实验笔记之——基于RRDBNet的Octave Convolution实验记录
本博文对RRDBNET进行改进,将里面的conv层改为octave conv层。
关于ESRGAN可以参考本文之前的博客《 基于pytorch的ESRGAN(论文阅读笔记+复现)》
先复现RRDBNET


![]()
网络结构
##############################################################################################
##################this is ESRGAN
class RRDBNet(nn.Module):
def __init__(self, in_nc, out_nc, nf, nb, gc=32, upscale=4, norm_type=None, \
act_type='leakyrelu', mode='CNA', upsample_mode='upconv'):
super(RRDBNet, self).__init__()
n_upscale = int(math.log(upscale, 2))
if upscale == 3:
n_upscale = 1
fea_conv = B.conv_block(in_nc, nf, kernel_size=3, norm_type=None, act_type=None)
# rb_blocks = [B.RRDB(nf, kernel_size=3, gc=32, stride=1, bias=True, pad_type='zero', \
# norm_type=norm_type, act_type=act_type, mode='CNA') for _ in range(nb)]
rb_blocks = [B.RRDBTiny(nf, kernel_size=3, gc=32, stride=1, bias=True, pad_type='zero', \
norm_type=norm_type, act_type=act_type, mode='CNA') for _ in range(nb)]
LR_conv = B.conv_block(nf, nf, kernel_size=3, norm_type=norm_type, act_type=None, mode=mode)
if upsample_mode == 'upconv':
upsample_block = B.upconv_blcok
elif upsample_mode == 'pixelshuffle':
upsample_block = B.pixelshuffle_block
else:
raise NotImplementedError('upsample mode [{:s}] is not found'.format(upsample_mode))
if upscale == 3:
upsampler = upsample_block(nf, nf, 3, act_type=act_type)
else:
upsampler = [upsample_block(nf, nf, act_type=act_type) for _ in range(n_upscale)]
HR_conv0 = B.conv_block(nf, nf, kernel_size=3, norm_type=None, act_type=act_type)
HR_conv1 = B.conv_block(nf, out_nc, kernel_size=3, norm_type=None, act_type=None)
self.model = B.sequential(fea_conv, B.ShortcutBlock(B.sequential(*rb_blocks, LR_conv)),\
*upsampler, HR_conv0, HR_conv1)
def forward(self, x):
x = self.model(x)
return x
##############################################################################################
再设计OCTAVE_RRDB
class ResNetBlock(nn.Module):
'''
ResNet Block, 3-3 style
with extra residual scaling used in EDSR
(Enhanced Deep Residual Networks for Single Image Super-Resolution, CVPRW 17)
'''
def __init__(self, in_nc, mid_nc, out_nc, kernel_size=3, stride=1, dilation=1, groups=1, \
bias=True, pad_type='zero', norm_type=None, act_type='relu', mode='CNA', res_scale=1):
super(ResNetBlock, self).__init__()
conv0 = conv_block(in_nc, mid_nc, kernel_size, stride, dilation, groups, bias, pad_type, \
norm_type, act_type, mode)
if mode == 'CNA':
act_type = None
if mode == 'CNAC': # Residual path: |-CNAC-|
act_type = None
norm_type = None
conv1 = conv_block(mid_nc, out_nc, kernel_size, stride, dilation, groups, bias, pad_type, \
norm_type, act_type, mode)
