的记录。然后用连接字段作为 key,其余部分和新加的标志作为 value,最后进行输出。
**Reduce 端的主要工作:**在 Reduce 端以连接字段作为 key 的分组已经完成,我们只 需要在每一个分组当中将那些来源于不同文件的记录(在 map 阶段已经打标志)分开,最后进行笛卡尔只就 OK 了。
在 Map 端进行连接
使用场景:一张表十分小、一张表很大。
用法:在提交作业的时候先将小表文件放到该作业的 DistributedCache 中,然后从 DistributeCache 中取出该小表进行 Join key / value 解释分割放到内存中(可以放大 Hash Map 等等容器中)。然后扫描大表,看大表中的每条记录的 Join key /value 值是否能够在内存中找到相同 Join key 的记录,如果有则直接输出结果。
SemiJoin SemiJoin 就是所谓的半连接,其实仔细一看就是 Reduce Join 的一个变种,就是在map 端过滤掉一些数据,在网络中只传输参与连接的数据不参与连接的数据不必在网络中进行传输,从而减少了 shuffle 的网络传输量,使整体效率得到提高,其他思想和 ReduceJoin 是一模一样的。说得更加接地气一点就是将小表中参与 Join 的 key 单独抽出来通过DistributedCach 分发到相关节点,然后将其取出放到内存中(可以放到 HashSet 中),在 map 阶段扫描连接表,将 Join key 不在内存 HashSet 中的记录过滤掉,让那些参与 Join 的记录通过 shuffle 传输到 Reduce 端进行 Join 操作,其他的和 Reduce Join 都是一样的。
二.实验步骤:
这里我们用最为常见的在Reduce端连接编写代码,首先准备数据。
201001 1003 abc
201002 1005 def
201003 1006 ghi
201004 1003 jkl
201005 1004 mno
201006 1005 pqr
1003 kaka
1004 da
1005 jue
1006 zhao
在 Reduce 阶段,先把每个 key 下的 value 列表拆分为分别来自表 A 和表 B 的两部分,分别放入两个向量中。然后遍历两个向量做笛卡尔积,形成一条条最终结果.
编写代码程序:
内容环境为hadoop/ilb.zip自行下载。将下好的jar包导入idea。
完整代码:
package mr;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Partitioner;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.util.GenericOptionsParser;
public class MRJoin {
public static class MR_Join_Mapper extends Mapper {
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
// 获取输入文件的全路径和名称
String pathName = ((FileSplit) context.getInputSplit()).getPath().
toString();
if (pathName.contains("data.txt")) {
String values[] = value.toString().split("\t");
if (values.length < 3) {
// data 数据格式不规范,字段小于 3,抛弃数据
return;
} else {
// 数据格式规范,区分标识为 1
TextPair tp = new TextPair(new Text(values[1]), new Text("1"));
context.write(tp, new Text(values[0] + "\t" + values[2]));
}
}
if (pathName.contains("info.txt")) {
String values[] = value.toString().split("\t");
if (values.length < 2) {
// data 数据格式不规范,字段小于 2,抛弃数据
return;
} else {
// 数据格式规范,区分标识为 0
TextPair tp = new TextPair(new
Text(values[0]), new Text("0"));
context.write(tp, new Text(values[1]));
}
}
}
}
public static class MR_Join_Partitioner extends Partitioner {
@Override
public int getPartition(TextPair key, Text value, int numParititon) {
return Math.abs(key.getFirst().hashCode() * 127) % numParititon;
}
}
public static class MR_Join_Comparator extends WritableComparator {
public MR_Join_Comparator() {
super(TextPair.class, true);
}
public int compare(WritableComparable a, WritableComparable b) {
TextPair t1 = (TextPair) a;
TextPair t2 = (TextPair) b;
return t1.getFirst().compareTo(t2.getFirst());
}
}
public static class MR_Join_Reduce extends Reducer {
protected void Reduce(TextPair key, Iterable values, Context
context)
throws IOException, InterruptedException {
Text pid = key.getFirst();
String desc = values.iterator().next().toString();
while (values.iterator().hasNext()) {
context.write(pid, new Text(values.iterator()
.next().toString() + "\t" + desc));
}
}
}
public static void main(String agrs[])
throws IOException, InterruptedException, ClassNotFoundException {
Configuration conf = new Configuration();
GenericOptionsParser parser = new GenericOptionsParser(conf, agrs);
String[] otherArgs = parser.getRemainingArgs();
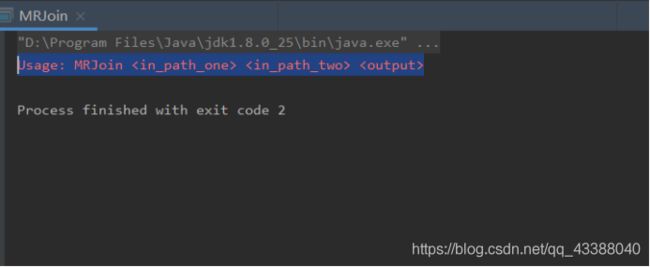
if (agrs.length < 3) {
System.err.println("Usage: MRJoin
执行成功:
我在执行中遇到的问题:

原来这是因为sl4j和log4j的不兼容导致的,具体处理方案如下:
首先看看你工程中的sl4j-api的版本(比如我的是1.7.21),然后在http://mvnrepository.com/搜索slf4j-log4j12,会出现SLF4J LOG4J 12 Binding,点击进入,会有很多版本的slf4j-log4j12,我们点击1.7.21版本的slf4j-log4j12进入详细信息页面,查看依赖的log4j,这个版本的slf4j-log4j12依赖的是1.2.71版本的log4j。
打包并上传hadoop
使用idea 开发工具将该代码打包,用XFTP导入你的Ubantu中,假定打包后的文件夹为MRjoin.jar,这可以使用如下命令向hadoop集群提交本应用,在将你创建的数据文本用xftp传入Ubantu 用hadoop fs -put 上传到fs的集群服务器。
登录hadoop系统
Start-all.sh 启动服务
Jps 查询进程(5个进程)
创建文件夹保存上传txt文件:
Hadoop fs -mkdir -p /usr/MRJoin/in/
将txt文本上传到/usr/MRJoin/in/ 下:
Hadoop fs -put /home/hadoop/data.txt /usr/MRJoin/in/
Hadoop fs -put /home/hadoop/info.txt /usr/MRJoin/in/
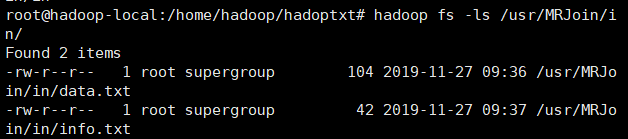
查询是否上传成功:
Hadoop fs -ls /usr/MRJoin/in/
执行jar包,执行join:
Hadoop jar MRJoin.jar mr.MRJoin /usr/MRJoin/in/data.txt /usr/MRJoin/in/info.txt /usr/MRJoin/out
查询结果 hadoop fs -cat /usr/MRJoin/out/p*
MapReduce Join的实验完成!希望本次实验可以帮助到你。谢谢!在这里插入代码片