Java使用Trie树算法实现敏感词替过滤、根据关键词自动联想
最困难的事情就是认识自己!
个人博客,欢迎访问!
前言:
Trie树也称为字典树、单词查找树,最大的特点就是共享字符串的公共前缀来达到节省空间的目的了。
然后可以根据它的公共前缀的特性来实现敏感词过滤、自动联想等功能。
抽象出trie树的数据结构:
1、首先来看下trie树的结构图:

从上图可以归纳出Trie树的基本性质:
①根节点不包含字符,除根节点外的每一个子节点都包含一个字符。
②从根节点到某一个节点,路径上经过的字符连接起来,为该节点对应的字符串。
③每个节点的所有子节点包含的字符互不相同。
④从第一字符开始有连续重复的字符只占用一个节点,比如上面的to,和ten,中重复的单词t只占用了一个节点
从上面归纳出的基本性质可以抽象出节点的class属性:
1、是否为叶子节点的标志位 isWord ;
2、既能存储此节点的值也能存储其所有的子节点的 children 数据结构HashMap:
节点 (Node )的class类代码:
/**
* @Title: Node
* @Description: trie树的节点
*/
private class Node {
// 节点是否为叶子节点的标志;true:叶子节点,false:非叶子节点(用于子节点的节点)
public boolean isWord;
// 当前节点拥有的孩子节点,使用hashmap进行存储,在查找子节点时的时间复杂度为O(1)
public HashMap children;
public Node(boolean isWord) {
this.isWord = isWord;
this.children = new HashMap<>();
}
public Node() {
this(false);
}
} 代码奉上:
import java.util.ArrayList;
import java.util.Arrays;
import java.util.HashMap;
import java.util.List;
/**
* @Title: Trie
*/
public class Trie {
/**
* @Title: Node
* @Description: trie树的节点
*/
private class Node {
// 节点是否为叶子节点的标志;true:叶子节点,false:非叶子节点(拥有子节点的节点)
public boolean isWord;
// 当前节点拥有的孩子节点,使用hashmap进行存储,在查找子节点时的时间复杂度为O(1)
public HashMap children;
public Node(boolean isWord) {
this.isWord = isWord;
this.children = new HashMap<>();
}
public Node() {
this(false);
}
}
// trie树的根节点
private Node root;
// trie树中拥有多少分枝(多少个敏感词)
private int size;
public Trie() {
this.root = new Node();
this.size = 0;
}
/**
* @Description: 返回trie树中分枝树(敏感词树)
*/
public int getSize() {
return size;
}
/**
* @param word 添加的敏感词
* @Description: 向trie树中添加分枝/敏感词
*/
public void addBranchesInTrie(String word) {
// 设置当前节点为根节点
Node cur = root;
char[] words = word.trim().toCharArray();
for (char c : words) {
if (Character.isWhitespace(c)) {
continue;
}
// 判断当前节点的子节点中是否存在字符c
if (!cur.children.containsKey(c)) {
// 如果不存在则将其添加进行子节点中
cur.children.put(c, new Node());
}
// 当前节点进行变换,变换为新插入到节点 c
cur = cur.children.get(c);
}
// 分枝添加完成后,将分枝中的最后一个节点设置为叶子节点
if (!cur.isWord) {
cur.isWord = true;
// 分枝数(敏感词数)加1
size++;
}
}
/**
* @param word
* @return
* @Description: 判断trie树中是否存在某分枝/敏感词
*/
public boolean contains(String word) {
Node cur = root;
char[] words = word.toCharArray();
for (char c : words) {
if (!cur.children.containsKey(c)) {
return false;
}
cur = cur.children.get(c);
}
// 如果存在并且遍历到trie树中某个分支最后一个节点了,那此节点就是叶子节点,直接返回true
return cur.isWord;
}
/**
* @param word 一段话,如果有敏感词需要被替换的词
* @return
* @Description: 如果一段话中有trie树中存储的敏感词则需将其进行替换为 **; 例如:尼玛的,替换为 **的
*/
public String sensitiveWordReplace(String word) {
System.out.println("敏感词替换前:" + word);
Node cur = root;
char[] words = word.toCharArray();
// 需要被替换的敏感词
StringBuilder oldTemp = new StringBuilder();
// 需要替换成的星号
