Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks||论文阅读
元学习论文总结||小样本学习论文总结
2017-2019年计算机视觉顶会文章收录整理
MAML解读:https://blog.csdn.net/weixin_41803874/article/details/89645667
The video tutorial can be found from: Model Agnostic Meta Learning https://www.youtube.com/watch?v=wT45v8sIMDM&t=28s
Related Videos: My talk for Model Agnostic Meta Learning with domain adaptation https://www.youtube.com/watch?v=HDnzDbtj2lE
Paper: https://arxiv.org/pdf/1703.03400.pdf
pyTorch Implementation:
1. https://github.com/dragen1860/MAML-Pytorch
2. : https://github.com/tristandeleu/pytorch-maml-rl
TensorFlow Implementation: https://github.com/cbfinn/maml
摘要
文章提出了一个与模型无关的元学习模型,该模型是良好的任务通用算法,与各种梯度下降法以及各种学习问题如分类、回归、强化学习都能兼容。文章解释元学习的目标是:在一系列学习任务中训练一个模型,这个模型能仅用少量几个样本就能学会解决新任务。本文提出的方法,模型参数被显性的训练(explicitly trained),面对新任务只需要少量样本以及少量梯度更新步骤就能在新任务表现良好。事实上,本文学习了一个好的参数初始点,更容易fine-tune。模型性能:We demonstrate that this appro achleads to state-of-the-art performance on two few-shot image classification benchmarks, produces good results on few-shot regression, and accelerates fine-tuning for policy gradient reinforcement learning with neural network policies.
1 介绍
人类具有快速学习的能力,比如见过一两个样本就能学会辨认这一类,经过几分钟训练就能学会一个新技能。希望人工只能机器也能快速学习,并随着所提供的新样本持续调整适应,但这种快速灵活的实现有很大挑战,因为代理必须将其先前的经验与少量的新信息集成起来,同时避免与新数据过度匹配,此外,以往经验和新数据的形式将取决于任务。因此,为了获得最大的适用性,学习学习(或元学习)的机制应该适用于任务以及完成任务所需的计算形式。
在这项工作中,我们提出了一个元学习算法,它是通用的和模型无关的,它可以直接应用于任何使用了梯度下降法来训练的学习问题和模型。我们的重点是深度神经网络模型,但是我们说明了我们的方法如何能够轻松地处理不同的体系结构和不同的问题设置,including classification, regression, and policy gradient reinforcement learning, with minimal modification。在元学习中,训练模型的目标是从少量的新数据中快速学习一个新任务,由元学习器训练的模型能够学习大量不同的任务。我们的方法的核心思想是训练一个模型初始参数,使模型参数在经过一个或多个梯度更新步骤后,用来自新任务的少量数据就能在新任务中表现较好性能。与以前学习更新函数或学习规则的元学习方法不同((Schmidhuber, 1987; Bengio et al., 1992;Andrychowicz et al., 2016; Ravi & Larochelle, 2017)我们的算法既不增加学习参数的数量,也不对模型体系结构进行约束(比如使用RNN网络 (Santoro et al., 2016) or a Siamese network (Koch, 2015))它可以很容易地与完全连接的、卷积的或循环的新神经网络相结合。它还可以用于各种损失函数,包括可微监督损失和不可微强化学习目标。
“训练模型参数,使得经过一个或几个梯度更新步骤,就能在新的任务中产生良好的结果”这个过程,可以从特性学习的角度将其看作是构建一个广泛适用于许多任务的内部表示。如果内部表示适合于许多任务,只需稍微微调参数即可产生好的结果(例如,在前馈模型中主要修改顶层权重)。实际上,我们的算法对模型进行了优化,使其易于快速微调,允许在适合快速学习的空间中进行调整。从动力系统的角度来看,我们的学习过程可以看作是使新任务的损失函数对参数的敏感性最大化,当灵敏度较高时,对参数的局部小更改可能导致损失函数值的大幅变化。
