Spark RDD常见的转化操作和行动操作
Spark RDD常见的转化操作和行动操作
IDEA 创建scala spark的Mvn项目:https://blog.csdn.net/u014646662/article/details/84618032
spark快速大数据分析.pdf下载:https://download.csdn.net/download/u014646662/10816588
1. 针对各个元素的转化操作
2 伪集合操作
对人工智能感兴趣的同学,可以点击以下链接:
现在人工智能非常火爆,很多朋友都想学,但是一般的教程都是为博硕生准备的,太难看懂了。最近发现了一个非常适合小白入门的教程,不仅通俗易懂而且还很风趣幽默。所以忍不住分享一下给大家。点这里可以跳转到教程。
https://www.cbedai.net/u014646662
1. 针对各个元素的转化操作
我们最常用的转化操作应该是map() 和filter(),转化操作map() 接收一个函数,把这个函数用于RDD 中的每个元素,将函数的返回结果作为结果RDD 中对应元素的值。而转化操作filter() 则接收一个函数,并将RDD 中满足该函数的元素放入新的RDD 中返回。
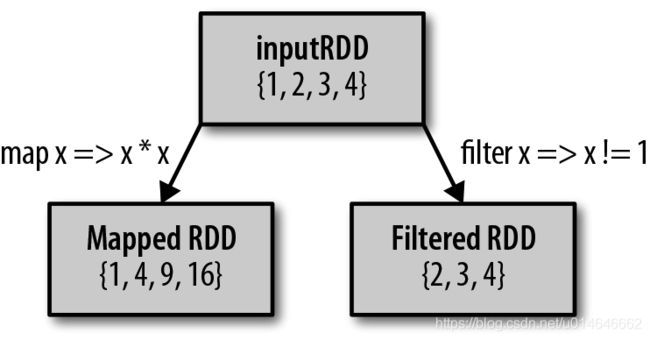
我们可以使用map() 来做各种各样的事情:可以把我们的URL 集合中的每个URL 对应的主机名提取出来,也可以简单到只对各个数字求平方值。map() 的返回值类型不需要和输入类型一样。这样如果有一个字符串RDD,并且我们的map() 函数是用来把字符串解析并返回一个Double 值的,那么此时我们的输入RDD 类型就是RDD[String],而输出类型是RDD[Double]。
让我们看一个简单的例子,用map() 对RDD 中的所有数求平方
scala> val input = sc.parallelize(List(1, 2, 3, 4))
input: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[19] at parallelize at :27
scala> val result = input.map(x => x * x)
result: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[20] at map at :29
scala> println(result.collect().mkString(","))
1,4,9,16
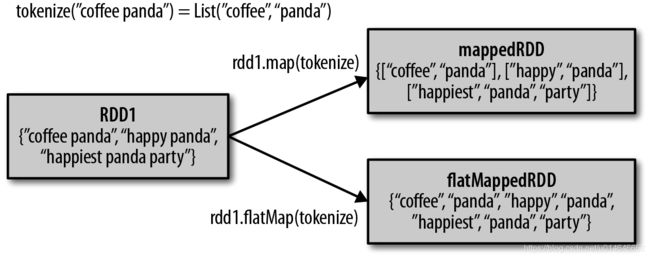
有时候,我们希望对每个输入元素生成多个输出元素。实现该功能的操作叫作flatMap()。和map() 类似,我们提供给flatMap() 的函数被分别应用到了输入RDD 的每个元素上。不过返回的不是一个元素,而是一个返回值序列的迭代器。输出的RDD 倒不是由迭代器组成的。我们得到的是一个包含各个迭代器可访问的所有元素的RDD。flatMap() 的一个简单用途是把输入的字符串切分为单词
scala> def tokenize(ws:String) ={ws.split(" ").toList}
tokenize: (ws: String)List[String]
scala> var lines = sc.parallelize(List("coffee panda","happy panda","happiest panda party"))
lines: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[23] at parallelize at :27
scala> lines.map(tokenize).collect().foreach(println)
List(coffee, panda)
List(happy, panda)
List(happiest, panda, party)
scala> lines.flatMap(tokenize).collect().foreach(println)
coffee
panda
happy
panda
happiest
panda
party
2 伪集合操作
尽管RDD 本身不是严格意义上的集合,但它也支持许多数学上的集合操作,比如合并和相交操作。下图展示了四种操作。注意,这些操作都要求操作的RDD 是相同数据类型的。
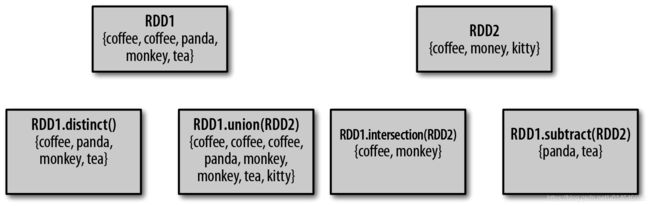
我们的RDD 中最常缺失的集合属性是元素的唯一性,因为常常有重复的元素。如果只要唯一的元素,我们可以使用RDD.distinct() 转化操作来生成一个只包含不同元素的新RDD。不过需要注意,distinct() 操作的开销很大,因为它需要将所有数据通过网络进行混洗(shuffle),以确保每个元素都只有一份。
最简单的集合操作是union(other),它会返回一个包含两个RDD 中所有元素的RDD。这在很多用例下都很有用,比如处理来自多个数据源的日志文件。与数学中的union() 操作不同的是,如果输入的RDD 中有重复数据,Spark 的union() 操作也会包含这些重复数据(如有必要,我们可以通过distinct() 实现相同的效果)。
Spark 还提供了intersection(other) 方法,只返回两个RDD 中都有的元素。intersection()在运行时也会去掉所有重复的元素(单个RDD 内的重复元素也会一起移除)。尽管intersection() 与union() 的概念相似,intersection() 的性能却要差很多,因为它需要通过网络混洗数据来发现共有的元素。