# if in_nc != out_nc:
# self.project = conv_block(in_nc, out_nc, 1, stride, dilation, 1, bias, pad_type, \
# None, None)
# print('Need a projecter in ResNetBlock.')
# else:
# self.project = lambda x:x
self.res = sequential(conv0, conv1)
self.res_scale = res_scale
def forward(self, x):
res = self.res(x).mul(self.res_scale)
return x + resclass OctaveResBlock(nn.Module):
'''
ResNet Block, 3-3 style
with extra residual scaling used in EDSR
(Enhanced Deep Residual Networks for Single Image Super-Resolution, CVPRW 17)
'''
def __init__(self, in_nc, mid_nc, out_nc, kernel_size=3, alpha=0.75, stride=1, dilation=1, groups=1, \
bias=True, pad_type='zero', norm_type=None, act_type='prelu', mode='CNA', res_scale=1):
super(OctaveResBlock, self).__init__()
conv0 = OctaveConv(in_nc, mid_nc, kernel_size, alpha, stride, dilation, groups, bias, pad_type, \
norm_type, act_type, mode)
if mode == 'CNA':
act_type = None
if mode == 'CNAC': # Residual path: |-CNAC-|
act_type = None
norm_type = None
conv1 = OctaveConv(mid_nc, out_nc, kernel_size, alpha, stride, dilation, groups, bias, pad_type, \
norm_type, act_type, mode)
self.res = sequential(conv0, conv1)
self.res_scale = res_scale
def forward(self, x):
#if(len(x)>2):
#print(x[0].shape," ",x[1].shape," ",x[2].shape," ",x[3].shape)
#print(len(x))
res = self.res(x)
res = (res[0].mul(self.res_scale), res[1].mul(self.res_scale))
x = (x[0] + res[0], x[1] + res[1])
#print(len(x),"~~~",len(res),"~~~",len(x + res))
#return (x[0] + res[0], x[1]+res[1])
return x参考上面来改进RRDB
################################################################################################
class octave_ResidualDenseBlockTiny_4C(nn.Module):
'''
Residual Dense Block
style: 4 convs
The core module of paper: (Residual Dense Network for Image Super-Resolution, CVPR 18)
'''
def __init__(self, nc, kernel_size=3, gc=16,alpha=0.5, stride=1, bias=True, pad_type='zero', \
norm_type=None, act_type='leakyrelu', mode='CNA'):
super(octave_ResidualDenseBlockTiny_4C, self).__init__()
# gc: growth channel, i.e. intermediate channels
self.conv1 =OctaveConv(nc, gc, kernel_size, alpha, stride, bias=bias, pad_type=pad_type, \
norm_type=norm_type, act_type=act_type, mode=mode)
# conv_block(nc, gc, kernel_size, stride, bias=bias, pad_type=pad_type, \
# norm_type=norm_type, act_type=act_type, mode=mode)
self.conv2 = OctaveConv(nc+gc, gc, kernel_size, alpha, stride, bias=bias, pad_type=pad_type, \
norm_type=norm_type, act_type=act_type, mode=mode)
# conv_block(nc+gc, gc, kernel_size, stride, bias=bias, pad_type=pad_type, \
# norm_type=norm_type, act_type=act_type, mode=mode)
self.conv3 = OctaveConv(nc+2*gc, gc, kernel_size, alpha, stride, bias=bias, pad_type=pad_type, \
norm_type=norm_type, act_type=act_type, mode=mode)
# conv_block(nc+2*gc, gc, kernel_size, stride, bias=bias, pad_type=pad_type, \
# norm_type=norm_type, act_type=act_type, mode=mode)
if mode == 'CNA':
