注意力机制论文:GCNet: Non-local Networks Meet Squeeze-Excitation Networks and Beyond及其PyTorch实现
GCNet: Non-local Networks Meet Squeeze-Excitation Networks and Beyond
PDF: https://arxiv.org/pdf/1904.11492.pdf
PyTorch代码: https://github.com/shanglianlm0525/PyTorch-Networks
1 概述
- 对于不同的查询点,NLNet学习到的attention map是几乎一致的,即NLNet学习到关于每个位置的全局上下文不受位置依赖
- NLNet计算量比较大,限制了它的使用
- 提出的Simplified NLNet, 极大地减少了NLNet的计算量
- GCNet融合了SENet和NLNet两者的优点,既能够有用NLNet的全局上下文建模能力,又能够像SENet一样轻量。
2 Simplifying the Non-local Block
NL公式
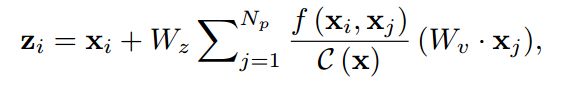
实现发现 W z W_{z} Wz其实是可以省略的, 去掉 W z W_{z} Wz有

将 W u W_{u} Wu移到累加外面

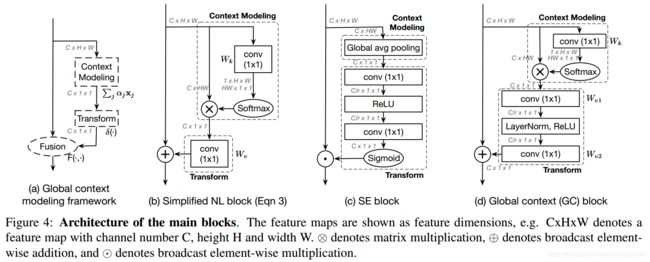
最后得到的Simple NL Block如下图

实验表明Simple NL Block和NL Block性能非常接近.
3 Global Context Block
GCNet在上下文信息建模这个地方使用了Simplified NL block中的机制,可以充分利用全局上下文信息,同时在Transform阶段借鉴了SE block。
4 Ablation
- a. 看出Simplified NL与NL几乎一直,但是参数量要小一些。且每个阶段都使用GC block性能更好。
- b. 在residual block中GC添加在add操作之后效果最好。
- c. 添加在residual 的所有阶段效果最优,能比baseline高1-3%。
- d. 使用简化版的NLNet并使用1×1卷积作为transform的时候效果最好,但是其计算量太大。
- e. ratio=1/4的时候效果最好。
- f. attention pooling+add的的组合用作池化和特征融合设计方法效果最好。

PyTorch代码:
import torch
import torch.nn as nn
import torchvision
class GlobalContextBlock(nn.Module):
def __init__(self,
inplanes,
ratio,
pooling_type='att',
fusion_types=('channel_add', )):
super(GlobalContextBlock, self).__init__()
assert pooling_type in ['avg', 'att']
assert isinstance(fusion_types, (list, tuple))
valid_fusion_types = ['channel_add', 'channel_mul']
assert all([f in valid_fusion_types for f in fusion_types])
assert len(fusion_types) > 0, 'at least one fusion should be used'
self.inplanes = inplanes
self.ratio = ratio
self.planes = int(inplanes * ratio)
self.pooling_type = pooling_type
self.fusion_types = fusion_types
if pooling_type == 'att':
self.conv_mask = nn.Conv2d(inplanes, 1, kernel_size=1)
self.softmax = nn.Softmax(dim=2)
else:
self.avg_pool = nn.AdaptiveAvgPool2d(1)
if 'channel_add' in fusion_types:
self.channel_add_conv = nn.Sequential(
nn.Conv2d(self.inplanes, self.planes, kernel_size=1),
nn.LayerNorm([self.planes, 1, 1]),
nn.ReLU(inplace=True), # yapf: disable
nn.Conv2d(self.planes, self.inplanes, kernel_size=1))
else:
self.channel_add_conv = None
if 'channel_mul' in fusion_types:
self.channel_mul_conv = nn.Sequential(
nn.Conv2d(self.inplanes, self.planes, kernel_size=1),
nn.LayerNorm([self.planes, 1, 1]),
nn.ReLU(inplace=True), # yapf: disable
nn.Conv2d(self.planes, self.inplanes, kernel_size=1))
else:
self.channel_mul_conv = None
def spatial_pool(self, x):
batch, channel, height, width = x.size()
if self.pooling_type == 'att':
input_x = x
# [N, C, H * W]
input_x = input_x.view(batch, channel, height * width)
# [N, 1, C, H * W]
input_x = input_x.unsqueeze(1)
# [N, 1, H, W]
context_mask = self.conv_mask(x)
# [N, 1, H * W]
context_mask = context_mask.view(batch, 1, height * width)
# [N, 1, H * W]
context_mask = self.softmax(context_mask)
# [N, 1, H * W, 1]
context_mask = context_mask.unsqueeze(-1)
# [N, 1, C, 1]
context = torch.matmul(input_x, context_mask)
# [N, C, 1, 1]
context = context.view(batch, channel, 1, 1)
else:
# [N, C, 1, 1]
context = self.avg_pool(x)
return context
def forward(self, x):
# [N, C, 1, 1]
context = self.spatial_pool(x)
out = x
if self.channel_mul_conv is not None:
# [N, C, 1, 1]
channel_mul_term = torch.sigmoid(self.channel_mul_conv(context))
out = out * channel_mul_term
if self.channel_add_conv is not None:
# [N, C, 1, 1]
channel_add_term = self.channel_add_conv(context)
out = out + channel_add_term
return out
if __name__=='__main__':
model = GlobalContextBlock(inplanes=16, ratio=0.25)
print(model)
input = torch.randn(1, 16, 64, 64)
out = model(input)
print(out.shape)