有时我们需要移除一些数据。subtract(other) 函数接收另一个RDD 作为参数,返回一个由只存在于第一个RDD 中而不存在于第二个RDD 中的所有元素组成的RDD。和intersection() 一样,它也需要数据混洗。
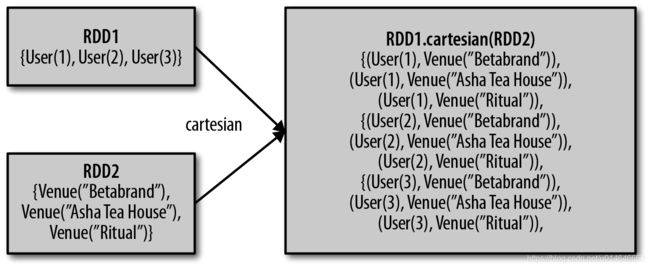
我们也可以计算两个RDD 的笛卡儿积,cartesian(other) 转化操作会返回所有可能的(a, b) 对,其中a 是源RDD 中的元素,而b 则来自另一个RDD。笛卡儿积在我们希望考虑所有可能的组合的相似度时比较有用,比如计算各用户对各种产品的预期兴趣程度。我们也可以求一个RDD 与其自身的笛卡儿积,这可以用于求用户相似度的应用中。不过要特别注意的是,求大规模RDD 的笛卡儿积开销巨大。
1.对一个数据为{1,2,3,3}的RDD进行基本的RDD转化操作
| 函数名 | 目的 | 示例 | 结果 |
| map() |
函数应用于RDD中的每个元素 | rdd.map(x=>x+1) | {2,3,4,4} |
| flatMap() | 将函数应用于RDD中的每个怨毒,通常用来切分单词 | rdd.flatMap(x=>x.to(3)) | {1,2,3,2,3,3,3} |
| filter() | 返回一个通过传给filter()的函数的元素组成的RDD | rdd.filter(x=>x!=1) | {2,3,3} |
| distinct() | 去重 | rdd.distinct() | {1,2,3} |
| sample(withReplacement,fraction,[seed]) | 对RDD进行采样,以及是否替换 | rdd.sample(false,0.5) | 非确定 |
scala> var rdd = sc.parallelize(List(1,2,3,3))
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[11] at parallelize at :27
scala> rdd.distinct().collect().mkString(",")
res9: String = 2,1,3
2.对数据分别为{1,2,3}和{3,4,5}的RDD进行针对两个RDD的转化操作
| 函数名 | 目的 | 示例 | 结果 |
| union() | 生成一个包含两个RDD中所有元素的RDD | rdd.union(other) | {1,2,3,3,4,5} |
| intersection() | 求两个RDD共同的元素RDD | rdd.intersection(other) | {3} |
| subtract() | 移除一个元素的内容 | rdd.subtract(other) | {1,2} |
| cartesian() | 与另一个RDD的笛卡儿积 | rdd.cartesian(other) | {(1,3),(1,4)...(3,5)} |
scala> var rdd = sc.parallelize(List(1,2,3))
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[1] at parallelize at :27
scala> var other = sc.parallelize(List(3,4,5))
other: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[2] at parallelize at :27
scala> rdd.union(other).collect().mkString(",")
res1: String = 1,2,3,3,4,5
scala> rdd.intersection(other).collect().mkString(",")
res2: String = 3 3 行动操作
行动操作reduce(),它接收一个函数作为参数,这个函数要操作两个RDD 的元素类型的数据并返回一个同样类型的新元素。一个简单的例子就是函数+,可以用它来对我们的RDD 进行累加。使用reduce(),可以很方便地计算出RDD中所有元素的总和、元素的个数,以及其他类型的聚合操作。
scala> var rdd = sc.parallelize(List(1,2,3,4,5,6,7))
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[18] at parallelize at :27
scala> var sum = rdd.reduce((x, y) => x + y)
sum: Int = 28 fold() 和reduce() 类似,接收一个与reduce() 接收的函数签名相同的函数,再加上一个“初始值”来作为每个分区第一次调用时的结果。你所提供的初始值应当是你提供的操作的单位元素;也就是说,使用你的函数对这个初始值进行多次计算不会改变结果(例如+对应的0,* 对应的1,或拼接操作对应的空列表)。
fold() 和reduce() 都要求函数的返回值类型需要和我们所操作的RDD 中的元素类型相同。这很符合像sum 这种操作的情况。但有时我们确实需要返回一个不同类型的值。例如,在计算平均值时,需要记录遍历过程中的计数以及元素的数量,这就需要我们返回一个二元组。可以先对数据使用map() 操作,来把元素转为该元素和1 的二元组,也就是我们所希望的返回类型。这样reduce() 就可以以二元组的形式进行归约了。
