Confluent完全分布式框架搭建
服务、端口说明
| kafka |
zookeeper |
control-center |
schema-registry |
kafka-reset |
connector |
ksql-server |
192.168.1.34 |
| kafka |
zookeeper |
control-center |
schema-registry |
kafka-reset |
connector |
ksql-server |
192.168.1.33 |
| kafka |
zookeeper |
control-center |
schema-registry |
kafka-reset |
connector |
ksql-server |
192.168.1.32 |
| 9092 |
2181 |
9021 |
8081 |
8082 |
8083 |
8088 |
端口 |
完全分布式搭建,每个机器上,都有confluent的多个服务。各端口也是按默认情况进行配置。
完全分布式搭建,建议至少有三个节点。
配置与安装
前置条件:JDK1.8
硬件条件,请查看官网,地址如下:
https://docs.confluent.io/current/installation/system-requirements.html
下载confluent并解压,如下是目录结构:
| Folder |
Description |
| /bin/ |
Driver scripts for starting and stopping services |
| /etc/ |
Configuration files |
| /lib/ |
Systemd services |
| /logs/ |
Log files |
| /share/ |
Jars and licenses |
| /src/ |
Source files that require a platform-dependent build |
修改配置
先配置zookeeper、再配kafka、再配connect、confluent-control等等
分布式zookeeper配置
1.vim/etc/ kafka/zookeeper.properties
##zookeeper数据存放目录,默认为/tmp/zookeeper。/tmp目录存在删除风险
dataDir=/yan/zookeeper
clientPort=2181
maxClientCnxns=0
initLimit=5
syncLimit=2
##多个zookeeper server,server的编号1、2、3等要与myid中的一致
server.1=192.168.1.32:2888:3888
server.2=192.168.1.33:2888:3888
server.3=192.168.1.34:2888:3888
2.生成myid
cd etc/kafka
192.168.1.32机器
echo “1” > myid
192.168.1.33机器
echo “2” > myid
192.168.1.34机器
echo “3” > myid
3.修改confluent服务启动脚本,将myid发布到confluent运行目录下。
bin/confluent start会启动confluent的各服务,且会将etc下的各配置,复制到confluent运行目录下。
vim bin/confluent
在config_zookeeper()方法块最后一行,添加
cp ${confluent_conf}/kafka/myid $confluent_current/zookeeper/data/
目的是将etc/kafka/myid拷贝到confluent运行目录下,否则会报myid is no found,zookeeper启动失败。
Kafka配置
vim etc/kafka/server.properties
broker.id.generation.enable=true
## listeners与advertised.listeners可以只配一个,与当前机器网卡有关系,请注意。advertised.listeners可能通用性更强,值为当前机器的ip与端口,其他机器ip无需配置
listeners=PLAINTEXT://192.168.1.32:9092
advertised.listeners=PLAINTEXT://192.168.1.32:9092
##根据实际情况调整
num.network.threads=30
num.io.threads=30
## log.dirs是最重要的配置,kafka数据所在
log.dirs=/insight/hdfs1/yan/kafka-logs
num.partitions=5
##备份因子数<=kafka节点数,若大于会报错
default.replication.factor=2
offsets.topic.replication.factor=3
transaction.state.log.replication.factor=3
transaction.state.log.min.isr=2
##log失效时间,单位小时
log.retention.hours=72
zookeeper.connect=192.168.1.32:2181,192.168.1.33:2181,192.168.1.34:2181
metric.reporters=io.confluent.metrics.reporter.ConfluentMetricsReporter
confluent.metrics.reporter.bootstrap.servers=192.168.1.32:9092,192.168.1.33:9092,192.168.1.34:9092
confluent.metrics.reporter.topic.replicas=2
confluent.support.metrics.enable=true
confluent.support.customer.id=anonymous
delete.topic.enable=true
group.initial.rebalance.delay.ms=0
kafka-rest
vim etc/kafka-rest/kafka-rest.properties
schema.registry.url=http://192.168.1.32:8081,http://192.168.1.33:8081,http://192.168.1.34:8081
zookeeper.connect=192.168.1.32:2181,192.168.1.33:2181,192.168.1.34:2181
listeners=http://0.0.0.0:8082
bootstrap.servers=PLAINTEXT://192.168.1.32:9092,192.168.1.33:9092,192.168.1.34:9092
consumer.interceptor.classes=io.confluent.monitoring.clients.interceptor.MonitoringConsumerInterceptor
producer.interceptor.classes=io.confluent.monitoring.clients.interceptor.MonitoringProducerInterceptor