last_act = None
else:
last_act = act_type
self.conv4 = OctaveConv(nc+3*gc, nc, kernel_size, alpha, stride, bias=bias, pad_type=pad_type, \
norm_type=norm_type, act_type=act_type, mode=mode)
# conv_block(nc+3*gc, nc, 3, stride, bias=bias, pad_type=pad_type, \
# norm_type=norm_type, act_type=last_act, mode=mode)
def forward(self, x):
x1 = self.conv1(x)
x2 = self.conv2((torch.cat((x[0], x1[0]), dim=1),(torch.cat((x[1], x1[1]), dim=1))))
x3 = self.conv3((torch.cat((x[0], x1[0],x2[0]), dim=1),(torch.cat((x[1], x1[1],x2[1]), dim=1))))
x4 = self.conv4((torch.cat((x[0], x1[0],x2[0],x3[0]), dim=1),(torch.cat((x[1], x1[1],x2[1],x3[1]), dim=1))))
res = (x4[0].mul(0.2), x4[1].mul(0.2))
x = (x[0] + res[0], x[1] + res[1])
#print(len(x),"~~~",len(res),"~~~",len(x + res))
#return (x[0] + res[0], x[1]+res[1])
return x
####################################################################################################################
class octave_RRDBTiny(nn.Module):
'''
Residual in Residual Dense Block
(ESRGAN: Enhanced Super-Resolution Generative Adversarial Networks)
'''
def __init__(self, nc, kernel_size=3, gc=16, stride=1, alpha=0.5, bias=True, pad_type='zero', \
norm_type=None, act_type='leakyrelu', mode='CNA'):
super(octave_RRDBTiny, self).__init__()
self.RDB1 = octave_ResidualDenseBlockTiny_4C(nc=nc, kernel_size=kernel_size,alpha=alpha, gc=gc, stride=stride, bias=bias, pad_type=pad_type, \
norm_type=norm_type, act_type=act_type, mode=mode)
self.RDB2 = octave_ResidualDenseBlockTiny_4C(nc=nc, kernel_size=kernel_size,alpha=alpha, gc=gc, stride=stride, bias=bias, pad_type=pad_type, \
norm_type=norm_type, act_type=act_type, mode=mode)
def forward(self, x):
out = self.RDB1(x)
out = self.RDB2(out)
res = (out[0].mul(0.2), out[1].mul(0.2))
x = (x[0] + res[0], x[1] + res[1])
#print(len(x),"~~~",len(res),"~~~",len(x + res))
#return (x[0] + res[0], x[1]+res[1])
return x
class Octave_RRDBNet(nn.Module):
def __init__(self, in_nc, out_nc, nf, nb, gc=32,alpha=0.5, upscale=4, norm_type=None, \
act_type='leakyrelu', mode='CNA', upsample_mode='upconv'):
super(Octave_RRDBNet, self).__init__()
n_upscale = int(math.log(upscale, 2))
if upscale == 3:
n_upscale = 1
fea_conv1 = B.conv_block(in_nc, nf, kernel_size=3, norm_type=None, act_type=None)
fea_conv = B.FirstOctaveConv(nf, nf, kernel_size=3,alpha=alpha, stride=1, dilation=1, groups=1, \
bias=True, pad_type='zero', norm_type=None, act_type='prelu', mode='CNA')
rb_blocks = [B.octave_RRDBTiny(nf, kernel_size=3, gc=32,alpha=alpha,stride=1, bias=True, pad_type='zero', \
norm_type=norm_type, act_type=act_type, mode='CNA') for _ in range(nb)]
LR_conv = B.LastOctaveConv(nf, nf, kernel_size=3, alpha=alpha, stride=1, dilation=1, groups=1, \
bias=True, pad_type='zero', norm_type=None, act_type='prelu', mode='CNA')
if upsample_mode == 'upconv':
upsample_block = B.upconv_blcok
