美拍爬虫逆向js解析实战
爬虫肆无忌惮的好日子一去不复返了,各个公司如今都有了防范意识。采用cookie池,更换user-agent,更换代理,采用打码平台破解验证码,自动化采集等爬取,已经是比较low的方式了,高级一点的有逆向解析js和反编译app破解加密sign等。
逆向解析以网页版美拍无水印视频爬取为例子:
爬取美拍热门视频:https://www.meipai.com/medias/hot
1.找到接口:https://www.meipai.com/home/hot_timeline?page=1&count=12
发现是get请求,直接在浏览器访问就获取到标题,视频播放地址,点赞,转发,作者,发布时间等信息。
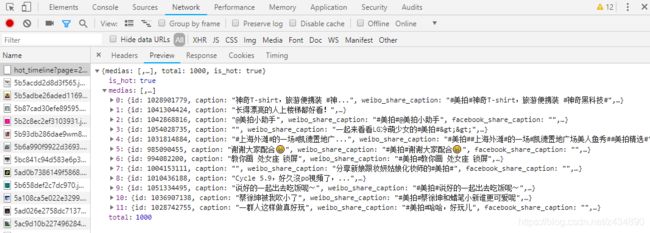
问题
在获取视频下载地址的时候,发现video是一串字符串,尝试后发现,各种办法都无法解析,而且也无法获取到视频下载地址。
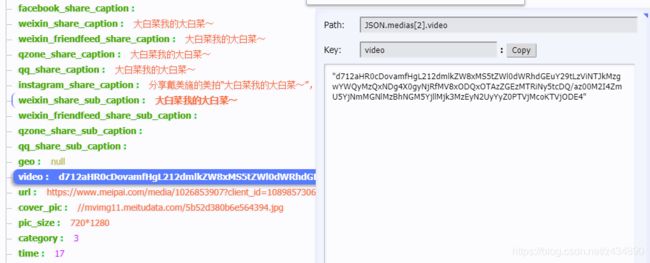
思路
在element页面发现了data-video与视频的直接播放地址,但是element页面数据无法直接获取到。
videos:f7b0aHpgn0opgVUR0cDovL212dmlkZW8xMS5tZWl0dWRhdGEuY29tLzVjMGY4Zjg4YzMyYmUybWc5b29nZ3A5MDg1X0gyNjRfMV81ODZjMWNlNWY2YmE3MS5tcDQ/az1hYjg2MWQ4NDJhYjM2OTRkN2JhYmE4NzczODYxMzA5YSZ0PTVjMTYzq4CM2I3
真实视频地址:http://mvvideo11.meitudata.com/5c0f8f88c32be2mg9ooggp9085_H264_1_586c1ce5f6ba71.mp4?k=ab861d842ab3694d7baba8773861309a&t=5c1633b7

通过search全局搜索data-video与src当中的部分字符串,搜索.mp4,也发现都没有任何结果,一时间束手无策。
尝试全局搜索mp4,细心找到了某个js当中有src:k.decodeMp4.decode(a.vcastr_file),敏感到它就是要找的。
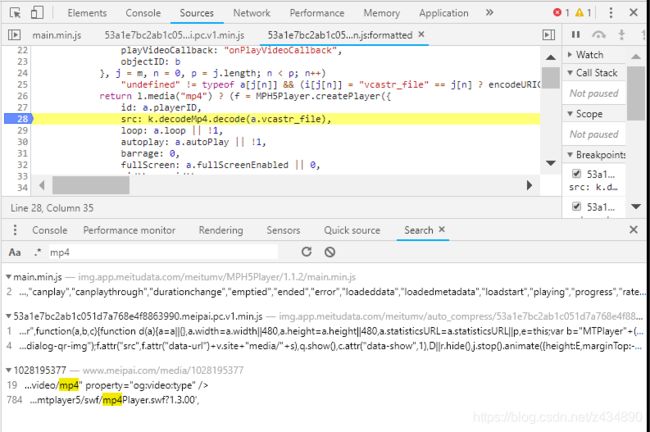
破解
k.decodeMp4.decode(a.vcastr_file),找到对应的js实现,搜索decodeMp4,在6090行发现了这个方法,耐心对这一段js代码进行解析,将js语法转为熟悉的python。

转完之后的代码为:
def getHex(a):
hex = a[:4][::-1]
str1= a[4:]
return str1, hex
def getDec(a):
b = str(int(a, 16))
c = list(b[:2])
d = list(b[2:])
return c, d
def substr(a,b):
k = int(b[0])
c = a[:k]
d = a[k:k+int(b[1])]
temp = a[int(b[0]):].replace(d, "")
res = c+ temp
return res
def getPos(a,b):
b[0] = len(a) -int(b[0]) - int(b[1])
return b
#这里的a字符串就是前面的videos
a = "f7b0aHpgn0opgVUR0cDovL212dmlkZW8xMS5tZWl0dWRhdGEuY29tLzVjMGY4Zjg4YzMyYmUybWc5b29nZ3A5MDg1X0gyNjRfMV81ODZjMWNlNWY2YmE3MS5tcDQ/az1hYjg2MWQ4NDJhYjM2OTRkN2JhYmE4NzczODYxMzA5YSZ0PTVjMTYzq4CM2I3"
str1, hex= getHex(a)
pre,tail = getDec(hex)
d = substr(str1, pre)
zz = substr(d, getPos(d, tail))
zz就是return g.atob(this[k](d, this.getPos(d, c.tail)))当中的this[k](d, this.getPos(d, c.tail)),将它传给了g.atob()当作参数,因此继续进行断点调试。会进入下面的方法,最后return h,这一段也是重要的参数生成部分,嫌弃麻烦,直接用exexjs调用js(用js2py等工具也都是可以的)

python中执行js代码,print(jsContent1.call(“s”,kk))这个打印的结果就是我们需要的src:http://mvvideo11.meitudata.com/5c0f8f88c32be2mg9ooggp9085_H264_1_586c1ce5f6ba71.mp4?k=ab861d842ab3694d7baba8773861309a&t=5c1633b7 ,无水印的视频地址
import execjs
js = """
var e = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/=";
function s(a) {
if (a = a.replace(/=+$/, ""),
a.length % 4 == 1)
throw f;
for (var b, c, d = 0, g = 0, h = ""; c = a.charAt(g++); ~c && (b = d % 4 ? 64 * b + c : c,
d++ % 4) ? h += String.fromCharCode(255 & b >> (-2 * d & 6)) : 0)
c = e.indexOf(c);
return h
}"""
jsContent1 = execjs.compile(js)
print(jsContent1.call("s",zz))
后来同事发现,对zz进行base64解码就是我们需要的url了。
import base64
print(base64.b64decode(zz).decode())
最终的代码与结果就不展示了,感兴趣的自己研究一下。
总结
1.对url当中的关键字符串,包括mp3,mp4,进行全局搜索定位,经常是我们的突破口;
2.对浏览器进行断点调试,这个可以到网上找找代码,熟悉一下过程;
3.对js不熟悉,依然要硬着头皮上,耐心解析(使用浏览器的console熟悉js方法),简化js或转化为python代码,边调试边验证;
逆向解析是爬虫的难点,破解需要靠积累,熟悉常见的加密后的样式,如果你有类似的破解心得,欢迎留言交流。