ksql
vim etc/ksql/ksql-server.properties
ksql.service.id=default_
bootstrap.servers=192.168.1.32:9092,192.168.1.33:9092,192.168.1.34:9092
listeners=http://0.0.0.0:8088
ksql.schema.registry.url=http://192.168.1.32:8081,http://172.168.1.33:8081,http://192.168.1.34:8081
ksql.extension.dir=/opt/renzixingtest/confluent-5.1.2/etc/ksql/ext/rzx-ksql-udf.jar
ksql.sink.partitions=4
confluent-control-center
vim etc/confluent-control-center/control-center-dev.properties
bootstrap.servers=192.168.1.32:9092,192.168.1.33:9092,192.168.1.34:9092
zookeeper.connect=192.168.1.32:2181,192.168.1.33:2181,192.168.1.34:2181
confluent.controlcenter.rest.listeners=http://0.0.0.0:9021
#每个 id 要唯一,不然只能启动一个
confluent.controlcenter.id=1
confluent.controlcenter.data.dir=/insight/hdfs1/yan/control-center
confluent.controlcenter.connect.cluster=http://192.168.1.32:8083,http://192.168.1.33:8083,http://192.168.1.34:8083
##每台都配置各自的 ip,配置同一个也应该可以
confluent.controlcenter.ksql.url=http://172.172.4.32:8088
confluent.controlcenter.schema.registry.url=http://192.168.1.32:8081,http://192.168.1.33:8081,http://192.168.1.34:8081
confluent.controlcenter.internal.topics.replication=2
confluent.controlcenter.internal.topics.partitions=3
confluent.controlcenter.command.topic.replication=2
confluent.monitoring.interceptor.topic.partitions=3
confluent.monitoring.interceptor.topic.replication=2
confluent.metrics.topic.replication=3
confluent.controlcenter.streams.num.stream.threads=30
schema-registry
vim etc/schema-registry/schema-registry.properties
listeners=http://0.0.0.0:8081
kafkastore.bootstrap.servers=PLAINTEXT://192.168.1.32:9092,192.168.1.33:9092,192.168.1.34:9092
kafkastore.topic=_schemas
debug=false
connect
vim etc/schema-registry/connect-avro-distributed.properties
bootstrap.servers=192.168.1.32:9092,192.168.1.33:9092,192.168.1.34:9092
group.id=connect-cluster
key.converter=io.confluent.connect.avro.AvroConverter
value.converter=io.confluent.connect.avro.AvroConverter
key.converter.schema.registry.url=http://192.168.1.32:8081,http://192.168.1.33:8081,http://192.168.1.34:8081
value.converter.schema.registry.url=http://192.168.1.32:8081,http://192.168.1.33:8081,http://192.168.1.34:8081
key.converter.schemas.enable=false
value.converter.schemas.enable=true
config.storage.topic=connect-configs
offset.storage.topic=connect-offsets
status.storage.topic=connect-statuses
config.storage.replication.factor=3
offset.storage.replication.factor=3
status.storage.replication.factor=3
internal.key.converter=org.apache.kafka.connect.json.JsonConverter
internal.value.converter=org.apache.kafka.connect.json.JsonConverter
internal.key.converter.schemas.enable=false
internal.value.converter.schemas.enable=false
rest.port=8083
rest.advertised.port=8083
plugin.path=/opt/renzixingtest/confluent-5.1.2/share/java
服务启动与停止
##启动
bin/confluent start
##查看状态
bin/confluent status
##停止
bin/confluent stop
服务单独启动
bin/zookeeper-server-start etc/kafka/zookeeper.properties
bin/kafka-server-start etc/kafka/server.properties
启动connect-distributed
nohup ./bin/connect-distributed ./etc/schema-registry/connect-avro-distributed.properties > /tmp/kafka-cluster-connect.log &
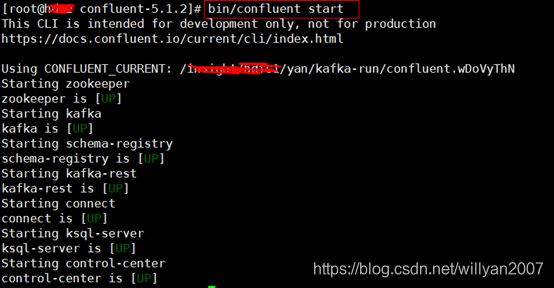
如上图,confluent服务运行目录在yan/kafka-run/confluent.wDoVyThN,它下有各服务的子目录,若要查看日志,以kafka为例,请查看kafka/ kafka.stdout。
特别注意:
若有服务启动失败,例如:control-center、connect、schema-registry,kafka启动成功,但请优先检查kafka,查看kafka日志,也许会有异常报出,kafka的进程虽然起来了,但kafka不一定能正常使用。具体情况请仔细分析kafka,予以排查保证kafka正常。重启confluent,也许control-center、connect、schema-registry的启动失败,就能迎刃而解。

如上图,各服务均正常。
Confluent测试
创建stream和table
confluent自带了一个ksql-datagen工具,可以创建和产生相关的topic和数据。
创建pageviews
数据格式为delimited
cd confluent/bin
./ksql-datagen quickstart=pageviews format=delimited topic=pageviews maxInterval=500
以上命令会源源不断输出数据,就是工具自己产生的数据,如下样例
8001 --> ([ 1539063767860 | 'User_6' | 'Page_77' ]) ts:1539063767860
8011 --> ([ 1539063767981 | 'User_9' | 'Page_75' ]) ts:1539063767981
8021 --> ([ 1539063768086 | 'User_5' | 'Page_16' ]) ts:1539063768086
消费出来看看
bin/kafka-console-consumer --bootstrap-server 192.168.1.32:9092,192.168.1.33:9092,192.168.1.34:9092 --topic pageviews --from-beginning --max-messages 10
1539066430530,User_5,Page_29
1539066430915,User_6,Page_74
1539066431192,User_4,Page_28
创建users
数据格式为json
cd confluent/bin
./ksql-datagen quickstart=users format=json topic=users maxInterval=100
如下样例
User_5 --> ([ 1517896551436 | 'User_5' | 'Region_5' | 'MALE' ]) ts:1539063787413
User_7 --> ([ 1513998830510 | 'User_7' | 'Region_4' | 'MALE' ]) ts:1539063787430
User_6 --> ([ 1514865642822 | 'User_6' | 'Region_2' | 'MALE' ]) ts:1539063787481
消费出来
bin/kafka-console-consumer --bootstrap-server 192.168.1.32:9092,192.168.1.33:9092,192.168.1.34:9092 --topic users --from-beginning --max-messages 10
{"registertime":1507118206666,"userid":"User_6","regionid":"Region_7","gender":"OTHER"}
{"registertime":1506192314325,"userid":"User_1","regionid":"Region_1","gender":"MALE"}
{"registertime":1489277749526,"userid":"User_6","regionid":"Region_4","gender":"FEMALE"}
启动ksql
bin/ksql-server-start -daemon etc/ksql/ksql-server.properties
连接ksql
bin/ksql http://10.205.151.145:8088
或者直接
bin/ksql
创建stream和table
stream
根据topic pageviews创建一个stream pageviews_original,value_format为DELIMITED
ksql>CREATE STREAM pageviews_original (viewtime bigint, userid varchar, pageid varchar) WITH \
(kafka_topic='pageviews', value_format='DELIMITED');
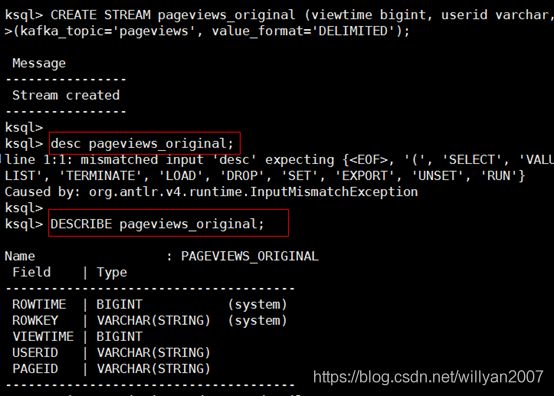
table
根据topic users创建一个table users_original,value_format为json
ksql>CREATE TABLE users_original (registertime BIGINT, gender VARCHAR, regionid VARCHAR, userid VARCHAR) WITH \
(kafka_topic='users', value_format='JSON', key = 'userid');
查询数据
ksql> SELECT * FROM USERS_ORIGINAL LIMIT 3;
ksql> SELECT * FROM pageviews_original LIMIT 3;
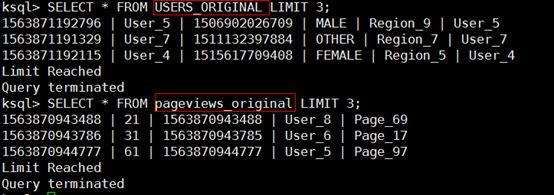
ps:ksql默认是从kafka最新的数据查询消费的,如果你想从开头查询,则需要在会话上进行设置:SET 'auto.offset.reset' = 'earliest';
持久化查询
持久化查询可以源源不断的把查询出的数据发送到你指定的topic中去,查询的时候在select前面添加create stream关键字即可创建持久化查询。
创建查询
ksql> CREATE STREAM pageviews2 AS SELECT userid FROM pageviews_original;
查询新stream
ksql> SHOW STREAMS;
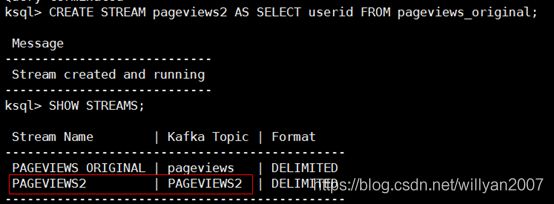
ps:可以看到新创建了stream PAGEVIEWS2,并且创建了topic PAGEVIEWS2。
查询执行任务
ksql> SHOW QUERIES;

ps:可以看到ID为CSAS_PAGEVIEWS2_0的任务在执行,并且有显示执行的语句。
消费新数据
./kafka-console-consumer --bootstrap-server 192.168.1.32:9092,192.168.1.33:9092,192.168.1.34:9092 --from-beginning --topic PAGEVIEWS2

数据写入到kafka中。
终止查询任务
ksql> TERMINATE CSAS_PAGEVIEWS2_0;
ksql> SHOW QUERIES;
ps:terminate之后,show就不再有数据。

暂时完成。