用pytorch写一个简单的线性回归模型
import torch
import torch.nn as nn
import numpy as np
import matplotlib.pyplot as plt
from torch.autograd import Variable
定义超参数
input_size = 1
output_size = 1
num_epochs = 1000 # 训练次数
learning_rate = 0.001 # 学习率
x_train = np.array([[2.3], [4.4], [3.7], [6.1], [7.3], [2.1],[5.6], [7.7], [8.7], [4.1],
[6.7], [6.1], [7.5], [2.1], [7.2],
[5.6], [5.7], [7.7], [3.1]], dtype=np.float32)
xtrain生成矩阵数据
y_train = np.array([[3.7], [4.76], [4.], [7.1], [8.6], [3.5],[5.4], [7.6], [7.9], [5.3],
[7.3], [7.5], [8.5], [3.2], [8.7],
[6.4], [6.6], [7.9], [5.3]], dtype=np.float32)
plt.figure()
画图散点图
plt.scatter(x_train,y_train)
x轴名称
plt.xlabel(‘x_train’)
y轴名称
plt.ylabel(‘y_train’)
显示图片
plt.show()
定义线性回归模型
class LinearRegression(nn.Module):
def init(self, input_size, output_size):
super(LinearRegression, self).init()
self.linear = nn.Linear(input_size, output_size)
def forward(self, x):
out = self.linear(x)
return out
model = LinearRegression(input_size, output_size)
损失函数定义,参数优化器定义
criterion = nn.MSELoss() # 定义损失类型为均方误差
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
模型训练
for epoch in range(num_epochs):
# np数组转化为张量
inputs = Variable(torch.from_numpy(x_train))
targets = Variable(torch.from_numpy(y_train))
# Forward + Backward + Optimize
optimizer.zero_grad()
# 向前传递
outputs = model(inputs)
loss = criterion(outputs, targets)
# 反向运算
loss.backward()
# 参数优化
optimizer.step()
# 每迭代5次打印一次损失值
if (epoch+1) % 5 == 0:
print ('Epoch [%d/%d], Loss: %.4f'
%(epoch+1, num_epochs, loss.item()))
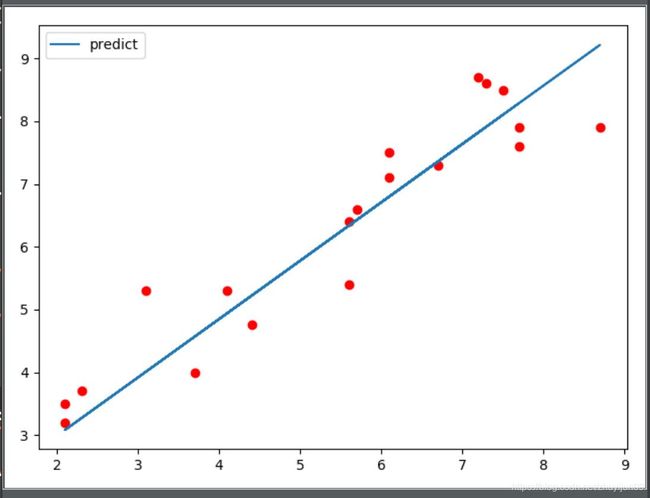
画图
model.eval()
predicted = model(Variable(torch.from_numpy(x_train))).data.numpy()
plt.plot(x_train, y_train, ‘ro’)
plt.plot(x_train, predicted, label=‘predict’)
plt.legend()
plt.show()