我们一起学ABAP(03)~内表、工作区(Work Area)和标题行(Header Lin)
1、内表
释义:和结构体一样,也是一个仅在程序运行时存在的对象(存储空间),程序运行时存在,程序结束后被消除(释放),可包含多条记录的数据表。
在ABAP/4中主要使用表格。表格是R/3系统中的关键数据结构,常用的数据都存储在关系型数据库的表格中。内表和结构体是两种使用较为频繁的数据类型,必需掌握!
1.1 内表的类型:
A、标准表(Standard) B、排序表(Sorted) C、哈希表(Hashed)
1.2、内表的创建: header line(表头行) work area( 工作区)
自定义创建内表关键字:DATA
首先自定义内表语法:依然关键字为TYPES,表示自定义类型,同结构体的自定义关键字。
TYPES<表名>TYPE<类型>OCCURS<初始大小>.
栗子:
TYPES VECTOR TYPE I OCCURS 10.
TYPES: BRGIN OF LINE, "这里 定义的是个类型
COLUMN1 TYPE I,
COLUMN2 TYPE I,
COLUMN3 TYPE I,
END OF LINE.
TYPES: ITAB TYPE LINE OCCURS 10. “定义内表,关键字组合使用 TYPES......OCCURS 少一个就不是定义的内表了,新手注意。1.3、内表创建的方式比较灵活,可以:a.参考结构体 b.参考其他内表 c.参考其他透明表 d.直接定义各个字段
UNIQUE|NON-UNIQUE :指定关键字,只适用于排序表和哈希表
INITIAL SIZE n :指定初始化内表大小
WITH HEADERLINE : 定义内表是否有表头
DATA <内表名> TYPE<结构类型> WITH [UNIQUE | NON-UNIQUE]
[INITIAL SIZE n] [WITH HEADER LINE]
DATA<内表名> LIKE TABLE OF <内表或透明表> WITH [UNIQUE | NON-UNIQUE]
[INITIAL SIZE n] [WITH HEADER LINE]
DATA: BEGIN OF itabOCCURS n,
......
......
END OF itab [VALID BTEWEEN f1 AND f2].
栗子:
TABLES:user1. "参照某一个透明表时,必需先引用定义。关键字 “TABLES”,类似于其他语言的导入。
TYPES: BEGIN OF emp,
name LIKE usr21-bname,
telnum LIKE usr21-persnumber,
addr LIKE usr21-addrnumber,
END OF emp.
" 参考该结构体,定义一个初始化大小为10,并有header line的内表
DATA: emptab TYPE STANDERARD TABLE OF emp INITIAL SIZE 10 WITHHEADER LINE.
"参考上例定义好的内表,重新定义大小为20,并没有HEADER LINE的内表
DATA: emptab2 LIKE STANDERARDTABLEOF emptab INITIAL SIZE 20.
"定义初始化为10,并有header line 的内表
DATA: emptab3 LIKE emptab OCCURS 10. "初始化关键字”OCCURS“
"定义一个排序表,以NAME为关键字,要求该表中的NAME字段数据不可重复
DATA: emptab4 LIKE SORTED TABLE OF emptab
WITH UNIQUEKEY NAME INITIAL SIZE 10
WITH HEADER LINE. ”在ABAP中同一行代码,语法允许拆分成N多行,但是为程序的可读性,不建议太多没必要的换行!没意义。
"定义一个初始化值为0的哈希表
DATA: emptab5 LIKE HASHED TABLE OF emptab
WITH UNIQUEKEY NAME WIEHHEADER LINE.
"用第三种方式定义内表,可以指定具体字段及初始化大小,默认内表有header line
TABLES: USR21.
DATA: BRGIN OF emp OCCURS 0,
NAME LIKE USR21-BNAME,
TELNUM LIKE USR21-PERSNUMBER,
ADDR LIKE USR21-ADDRNUMBER,
END OF emp.
2、ABAP/4 针对内表,可以做搜索、附加、插入、删除行的操作。
操作内表首先要明白的概念:
A、内表的行数并不是固定的,根据需求,系统可实时增加内表的大小。
B、内表时按 行 进行访问的,必须使用某个工作区域作为与表格相互传输数据的接口(可以理解为中转站)。
C、从内表中读取数据,也可以理解为用表格内容覆盖了工作区的内容。反之,将数据插入(写入)内表。 就必须先给工作区赋值(输入数据)。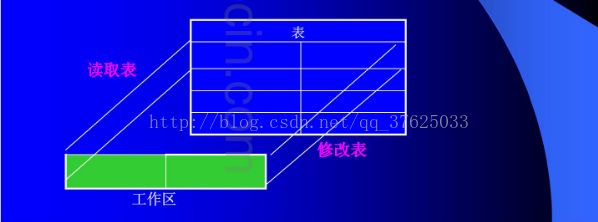
2.1、对于有header line 的内表,可以通过填充header line或者Work Area向内部追加数据。
栗子:
TABLES: USR21.
DATA: BEGIN OF emp OCCURS 0,
NAME LIKE USR21-BNAME,
TELNUM LIKE USR21-PERSNUMBER,
ADDR LIKE USR21-ADDRNUMBER,
END OF emp.
emp-name = 'JERY'.
emp-telnum = '010-12345678'.
emp-addr = 'BEIJIN'.
APPEND emp. "数据被赋给HEADER LINE 后再APPEND 到表的最后一行。
2.2、没有HEADER LINE 的内表赋值。只能通过外部的 WORK AREA来传递数据
TABLES: USR21.
DATA: BEGIN OF emptab OCCURS 0,
NAME LIKE USR21-BNAME,
TELNUM LIKE USR21-PERSNUMBER,
ADDR LIKE USR21-ADDRNUMBER,
END OF emptab.
DATA: emp LIKE STANDARD TABLE OF emptab.
emptab-name = 'JERY'.
emptab-telnum = '010-12345678'.
emptab-addr = 'BEIJIN'.
APPEND emptab TO emp. "数值被赋值给WORK AREA后再APPEND到内表中。
2.3、除了上面的两种方式外,在后面学到 ABAP的内部数据库(OPEN SQL)时,可以用查询语句来实现。
TABLES: USR21.
DATA: BEGIN OF emp OCCURS 0,
NAME LIKE USR21-BNAME,
TELNUM LIKE USR21-PERSNUMBER,
ADDR LIKE USR21-ADDRNUMBER,
END OF emp.
SELECT BNAME AS NAME " AS:可以理解为 ”的“字的意思。这句话的意思是:BNAME 的别名叫做 NAME(可以理解为人的大名和小名)PERSNUMBER AS TELNUM
ADDRNUMBER AS ADDR
INTO TABLE emp
FROM USR21. "通过OPEN SQL,讲从数据库中抓取的数据直接赋值给内表
3、填充内表时常用的语句,对比介绍:
要往内表中填充数据,可以逐行添加数据,也可以复制另一个表格的内容。
3.1、逐行填充内表各个语句的选择
a、如果仅是为了暂时存储数据,建议用 APPEND语句。用APPEND也可以创建序列清单(不了解这个用法)
b、如果需要计算数字字段之和或要确保内表中没有出现重复条目,使用 COLLECT语句,它可根据关键字排除重复
c、如果需要在内表现有行之前插入新数据行,则使用 INSERT 语句。
三种语句的语法:
a APPEND [<工作区> TO | INITIAL LINE TO] <内表>.
b COLLECT[ <工作区> INTO ] <内表>.
c INSERT [<工作区> INTO | INITIAL LINE INTO] <内表> [INDEX <行数>].
3.2、将内表复制给另一个内表时,语句选择:
a、需要将内表附加到另一个内表中时,使用APPEND语句。
b、需要将内表插入另一个内表中时,使用 INSERT最好。
c、需要将内表内容复制到另一个内表中,并覆盖它原有内容时,使用MOVE语句。
语法:
a APPEND LINES OF <源内表> [FROM <起始行>] [ TO <结束行>] TO <目的内表>.
b INSERT LINES OF <源内表> [FROM <起始行>] [TO <结束行>] INTO <目的内表> [INDEX<索引>].
c MOVE <源内http://write.blog.csdn.net/postedit/66967908?ticket=ST-1192223-4yG47PYa9O2lErE4v7Qs-passport.csdn.net表> TO <目的内表>.
<目的内表> = <源内表>.
4、读取内表
4.1、逐行读取内表:
语法:
LOOPAT <内表>[INTO <工作区>] [FROM
......
......
ENDLOOP.
4.2、用索引读取内表单行
语法:(优点快,和用关键字的形式读取内表比较)
READ TABLE <内表> [INTO <工作区>] INDEX <索引>.
4.2、用“关键字”读取单行
语法:
a、用标准关键字读取单行
READ TABLE
b、用自定义关键字读取单行
READ TABLE
C、读取部分单行
语法:(就是读取一部分单行,上面的都是读取全部单行)
READ TABLE
5、读取(查询)内表属性
语法:有时需要知道内表一共有多少行,初始化大小,就用describe语句。
DESCRIBE TABLE
6、内表排序
语法:
SORT
[BY
栗子:
SORT ITAB BY NAME.
7、更改内表
语法:
MODIFY
WRITE
8、内表初始化
语法:
a、清除内表数据
REFRESH
b、清除工作区
CLEAR
c、释放内表占用的内存
FREE
9、删除内表
语法:
a、删除选定行
DELETE
b、删除重复数据
DELETE ADJACENT DUPLICATE ENTRIES FROM
c、用索引删除内表
DELETE
d、用循环删除内表
DELETE
10、关于内表和工作区及标题行三者之间的区分对比,请参见小栈的另一篇文章。
如果,大家在读这篇博文的时候发现有错误的地方,请告知!会及时的更正。一起学ABAP!