本文的主要贡献是提出一个简单的模型以及任务无关的元学习算法,它通过训练一个模型参数初始值,只需少量得梯度更新步骤就能快速学习新任务。该算法适用于不同的模型类型,包括全连通和卷积网络,以及多个不同的领域,包括小样本回归、图像分类和增强学习。评估表明,通过与最先进元学习算法比较,特别比较了有监督分类算法,本文算法使用更少的参数。同样适用于回归任务,并且可以在任务可变性存在的情况下加速强化学习,大大优于初始化时的直接预训练。
2 Model-Agnostic Meta-Learning
我们的目标是训练模型,以实现快速适应。任务设定是小样本学习。在本节中,我们将定义任务设定并给出算法的一般形式。
2.1 定义元学习问题
小样本元学习的目标是训练一个模型,它可以快速地适应一个新的任务,只使用几个数据点和训练迭代。为了实现这一目标,模型或学习者在元学习阶段接受了一系列任务的训练,这样,经过训练的模型只需使用少量的例子或试验就可以快速适应新的任务。实际上,元学习问题将整个任务视为训练示例。在本节中,我们将以一种通用的方式形式化这种元学习问题设置,包括不同学习领域的简单示例。我们将在第三部分详细讨论两个不同的学习领域。
考虑模型 f f f将观察 x x x映射到 a a a。在元学习过程中,该模型被训练成能够适应大量或无限数量的任务。由于我们想将我们的框架工作应用于各种学习问题,从分类到强化学习,我们在下面介绍一个学习任务的一般概念。形式上每个任务 T = { L ( x 1 , a 1 , . . . , x H , a H ) , q ( x 1 ) , q ( x t + 1 ∣ x t , a t ) , H } \mathcal T = \{ \mathcal L(x_1,a_1, ...,x_H,a_H), q(x_1),q(x _ {t+1} | x_t, a_t),H \} T={ L(x1,a1,...,xH,aH),q(x1),q(xt+1∣xt,at),H}。 L \mathcal L L 是损失函数, q ( x 1 ) q(x_1) q(x1)是初始观察 x x x的分布 q ( x t + 1 ∣ x t , a t ) q(x _ {t+1} | x_t, a_t) q(xt+1∣xt,at)是过渡分布,episode大小是 H H H。在**i.i.d.**监督学习问题, H = 1 H=1 H=1。该模型可以通过在 t t t时刻选择一个输出 a t a_t at来生成长度为 H H H的样本。损失函数 L ( x 1 , a 1 , . . . , x H , a H ) → R \mathcal L(x_1,a_1, ...,x_H,a_H) \to \mathbb R L(x1,a1,...,xH,aH)→R提供特定于任务的反馈,反馈的形式可能是错误分类损失或马尔可夫决策过程中的成本函数。
在我们的元学习场景中,我们考虑任务分布 p ( T ) p(\mathcal T) p(T),我们希望我们的模型能够适应这种分布。在 K K K-shot学习任务中,训练模型从任务分布 p ( T ) p(\mathcal T) p(T)中抽取一个任务 T i \mathcal T_i Ti,从 q i q_i qi中抽取 K K K个样本用以生成任务 T i \mathcal T_i Ti的反馈损失 L T i \mathcal L_{T_i} LTi,最后从 T i T_i Ti中选取新任务作为测试。然后,通过考虑从 q i q_i qi产生的新数据的测试误差随参数的变化情况,对模型 f f f进行了改进。
通常,将任务 T i T_i Ti的测试误差视作元学习过程的训练误差。在元训练结束时,从 p ( T ) p(T) p(T)中抽取新的任务样本,通过学习 K K K个样本后模型的性能来衡量元性能。通常,用于元测试的任务是在元训练期间进行的(元学习的训练过程中,是对多个不同任务的学习,这个学习过程包含了(元训练和元测试))。
2.2 A Model-Agnostic Meta-Learning Algorithm
与之前的研究不同的是,之前的研究试图训练能够摄取整个数据集的递归神经网络 (San-
toro et al., 2016; Duan et al., 2016b) 或特征嵌入,这些可以在测试时与非参数方法相结合(Vinyals et al., 2016; Koch, 2015),我们提出了一种通过元学习来学习一种方法,用来学习任何标准模型的参数,使模型能够快速适应(参数学习方法,用以实现快速适应)。这种方法背后的直觉是,一些内部表示比其他表示更容易迁移。例如,神经网络可以学习广泛适用于 p ( T ) p(T) p(T)中的所有任务的内部特征,而不是单个任务。我们如何才能鼓励出现这样的通用表示呢?
我们采取明确的方法来解决这个问题:由于模型将使用基于梯度的学习规则对新任务进行微调,我们的目标是学习这样一个模型,在不过拟合的情况下,这种基于梯度的学习规则可以快速地处理从 p ( T ) p(T) p(T)中提取的新任务。实际上,我们的目标是找到对任务中的更改敏感的模型参数,这样,当在梯度方向上改变这个损失,参数的微小变化将对从 p ( T ) p(T) p(T)中抽取的任何任务的损失函数产生较大的变化,见图1. 我们没有对模型的形式做任何假设,只是假设它是由某个参数向量 θ \theta θ参数化的,并且损失函数在 θ \theta θ中足够光滑,因此我们可以使用基于梯度的学习技术。
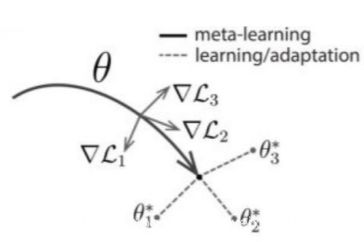
图1:MAML)关系图,它优化了表示形式 θ \theta θ,从而能够快速适应新任务。
在形式上,我们考虑一个由参数 θ \theta θ表示的参数化函数 f θ f_\theta fθ表示的模型。当学习新任务 T i T_i Ti时,模型参数从 θ \theta θ变成 θ i ′ \theta_i' θi′。更新后的参数变量 θ i ′ \theta_i' θi′是在任务 T i T_i Ti中经过一到多步梯度下降得到。比如一步梯度更新表示为: θ i ′ = θ i − α ∇ L T i ( f θ ) . \theta_i' = \theta_i - \alpha \nabla \mathcal L_{\mathcal T_i}(f_\theta). θi′=θi−α∇LTi(fθ). 步长 α \alpha α可以固定为超参数或元学习。为了表示简单,我们将在本节的其余部分考虑一步梯度更新,但是使用多步梯度更新是一个简单的扩展。
通过优化从 p ( T ) p(T) p(T)中采样的任务 f θ i ′ f_{\theta_i'} fθi′相对于 θ \theta θ的性能,来训练模型参数。更具体的,元-目标如下所示: min θ ∑ T i ∼ p ( T ) L T i ( f θ i ′ ) = ∑ T i ∼ p ( T ) L T i ( f θ − α ∇ L T i ( f θ ) ) \min_{\theta} \sum_{\mathcal T_i \sim p(\mathcal T)} \mathcal L_{\mathcal T_i}(f_{\theta_i'}) = \sum_{\mathcal T_i \sim p(\mathcal T)} \mathcal L_{\mathcal T_i}(f_{\theta- \alpha \nabla \mathcal L_{\mathcal T_i}(f_\theta)} ) θminTi∼p(T)∑LTi(fθi′)=Ti∼p(T)∑LTi(fθ−α∇LTi(fθ))
注意,元优化是在模型参数 θ \theta θ上执行的,而目标是使用更新的模型参数 θ ′ \theta' θ′计算的。实际上,我们提出的方法旨在优化模型参数,使在新任务上经过一步或少量梯度步骤就能取得最大性能表现。
任务间的元优化是通过随机梯度下降(SGD)实现的,使模型参数 θ \theta θ更新如下:

其中 β \beta β是元步长,完整的算法在下图中进行概述。

p(T) 任务分布集合
α、β步长超参数
>1 随机初始化参数 θ
>2 条件内执行,如迭代次数
>3 取batch个任务
>4 遍历batch中每一个任务Ti
>5 取K个样本用模型f(θ)计算损失的偏导∇
>6 使用梯度更新每个任务的θi′ = θi − α∇(本算法对每个子任务只使用一步梯度)
>7 end for结束本次batch
>8 更新全局参数 θ ,全局损失∇为batch个任务损失之和。由每个任务Ti的θi′ 计算f(θi′)得到∇
>9 重复以上步骤“迭次次数”次,得到最终的θ
MAML的元梯度更新包含一个梯度到另一个梯度,在计算上,这需要一个额外的反向传播,通过 f f f来计算海森向量积,这个计算由标准的深度学习库(如TensorFlow)支持(Abadi et al., 2016)。在实验中,本文比较了不采用这个反向传播而使用一阶近似的方法,在第5.2节中讨论。(实验细节)
3 Species of MAML
在本节中,我们将讨论用于监督学习和强化学习的元学习算法的具体实例。这些领域在损失函数的形式、任务生成数据的方式以及任务生成数据并将数据呈现给模型的方式,但在这两种情况下都可以应用相同的基本适应机制。
3.1 有监督回归和分类任务
在监督任务领域中,少样本学习得到了很好的研究,其目标是使用元学习中类似任务的先前数据,仅从该任务的几个输入/输出对中学习一个新函数。例如,目标可能是在只看到Segway的一个或几个例子后对图像进行分类,而模型之前已经看到了许多其他类型的对象。同样,在小样本回归中,目标是通过对具有相似统计特性的许多函数进行训练后,仅从该函数抽样的几个数据点预测连续值函数的输出。
我们在2.1节元学习定义的框架下形式化监督回归和分类问题,定义episode大小 H = 1 H = 1 H=1并去掉 x t x_t xt的timestep下标,因为模型接受一个输入,产生一个输出,而非序列输入和输出。任务 T i T_i Ti生成K个样本,观察值 x x x从分布 q i q_i qi取得,任务损失由模型对x的输出与对应的观测任务目标值y之间的误差表示。(观察值 x x x从分布 q i q_i qi取得??是啥)
通常监督回归和分类问题使用的两种loss函数是交叉熵和均方误差,将在下面描述。回归问题使用均方差,损失函数定义为:

x ( j ) x^{(j)} x(j)和 y ( j ) y^{(j)} y(j)是任务Ti的输入/输出对。K-shot回归任务是指每个任务包含K对输入输出。(不是用很多数据训练吗,怎么是K对)
离散分类任务使用交叉熵loss函数:

传统的,K-shot分类任务指每一类使用K对输入输出,N-way分类一共NK对数据(N个类别每类K对样本)。给定任务分布 p ( T i ) p(T_i) p(Ti),损失函数可以直接嵌入2.2节的返程中进行元学习,具体算法如下:

p(T) 任务分布集合
α、β步长超参数
>1 随机初始化参数 θ
>2 条件内执行,如迭代次数
>3 取batch个任务
>4 遍历batch中每一个任务Ti
>5 取与任务Ti对应的每类K个数据对D
>6 使用数据D和损失函数L计算模型f(θ)的损失的偏导∇
>7 使用梯度更新每个任务的θi′ = θi − α∇(本算法对每个子任务只使用一步梯度)
>8 记录本次任务Ti的数据对Di‘用于全局元更新(10)
>9 end 结束本次batch
>10 更新全局参数 θ ,全局损失偏导∇为batch个任务损失偏导之和。由每个任务Ti的θi′ 以及所对应的数据Di'计算f(θi′)得到∇。
>11 重复以上步骤“迭次次数”次,得到最终的θ(这是一个良好的参数初始点)
3.2 强化学习
不对强化学习做解读。

4 Related Work
本文提出的方法适用于一般的元学习问题如小样本学习(Thrun & Pratt, 1998; Schmidhuber, 1987; Naik & Mammone, 1992),元学习的一个流行方法是训练一个元学习器,让他学习如何更新学习器模型的参数(Bengio et al.,1992; Schmidhuber, 1992; Bengio et al., 1990),该方法已应用于学习深度网络的优化(如Adam)(Hochreiter et al., 2001; Andrychowicz et al., 2016;Li & Malik, 2017)以及学习动态变化的递归网络(Ha et al., 2017)。最近的一种方法学习了权值初始化和优化器,用于小样本图像识别(Ravi & Larochelle,2017)(本文的最优初始化权重是不是借鉴了这个思想?)。与上述方法都不同,MAML学习器的权重是使用梯度来更新的,而不是通过学习来更新的;我们的方法不为元学习引入额外的参数,也不需要特定的学习器体系结构**(与模型无关的元学习?)**
有的研究(Vinyals et al., 2016)针对生成模型和图像识别等特定任务,开发了小样本学习方法。其中较成功的小样本分类方法是学习**“在一个学习的度量空间中比较新的样本”,例如Siamese networks (Koch, 2015)或带有注意机制的递归网络(Vinyals et al., 2016; Shyam et al., 2017; Snell et al., 2017)。这些方法产生了一些成功的结果,但很难直接扩展到其他问题,如强化学习。相反,我们的方法与模型的形式和特定的学习任务无关。元学习的另一种方法是在许多任务上训练记忆增强模型**,在这些任务中,循环学习器被训练在新任务推出时适应新任务,这种网络已被应用于小样本图像识别 (Santoro et al., 2016; Munkhdalai & Yu, 2017) 和学习“快速”增强学习agents (Duan et al.,2016b; Wang et al., 2016).实验结果表明,本文的方法在小样本分类上优于上述递归方法。此外,与这些方法不同的是,我们的方法只是提供了一个良好的权重初始化,并对学习器和元更新使用相同的梯度下降更新。因此,通过对学习器进行额外的几步梯度更新微调参数就能适用新任务。
(介绍迁移学习)我们的方法也与深度网络的初始化方法有关。在计算机视觉中,经过大规模图像分类训练的模型已被证明能够学习一系列问题的有效特征(Donahue et al.,2014)。相比之下,我们的方法显式地优化模型以获得快速的适应性,允许它仅通过几个例子就能适应新的任务。我们的方法还可以看作是显式地最大化新任务损失对模型参数的敏感性。许多先前的工作已经探索了深层网络中的敏感性,通常是在初始化的上下文中(Saxe et al., 2014; Kirkpatrick et al., 2016)。这些工作中的大多数都考虑了良好的随机初始化,尽管一些论文已经解决了数据依赖的初始化(Kr¨ ahenb¨ uhl et al., 2016; Salimans &Kingma, 2016),包括学习的初始化(Husken & Goerick, 2000; Maclaurin et al., 2015)。相比之下,我们的方法明确地训练了给定任务分布的敏感性参数,允许非常有效地适应问题,例如K-shot学习和快速强化学习,只需要一个或几个梯度步骤。
5 实验评估
评估目标是回答下列问题:(1)MAML能快速学习新任务吗?(2)MAML能否用于不同得领域包括监督回归、分类、强化学习(3)使用MAML学习的模型能否通过添加梯度更新和/或示例继续改进?
我们考虑的所有元学习问题都需要在测试时对新任务进行一定程度的适应。如果可能,我们将预测结果与oracle(真实标签??)进行比较,oracle接收任务的标识(这是一个依赖于问题的表示)作为附加输入,作为模型性能的上限。所有的实验都是使用TensorFlow (Abadi et al.2016)进行的,该方法允许在元学习过程中通过梯度更新自动进行微分
5.1 回归任务
我们从一个简单的回归问题开始,它说明了MAML的基本原则。每个任务都涉及到从输入到输出正弦波的回归,正弦波的振幅和相位在不同的任务之间是不同的。因此,任务分布 p ( T ) p(T) p(T)是连续的,振幅在[0.1,5.0]内变化,相位在[0,pi]内变化,输入和输出的维数均为1。在训练和测试期间,数据点x从[5.0,5.0]均匀采样。损失是预测f(x)与真实值之间的均方误差。回归器是一个具有2个隐层的神经网络模型,隐层大小为40,使用ReLU非线性激活。在使用MAML进行训练时,我们使用一步梯度更新,其中示例K=10,步骤大小固定 α = 0.01 \alpha=0.01 α=0.01,并使用Adam作为元优化器(Kingma & Ba, 2015)。参考基准模型同样由Adam训练。为了评估性能,我们在不同数量的K个示例上微调单个元学习模型,并将性能与两个baselines进行比较:(a)预先训练所有任务,这需要训练网络回归到随机正弦函数,然后,在测试时,使用自动调整的步长,在提供的K个点上使用梯度下降进行微调,以及(b)接收真实幅度和相位作为输入的oracle。 在附录C中,我们展示了与其他多任务和适应方法的比较。
我们通过微调MAML学习的模型和K = {5,10,20}数据点上的预训练模型来评估性能。 在微调期间,使用相同的K数据点计算每个梯度步骤。 定性结果,如图2所示,并在附录B中进一步扩展,表明学习模型能够快速适应仅5个数据点,显示为紫色三角形,而使用标准监督学习对所有任务进行预训练的模型无法 在没有灾难性过度拟合的情况下充分适应如此少的数据点。关键是,当K个数据点都在输入范围的一半时,用MAML训练的模型仍然可以推断该范围的另一半中的幅度和相位,证明MAML训练的模型 f f f已经学会模拟正弦波的周期性质。此外,我们在定性和定量结果(图3和附录B)中都观察到,使用MAML学习的模型在附加梯度步骤的情况下继续改进,尽管在一个梯度步骤之后进行了最大性能的训练。这一改进表明MAML优化了参数,使得它们位于一个易于快速适应的区域,并且对 p ( T ) p(T) p(T)的损失函数很敏感,如2.2节所述,而不是过度拟合到仅在一步后改善的参数 θ \theta θ。
下图2展示MAML得拟合性能

下图3:定量的正弦回归结果显示学习曲线在元测试时得表现。注意,在元测试过程中,MAML继续通过额外的梯度步骤进行改进,虽然数据集非常小但没有过拟合,从而实现了比baseline微调方法低得多的损失(能更快速的降低loss)

5.2 分类
为了评价MAML与之前的元学习和小样本学习算法的比较,将我们的方法应用于Omniglot (Lake et al.2011)和MiniImagenet数据集上的小样本图像识别。Omniglot数据集由来自50个不同字母的1623个字符的20个实例组成。每个实例都是由不同的人绘制的。MiniImagenet数据集是由Ravi& Larochelle (2017)提出,涉及64个训练集,12个验证集,24个测试集。Omniglot和MiniImagenet图像识别任务是目前最常用的小样本学习基准测试 (Vinyals et al., 2016; Santoro et al., 2016; Ravi & Larochelle, 2017)。
我们遵循by Vinyals et al. (2016)提出的实验方案,涉及快速学习1 or 5 shots的N-way分类。 N路分类的问题设置如下:选择N个不可见的类,为模型提供N个类中每个类的K个不同实例,并评估模型在N个类中对新实例进行分类的能力。 对于Omniglot,我们随机选择1200个字符进行训练,不论字母表如何,并使用剩余的字符进行测试。 按照Santoro et al. (2016)的提议,对Omniglot数据集进行90度旋转扩充数据量。
我们的模型遵循与Vinyals et al. (2016)使用的嵌入函数相同的体系结构:包含四个带有33卷积64个过滤器的模块,使用了batch normalization(Ioffe & Szegedy, 2015)、ReLU非线性单元、22的max-pooling。Omniglot图像降采样到28*28故最后一隐藏层维度为64。类似测试基准Vinyals et al. (2016)对最后一层softmax。对Omniglot没有使用max-pooling而采用strided convolutions( 卷积步长卷积后向右移动s步实现类似池化的功能)。对MiniImagenet每一层使用32个filters以减少过拟合(Ravi & Larochelle,2017)。为了与记忆增强神经网络(Santoro et al., 2016)进行公平的比较,同时测试MAML的灵活性,我们也提供了一个非卷积网络的结果。为此,我们使用了一个包含4个隐藏层的网络,大小分别为256、128、64、64,每个隐藏层包括batch normalization和ReLU非线性单元,然后是线性层和softmax。所有模型都是用交叉熵损失。其他超参数见附录A.1.
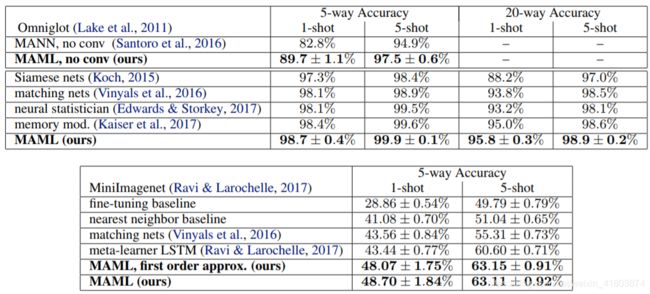
在Table1展示结果。由MAML学习的卷积模型取得最好结果。而现有的一些方法,如匹配网络、Siamese网络和memory models,在设计时考虑了小样本分类,但并不适用于强化学习等领域。另外由MAML学习的模型相比matching networks and the meta-learner LSTM具有更少的overall parameters,因为该算法不会引入超出分类器本身权重的任何附加参数。与这些先前的方法相比,记忆增强神经网络(Santoro et al., 2016),特别是循环元学习模型,代表了一种更广泛适用的方法,像MAML,可以用于其他任务,如强化学习(Duan et al., 2016bb; Wang et al.,2016)。从比较中可以看出,MAML在5-way Omniglot上的性能明显优于memory-augmented网络和meta-learner LSTM;在1-shot和5-shot两种情况下,MAML在MiniImagenet分类上完胜其他选手。
MAML中的显著计算开销来自于通过元目标中的梯度算子反向传播元梯度时使用二阶导数,见公式1。在MiniImagenet上,我们给出了与一阶近似MAML的比较,其中省略了这些二阶导数。注意,生成的方法仍然在更新后的参数值 θ i ′ \theta_i' θi′处计算元梯度,这为有效的元学习提供了条件。然而令人惊讶的是,这种方法的性能与完全二阶导数得到的几乎相同,说明MAML的改进主要来自更新后参数值处目标的梯度,而不是通过梯度更新微分得到的二阶更新。以前的工作发现ReLU神经网络在局部几乎是线性的 (Goodfellow et al.,2015),这表明二阶导数在大多数情况下可能接近于零,部分解释了一阶近似的良好性能。这种近似消除了在额外的向后传递中计算Hessian-vector积的需要,我们发现这导致网络计算的速度提高了大约33%。
5.3强化学习


6. Discussion and Future Work
提出了一种基于梯度下降学习模型参数的元学习方法。我们的方法有很多好处。它很简单,并且没有为元学习引入任何学习参数。它可以与任何适合于基于梯度的训练的模型表示以及任何可微分的目标(包括分类、回归和强化学习)相结合。最后,由于我们的方法只生成一个权重初始化,因此可以使用任意数量的数据和任意数量的梯度步骤来执行自适应,我们在分类方面展示了最先进的结果,每个类只有一个或五个例子。我们还展示了我们的方法可以使用策略梯度和非常有限的经验来适应RL agent。
重用来自过去任务的知识可能是构建高容量可伸缩模型(如深度神经网络)的关键因素,该模型能够使用小数据集进行快速训练。我们相信,这项工作是朝着一个简单而通用的元学习技术迈出的一步,该技术可以应用于任何问题和任何模型。进一步的研究可以使多任务初始化成为深度学习和强化学习的标准组成部分。
A. Additional Experiment Details
在本节中,我们将提供有关实验设置和超参数的更多细节。
Classification
对于N-way, K-shot classification,每个梯度都是使用NK个示例的batch计算的。对Omniglot,5路卷积和非卷积MAML模型使用1步梯度训练,步长 α = 0.4 \alpha=0.4 α=0.4,元批大小为32个任务,模型评估使用3步梯度,步长 α = 0.4 \alpha=0.4 α=0.4。20-way卷积MAML模型训练和验证都使用5步梯度更新,步长 α = 0.1 \alpha=0.1 α=0.1,训练阶段的batch-size为16个任务。对MiniImagenet,两种模型都使用5步梯度更新,步长 α = 0.01 \alpha=0.01 α=0.01,并在测试时使用10步梯度更新进行评估。参考Ravi & Larochelle(2017)每个类使用15个例子来评估更新后的元梯度。我们使用元batch大小为4和2个任务分别用于1shot和5shot训练。所有的模型都在一个NVIDIA Pascal Titan X GPU上训练了60000次迭代。
B. Additional Sinusoid Results
在下图6中,我们展示了经过10次学习训练的MAML模型的全部定量结果,并分别在5shot、10shot和20shot上进行了评估。在图7中,我们展示了maml和预训练baselines在随机采样正弦信号上的定性性能。

C. Additional Comparisons
在本节中,我们将对我们的方法进行更全面的评估,包括额外的多任务baselines和与Rei (2015).方法的比较。
C.1. Multi-task baselines
主要文本中的预训练基线在所有任务上训练了一个网络,我们称之为对所有任务进行预训练。 为了评估模型,与MAML一样,我们使用K示例在每个测试任务上微调此模型。 在我们研究的领域中,不同的任务涉及相同输入的不同输出值。 因此,通过对所有任务进行预训练,模型将学习输出特定输入值的平均输出。 在某些情况下,此模型可能对实际域知之甚少,而是了解输出空间的范围。
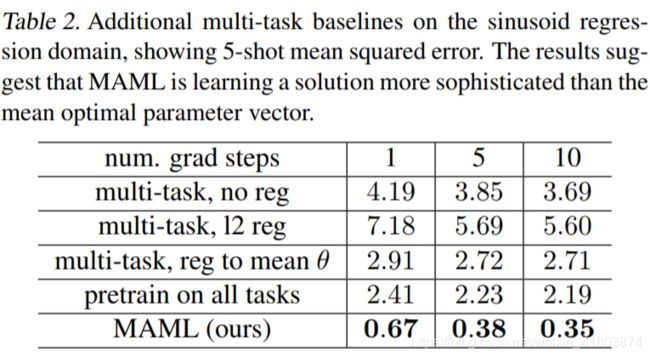