aggregate() 函数则把我们从返回值类型必须与所操作的RDD 类型相同的限制中解放出来。与fold() 类似,使用aggregate() 时,需要提供我们期待返回的类型的初始值。然后通过一个函数把RDD 中的元素合并起来放入累加器。考虑到每个节点是在本地进行累加的,最终,还需要提供第二个函数来将累加器两两合并。
scala> var rdd = sc.parallelize(List(1,2,3,4,5,6,7))
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[19] at parallelize at :27
scala> var result = rdd.aggregate((0,0))((acc,value) => (acc._1 + value,acc._2 + 1),(acc1,acc2) => (acc1._1 + acc2._1 , acc1._2 + acc2._2))
result: (Int, Int) = (28,7)
scala> var avg = result._1/result._2.toDouble
avg: Double = 4.0
aggregate这个函数稍稍有点麻烦,稍作一下解释
首先构建了一个二元组(0, 0)
再把rdd中的每一个元素构成二元组:(acc, value) => (acc._1 + value, acc._2 + 1),acc就是二元组(0,0),通过本次操作,每一个元素都变成了(n,1)
最后再将二元组合并:(acc1, acc2) => (acc1._1 + acc2._1, acc1._2 + acc2._2)RDD 的一些行动操作会以普通集合或者值的形式将RDD 的部分或全部数据返回驱动器程序中。
把数据返回驱动器程序中最简单、最常见的操作是collect(),它会将整个RDD 的内容返回。collect() 通常在单元测试中使用,因为此时RDD 的整个内容不会很大,可以放在内存中。使用collect() 使得RDD 的值与预期结果之间的对比变得很容易。由于需要将数据复制到驱动器进程中,collect() 要求所有数据都必须能一同放入单台机器的内存中。
take(n) 返回RDD 中的n 个元素,并且尝试只访问尽量少的分区,因此该操作会得到一个不均衡的集合。需要注意的是,这些操作返回元素的顺序与你预期的可能不一样。
这些操作对于单元测试和快速调试都很有用,但是在处理大规模数据时会遇到瓶颈。
如果为数据定义了顺序,就可以使用top() 从RDD 中获取前几个元素。top() 会使用数据的默认顺序,但我们也可以提供自己的比较函数,来提取前几个元素。
有时需要在驱动器程序中对我们的数据进行采样。takeSample(withReplacement, num,seed) 函数可以让我们从数据中获取一个采样,并指定是否替换。
有时我们会对RDD 中的所有元素应用一个行动操作,但是不把任何结果返回到驱动器程序中,这也是有用的。比如可以用JSON 格式把数据发送到一个网络服务器上,或者把数据存到数据库中。不论哪种情况,都可以使用foreach() 行动操作来对RDD 中的每个元素进行操作,而不需要把RDD 发回本地。
关于基本RDD 上的更多标准操作,我们都可以从其名称推测出它们的行为。count() 用来返回元素的个数,而countByValue() 则返回一个从各值到值对应的计数的映射表。表3-4总结了这些行动操作。
对一个数据为{1, 2, 3, 3}的RDD进行基本的RDD行动操作:
| 函数名 | 目的 | 示例 | 结果 |
| collect() | 所有元素 | rdd.collect() | {1,2,3,3} |
| count() | 元素个数 | rdd.count() | 4 |
| countByValue() | 各元素在rdd中出现的次数 | rdd.countByValue() | {(1,1),(2,1),(3,2)} |
| take(num) | 从rdd中返回num个元素 | rdd.take(2) | {1,2} |
| top(num) | 从rdd中返回最前面的num个元素 | rdd.top(2) | {3,3} |
| takeOrdered(num)(ordering) | 按提供的顺序,返回最前面的怒骂个元素 | rdd.takeOrdered(2)(myOrdering) | {3,3} |
| takeSample(withReplacement,num,[seed]) | 从rdd中返回任意一些元素 | rdd.takeSample(false,1) | 非确定的 |
| reduce(func) | 冰雷整合RDD中的所有数据 | rdd.reduce((x,y)=>x+y) | 9 |
| fold(zero)(func) | 和reduce一样,但是需要初始值 | rdd.fold(0)((x,y)=>x+y) | 9 |
| aggregate(zeroValue)(seqOp,combOp) | 和reduce()相似,但是通常返回不同类型的函数 | rdd.aggregate((0,0))((x,y)=>(x,y)=>(x._1+y,x._2+1),(x,y)=>(x._1+y._1,x._2+y._2)) |
(9,4) |
| foreach(func) | 对RDd中的每个元素使用给定的元素 | rdd.foreach(func) | 无 |