论文研读(1)《Summarizing Source Code with Transferred API Knowledge》
前言
20年给自己立了一个阅读论文数量的flag,但有些论文读完后没有实践,过一阵子又会忘记论文中的一些细节,所以2020开一个新的论文研读系列,记录一下自己读过的论文吧。
第一篇论文,《Summarizing Source Code with Transferred API Knowledge》,这篇论文的2018年发表于IJCAI,目前为代码摘要生成的SOTA。主要的创新点为归纳出代码中的 API 方法,首先搭建一个 seq2seq 的模型对 API 进行预训练,并将预训练模型的 encoder 部分加入最终的代码摘要生成模型,实现 encoder 部分的结合。最后通过 decoder 部分生成代码摘要。
论文原文:《Summarizing Source Code with Transferred API Knowledge》
模型结构

上图为整个代码摘要生成的模型结构, 整个模型分为两部分,上面一行为本篇论文创新性的提出的 API 预训练模型,使用 seq2seq 模型,输入代码片段中使用的 API 函数序列(有可能一个代码片段中依次使用了多个 API ),输出为代码摘要。
下面一行的模型为 seq2seq 的代码摘要生成模型,类似于code-nn 的结构(code-nn 为之前次领域的 SOTA 模型),而不同于不普通模型之处在于:整个网络更改为双输入(API sequence 和 code Corpora)。API sequence 进入之前预训练好的模型,生成其 encoder 好的特征向量,并于 code Corpora 部分的 encoder 组合,再进行 decoder ,得到最终的代码摘要。

上图中,图(a)为预训练 API 模型结构,采用 GRU 结构进行 encoder 和 decoder 的操作,同时在 decoder 时加入了 Attention 的机制。
![]()
![]()
![]()

![]()
![]()
(1)式为 encoder 部分,每一时刻 GRU 的 hidden state 由当前时刻输入的 API 向量和前一时刻的 hidden state 共同决定。
(2)式表示 decoder 时,每一时刻的摘要文字输出概率由前一时刻的文字 embedding,该时刻的 decoder hidden state 和该时上下文向量 context vector 共同决定。
(3)式为每一时刻 decoder 的 hidden state 的计算公式,由前一时刻 hidden state,前一时刻的文字 embedding,和该时刻上下文向量 context vector 计算得出。
(4)(5)(6)式为每一时刻上下文向量 context vector 的计算方法,其实质是上一时刻的 decoder hidden state 与 encoder 所有时刻 hidden state 进行注意力机制的计算,得到注意力权重后,将其与 encoder hidden state 做 weighted sum 的结果。
这里有一个细节是:计算 context vector 所使用的是上一时刻的 decoder hidden state 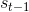 ,这相较于当前时刻
,这相较于当前时刻 来说其实是滞后的,而当前时刻的注意力机制计算体现在
来说其实是滞后的,而当前时刻的注意力机制计算体现在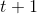 时刻,所以这里在计算当前时刻的 hidden state 时加入的 context vector 其作用其实是对上一时刻 hidden state 的修正和补充。当前时刻的 hidden state
时刻,所以这里在计算当前时刻的 hidden state 时加入的 context vector 其作用其实是对上一时刻 hidden state 的修正和补充。当前时刻的 hidden state  在下一时刻才会使用注意力机制来更新。这与传统的 Attention 机制的计算方式有明显不同。
在下一时刻才会使用注意力机制来更新。这与传统的 Attention 机制的计算方式有明显不同。
图(b)为结合了 API encoder 部分的代码摘要生成 seq2seq 模型。这里只是加入了 API seq2seq 预训练模型的 encoder 部分。

具体的结合方式如(7)式所示,其实是进行了 attention 部分的结合,而整个代码摘要生成部分的计算公式还是与式(1)(2)(3)相同。
实验数据
API 预训练模型方面,论文作者爬取了 Github 上340,922 对
数据的统计如图:

数据样例如图:

结果

出了对比的模型 Code-nn 外,作者还使用了其他三个模型进行对比,分别为:
API-Only:只使用 API 进行摘要生成。
Code-Only:只使用代码片段进行摘要生成。
API+Code:使用 API 和代码片段同时进行摘要生成,但不进行 API 模型的预训练。
TL-CodeSum(fixed):使用预训练 API 和代码片段同时进行摘要生成,但在训练阶段固化 API 模型的权重。
TL-CodeSum(fine-tuned):使用预训练 API 和代码片段同时进行摘要生成,在训练阶继续 fine-tuning API 模型。
最终的结果确实有被震惊,竟然只使用 API 进行代码摘要生成的方式都大幅超越了 code-nn 的效果,而论文提出的模型的效果更加有效,看来预训练还是起到了很大的效果。

最后,作者将 API 预训练模型得到的 API embedding 进行降维可视化,可以看到对 API 的语义或作用进行了很好的 embedding。 真是万物皆可 embedding。
如有问题欢迎指正,转载请注明出处。