StringBuilder starTemp = new StringBuilder();
for (char c : words) {
if (!cur.children.containsKey(c)) {
// 判断当前字符为 空格、tab 键等
if (Character.isWhitespace(c) && oldTemp.length() > 0) {
oldTemp.append(c);
starTemp.append("*");
}
// 如果当前节点的孩子节点中没有此单词则直接跳过此循环,进入下次循环
continue;
}
if (!cur.isWord) {
// 拼接上word和trie树都有的字符
oldTemp.append(c);
starTemp.append("*");
cur = cur.children.get(c);
}
if (cur.isWord) {
// 进行敏感词替换
word = word.replaceAll(oldTemp.toString(), starTemp.toString());
// 清空StringBuilder中内容
oldTemp.delete(0, oldTemp.length());
starTemp.delete(0, starTemp.length());
// 查找一个敏感词并替换后,需要重新从根节点进行遍历,所以当前节点指向root
cur = root;
}
}
System.out.println("敏感词替换后:" + word);
return word;
}
/**
* 存放trie树中查询到的联想词
*/
private List list = new ArrayList();
/**
* @param word
* @Description: 利用trie的公共前缀特性,可以实现关键词自动联想
*/
public void prefixMatching(String word, Node root) {
Node cur = root;
char[] words = word.trim().toCharArray();
StringBuilder str = new StringBuilder();
str.append(word);
// 获取关键词最后一个节点
for (int i = 0; i < words.length; i++) {
if (Character.isWhitespace(words[i])) {
continue;
}
if (!cur.children.containsKey(words[i])) {
System.out.println("无关联词!");
return;
}
cur = cur.children.get(words[i]);
}
// 根据获取到的关键词的最后节点查询后面所有的符合的联想词
dfs(str, cur);
System.out.println("[ " + word + " ]在trie树中的联想词:" + Arrays.toString(list.toArray()));
}
/**
* @param word 需要查找的关键词
* @param root 关键词的最后一个词在trie上的节点
* @Description: 节点遍历
*/
public void dfs(StringBuilder word, Node root) {
Node cur = root;
if (cur.isWord) {
list.add(word.toString());
if (cur.children.size() == 0) {
return;
}
}
for (Character s : cur.children.keySet()) {
// 如果字符是空格或者tab键等
if (Character.isWhitespace(s)) {
continue;
}
word.append(s);
// 递归调用
dfs(word, cur.children.get(s));
word.delete(word.length() - 1, word.length());
}
}
}
代码测试运行:
/**
* test
*
* @param args
*/
public static void main(String[] args) {
Trie t = new Trie();
// 插入敏感词
t.addBranchesInTrie("麻痹 ");
t.addBranchesInTrie("尼玛 的");
t.addBranchesInTrie("狗日的");
t.addBranchesInTrie("死");
// 插入联想词
t.addBranchesInTrie("联想云科技");
t.addBranchesInTrie("联想 军科技");
t.addBranchesInTrie("联和利泰扩招了");
System.out.println("trie树中分枝的个数:" + t.size);
String word = "尼玛的";
System.out.println("Trie树中是否存在[ " + word + " ]敏感词: " + t.contains(word));
// 敏感词替换测试
t.sensitiveWordReplace("衮, 尼玛 的傻子, 你麻 痹的,你各 狗日的,早 晚揍死你。");
// trie树实现联想测试
t.prefixMatching(" 联 想 ", t.root);
}
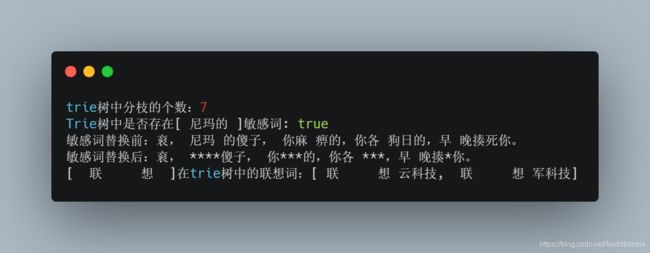
代码运行输出:
❤不要忘记留下你学习的足迹 [点赞 + 收藏 + 评论]嘿嘿ヾ
一切看文章不点赞都是“耍流氓”,嘿嘿ヾ(◍°∇°◍)ノ゙!开个玩笑,动一动你的小手,点赞就完事了,你每个人出一份力量(点赞 + 评论)就会让更多的学习者加入进来!非常感谢! ̄ω ̄=
参考资料:
1、【图解算法面试】记一次面试:说说游戏中的敏感词过滤是如何实现的?
2、前缀树(Trie)原理及Java实现
3、Trie树(字典树/前缀树)Java实现
4、Trie 树实现搜索引擎自动联想