我们尝试使用多任务方法来提供比较点,而不是在输出空间中求平均值,而是在参数空间中求平均值。 为了在参数空间中实现平均,我们依次在从p(T)绘制的500个任务上训练了500个单独的模型。 每个模型都是随机初始化的,并根据其分配的任务对大量数据进行训练。 然后,我们在模型中获取平均参数向量,并在5个数据点上进行微调,并调整步长。 由于计算要求,我们对这种方法的所有实验都是在正弦波任务上进行的。 单个回归量的误差很小:各自的正弦波小于0.02。
我们尝试了这种设置的三种变体。 在训练个体回归量期间,我们尝试使用以下之一:没有正则化,标准L2权重衰减,以及到目前为止训练的回归量的平均参数向量的L2权重正则化。 后两种变体鼓励个体模型找到简约的解决方案。 使用正则化时,我们将正则化的幅度设置得尽可能高,而不会显着降低性能。 在我们的结果中,我们将此方法称为多任务。 如表2中的结果所示,我们发现参数空间(多任务)中的平均值比输出空间中的平均值(所有任务的预训练)更差。 这表明在分别训练任务时难以找到多任务的简约解决方案,并且MAML正在学习比平均最优参数向量更复杂的解决方案。
C.2. Context vector adaptation
Rei(2015)开发了一种方法,该方法可以学习可在线调整的上下文向量,并应用于循环语言模型。 以与MAML模型中的参数相同的方式学习和调整该上下文向量中的参数。 为了比较使用这样的上下文向量进行元学习问题,我们将一组自由参数z连接到输入x,并且只允许渐变步骤修改z,而不是修改模型参数 θ \theta θ,如MAML。
对于图像输入,z与输入图像在通道上连接。 我们按照相同的实验方案在Omniglot和两个RL域上运行此方法。 我们在表3,4和5中报告了结果。学习一个适应性上下文向量在玩具点质量问题上表现良好,但在更困难的问题上低于标准,可能是由于不太灵活的元优化。



别人的阅读:https://blog.csdn.net/weixin_40523230/article/details/85005378
简而言之,MAML做的事情就是:
找到这样一个theta——以这个theta为初始状态,在其他几个task的demo进行微调得到theta‘,计算loss(theta’),然后把这些loss(theta’)求和。如果这个sum(loss(theta’))已经收敛于一个很小的值了,那么这个theta就是我们要的theta。
【注意】本篇文章中在将MAML应用分类、回归、RL时:
“ 求解theta' 的lossfunction”和“基于sum来求解 theta使用的loss function”,是完全相同的loss function。即 Lv = Ltr 。之所以提这一点,是因为这两个函数在某些问题时是可以不同的。
“基于sum来求解 theta使用的loss function”是用来评估并更新theta,使得theta产生的action尽可能逼近真实的action,所以此处我们需要使用常见的loss function,比如MSEor交叉熵。
而“ 用来求解theta' 的loss function”,作用是让theta被更新到theta’,说白了就是需要这个loss function产生梯度来更新theta,【至于我们期望更新后的结果theta’是一个什么样的状态,这个问题待定。如果按照原作的方法,继续使用标准的loss function,固然会以一个比较好的方式收敛,此时得到的theta’是一个能逼近真实action的theta’,但针对具体Ti,我们其实不希望theta’是“能够逼近具体任务groundtruth的参数”。我们,真正希望得到的,是一个能够逼近通用参数的theta'。So,是不是还可以人为设计一些新的loss function函数?或者通过其他方式得到loss function?】。所以其实此处的loss function不一定要是标准的loss function(MSE or 交叉熵)。
个人理解,MAML的特点是:
1. 在meta-training阶段,针对每个task的demo只需要进行微调,这意味着快速,对样本需求量少。
2. 可以快速基于小样本数,小迭代数(这个我不确定),成功的学习一个新task(其实第二点之所以成功的机制,还是来源于第一点)。