elif upsample_mode == 'pixelshuffle':
upsample_block = B.pixelshuffle_block
else:
raise NotImplementedError('upsample mode [{:s}] is not found'.format(upsample_mode))
if upscale == 3:
upsampler = upsample_block(nf, nf, 3, act_type=act_type)
else:
upsampler = [upsample_block(nf, nf, act_type=act_type) for _ in range(n_upscale)]
HR_conv0 = B.conv_block(nf, nf, kernel_size=3, norm_type=None, act_type=act_type)
HR_conv1 = B.conv_block(nf, out_nc, kernel_size=3, norm_type=None, act_type=None)
self.model = B.sequential(fea_conv1,B.ShortcutBlock(B.sequential(fea_conv,*rb_blocks, LR_conv)),\
*upsampler, HR_conv0, HR_conv1)
def forward(self, x):
x = self.model(x)
return x
##############################################################################################
setting
{
"name": "Octave_RRDBNet_Tiny_DIV2K_alpha=0.125" // please remove "debug_" during training
, "tb_logger_dir": "octave_carn"
, "use_tb_logger": true
, "model":"sr"
, "scale": 4
, "crop_scale": 0
, "gpu_ids": [6]
// , "init_type": "kaiming"
//
// , "finetune_type": "sft"
// , "init_norm_type": "zero"
, "datasets": {
"train": {
"name": "DIV2K800"
, "mode": "LRHR"
, "dataroot_HR": "/home/amax/wpguan/DIV2K800_sub/"
, "dataroot_LR": "/home/amax/wpguan/DIV2K800_sub_bicLRx4/"
, "subset_file": null
, "use_shuffle": true
, "n_workers": 8
, "batch_size": 16 // 16
, "HR_size": 128 // 128 | 192 | 96
, "noise_gt": true
, "use_flip": true
, "use_rot": true
}
, "val": {
"name": "set5"
, "mode": "LRHR"
, "dataroot_HR": "/home/gwp/SR_dataset/val_set5/MSet5/"
, "dataroot_LR": "/home/gwp/SR_dataset/val_set5/MSet5_bicLRx4/"
, "noise_gt": false
}
}
, "path": {
"root": "/home/gwp/SR_basic/octave_carn"
, "pretrain_model_G": null
}
//
, "network_G": {
"which_model_G": "Octave_RRDBNet" // RRDB_net | sr_resnet | modulate_denoise_resnet |noise_subnet octave_resnet, octave_carn
// , "norm_type": "adaptive_conv_res"
, "norm_type": null
, "mode": "CNA"
, "nf": 16//24//64
, "nb": 3//3//16
, "in_nc": 3
, "out_nc": 3
// , "gc": 32
, "group": 1
// , "gate_conv_bias": true
// , "ada_ksize": 1
// , "num_classes": 2
}
// , "network_G": {
// "which_model_G": "srcnn" // RRDB_net | sr_resnet
, "norm_type": null
// , "norm_type": "adaptive_conv_res"
// , "mode": "CNA"
// , "nf": 64
// , "in_nc": 1
// , "out_nc": 1
// , "ada_ksize": 5
// }
, "train": {
// "lr_G": 1e-3
"lr_G": 8e-4
, "lr_scheme": "MultiStepLR"
, "lr_steps": [210000, 350000, 500000]
// , "lr_steps": [500000]
, "lr_gamma": 0.5
, "pixel_criterion": "l2"
, "pixel_criterion_reg": "tv"
, "pixel_weight": 1.0
, "val_freq": 1e3
, "manual_seed": 0
, "niter": 6e5
}
, "logger": {
"print_freq": 200
, "save_checkpoint_freq": 1e3
}
}
实验python train.py -opt options/train/train_sr.json
先激活虚拟环境source activate pytorch
tensorboard --logdir tb_logger/ --port 6008
浏览器打开http://172.20.36.203:6008/#scalars
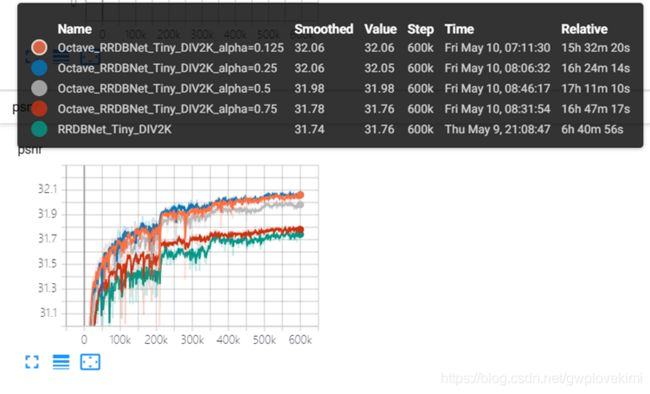
结果: