大数据之使用datax完成rds到hdfs,hdfs到rds的导入导出
1、前言
mysql等数据存储技术,随着海量数据的不断增加,已经不能满足正常的业务需求。大数据技术带来的数据仓库为此带来很多解决方案。今天基于京东云的环境简单的搭建一个数据数据仓库,使用阿里出品的datax完成数据的导入和导出。
2、导入导出工具简单介绍
DataX 是阿里巴巴集团内被广泛使用的离线数据同步工具/平台,实现包括 MySQL、Oracle、SqlServer、Postgre、HDFS、Hive、ADS、HBase、TableStore(OTS)、MaxCompute(ODPS)、DRDS 等各种异构数据源之间高效的数据同步功能。datax部分功能是借助于python完成脚本的。
Sqoop:是一款Apache的开源的工具,主要用于在Hadoop(Hive)与传统的数据库(mysql、postgresql...)间进行数据的传递,可以将一个关系型数据库(例如 : MySQL ,Oracle ,Postgres等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。
Kattle:Kettle是一款国外开源的ETL工具,纯java编写,可以在Windows、Linux、Unix上运行,数据抽取高效稳定。
由于京东云提供了datax,笔者就是datax完成数据的导入导出
3、Datax内部数据类型和Mysql的对应关系

4、大数据的分层
ODS(Operational Data Store):基础数据层、元数据层,用来存储基础数据;
DWD(data warehouse detail):数据清洗层,用来去除空值,脏数据,超过极限范围的数据
DWS(data warehouse service): 合成宽表,用来聚合DWD层的数据。
ADS(Application Data Store):出报表结果,用来做分析处理同步到RDS数据库里边
5、案例流转图
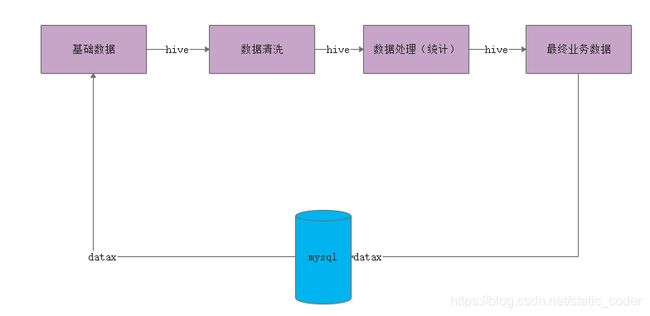
本案例只进行导出和导出,会忽略DWD和DWS层,会将ODS和ADS当成一个数据层处理
6、创建基础数据层(ods层)
在hive中创建数据层:
drop table if exists user_info;
create external table user_info
(
id tinyint comment '用户ID',
username string comment '用户名',
password string comment '用户密码',
password_salt string comment '盐值',
create_time timestamp comment '创建时间',
update_time timestamp comment '更新时间'
)COMMENT '用户信息'
PARTITIONED BY (`dt` string)
row format delimited fields terminated by ','
location '/apps/hive/warehouse/test.db/user_info/';创建数据层的时候,要考虑是否分区、分割符号、存储形式。
1、分区方便数据的更新和删除,本案例是以时间作为分区的。
2、分割符号要考虑你存入的数据,防止存入的数据中包含分割符号,这样在hdfs中的存储的数据再查询的时候就会出现错乱。比如空格。
3、存储形式有一下几种:
hive的默认存储形式是text 。

7、datax的导入脚本test_mysql2hive.json
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": [
"id",
"username",
"password",
"password_salt",
"create_time",
"update_time"
],
"connection": [
{
"jdbcUrl": [
"jdbc:mysql://127.0.0.1:3306/test"
],
"table": [
"user_info"
]
}
],
"password": "******",
"username": "******",
"where": "DATE_FORMAT(create_time,'%Y-%m-%d') = '${dt}'"
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"column": [
{
"name": "id",
"type": "int"
},
{
"name": "username",
"type": "string"
},
{
"name": "password",
"type": "string"
},
{
"name": "password_salt",
"type": "string"
},
{
"name": "create_time",
"type": "timestamp"
},
{
"name": "update_time",
"type": "timestamp"
}
],
"defaultFS": "hdfs://127.0.0.1:8020",
"fieldDelimiter": ",",
"fileName": "user_info",
"fileType": "text",
"path": "/apps/hive/warehouse/test.db/user_info/dt=${dt}",
"writeMode": "append"
}
}
}
],
"setting": {
"speed": {
"channel": "1"
}
}
}
}
8、datax分区导入
1、hive中先建分区
alter table user_info add if not exists partition(dt='2020-07-15');2、导入命令
进入到datax文件下:
python bin/datax.py -p "-Ddt=2020-07-15" job/test_mysql2hive.json3、执行结果:
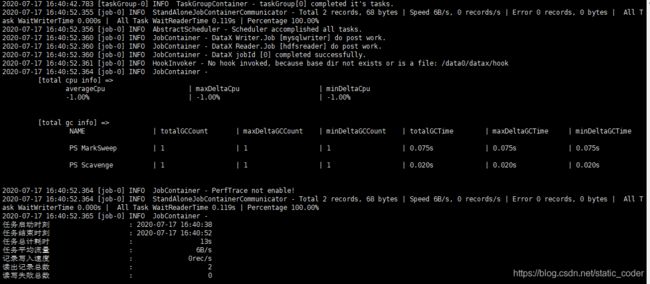
4、 hive中查看结果:

9、导出脚本test_hive2mysql.json
{
"job": {
"content": [
{
"reader": {
"name": "hdfsreader",
"parameter": {
"column": [
{
"index": 1,
"type": "string"
},
{
"index": 2,
"type": "string"
},
{
"index": 3,
"type": "string"
},
{
"index": 4,
"type": "date"
},
{
"index": 5,
"type": "date"
}
],
"defaultFS": "hdfs://127.0.0.1:8020",
"fieldDelimiter": ",",
"fileType": "text",
"path": "/apps/hive/warehouse/test.db/user_info/dt=${dt}"
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"column": [
"username",
"password",
"password_salt",
"create_time",
"update_time"
],
"connection": [
{
"jdbcUrl": "jdbc:mysql://127.0.0.1:3306/test",
"table": [
"users"
]
}
],
"password": "******",
"username": "******",
"writeMode": "insert"
}
}
}
],
"setting": {
"speed": {
"channel": "1"
}
}
}
}
10、datax数据分区导出
导入和导出的命令一直,只是指定的json文件不一样而已
进入到datax文件下:
1、导出命令
python bin/datax.py -p "-Ddt=2020-07-15" job/test_hive2mysql.json2、执行结果
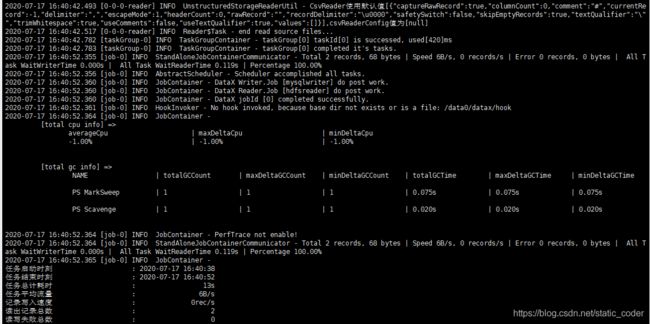
11、总结
以上已经基本完成数据的分区导入和导出,记录一下过程中使用的一些命令吧:
hive启动:./ hive
清空表:insert overwrite table t_table1 select * from t_table1 where 1=0;
修改字段:alter table user_info change id id int;
新增字段:alter table user_info add columns(id int);
修改分隔符:ALTER TABLE ods_sys_organization_region SET SERDEPROPERTIES('field.delim'='\t','serialization.format'='\t');
清空文件: ehco "">文件名
删除hdfs分区文件:./hadoop dfs -rm /apps/hive/warehouse/test.db/user_info/dt=2020-06-29/*
查询hdfs分区文件:./hadoop dfs -ls /apps/hive/warehouse/test.db/user_info/dt=2020-06-29/
创建分区目录:alter table user_info add if not exists partition(dt='2020-06-29');(hive)
删除分区目录:alter table user_info drop if exists partition(dt='2020-06-29'); (软删除)
导入命令:
python bin/datax.py -p "-Ddt=2020-07-15" job/test_mysql2hive.json
导出命令:
python bin/datax.py job/test_hive2mysql.json
删除hdfs中的文件:
./hadoop dfs -rm -r /apps/hive/warehouse/test.db/user_info/dt=2020-06-16
查询hdfs中文件
./hadoop dfs -ls /apps/hive/warehouse/test.db/user_info/
刷新表重新和hdfs建立连接
msck repair table user_info