Spark:Spark SQL、Spark Streaming
 日萌社
日萌社
人工智能AI:Keras PyTorch MXNet TensorFlow PaddlePaddle 深度学习实战(不定时更新)
spark 入门
课程目标:
- 了解spark概念
- 知道spark的特点(与hadoop对比)
- 独立实现spark local模式的启动
1.1 spark概述
-
1、什么是spark
- 基于内存的计算引擎,它的计算速度非常快。但是仅仅只涉及到数据的计算,并没有涉及到数据的存储。
-
2、为什么要学习spark
MapReduce框架局限性
- 1,Map结果写磁盘,Reduce写HDFS,多个MR之间通过HDFS交换数据
- 2,任务调度和启动开销大
- 3,无法充分利用内存
- 4,不适合迭代计算(如机器学习、图计算等等),交互式处理(数据挖掘)
- 5,不适合流式处理(点击日志分析)
- 6,MapReduce编程不够灵活,仅支持Map和Reduce两种操作
Hadoop生态圈
- 批处理:MapReduce、Hive、Pig
- 流式计算:Storm
- 交互式计算:Impala、presto
需要一种灵活的框架可同时进行批处理、流式计算、交互式计算
- 内存计算引擎,提供cache机制来支持需要反复迭代计算或者多次数据共享,减少数据读取的IO开销
- DAG引擎,较少多次计算之间中间结果写到HDFS的开销
- 使用多线程模型来减少task启动开销,shuffle过程中避免不必要的sort操作以及减少磁盘IO
spark的缺点是:吃内存,不太稳定
-
3、spark特点
- 1、速度快(比mapreduce在内存中快100倍,在磁盘中快10倍)
- spark中的job中间结果可以不落地,可以存放在内存中。
- mapreduce中map和reduce任务都是以进程的方式运行着,而spark中的job是以线程方式运行在进程中。
- 2、易用性(可以通过java/scala/python/R开发spark应用程序)
- 3、通用性(可以使用spark sql/spark streaming/mlib/Graphx)
- 4、兼容性(spark程序可以运行在standalone/yarn/mesos)
- 1、速度快(比mapreduce在内存中快100倍,在磁盘中快10倍)
1.2 spark启动(local模式)和WordCount(演示)
-
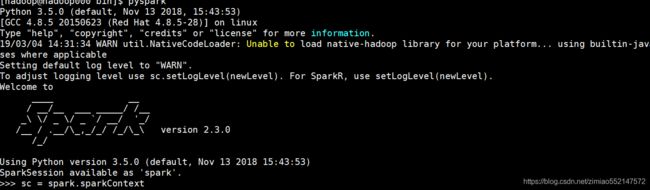
启动pyspark
-
在$SPARK_HOME/sbin目录下执行
- ./pyspark
-
-
sc = spark.sparkContext words = sc.textFile('file:///home/hadoop/tmp/word.txt') \ .flatMap(lambda line: line.split(" ")) \ .map(lambda x: (x, 1)) \ .reduceByKey(lambda a, b: a + b).collect() -
输出结果:
[('python', 2), ('hadoop', 1), ('bc', 1), ('foo', 4), ('test', 2), ('bar', 2), ('quux', 2), ('abc', 2), ('ab', 1), ('you', 1), ('ac', 1), ('bec', 1), ('by', 1), ('see', 1), ('labs', 2), ('me', 1), ('welcome', 1)]
RDD概述
课程目标:
- 知道RDD的概念
- 独立实现RDD的创建
2.1 什么是RDD
- RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变、可分区、里面的元素可并行计算的集合.
- Dataset:一个数据集,简单的理解为集合,用于存放数据的
- Distributed:它的数据是分布式存储,并且可以做分布式的计算
- Resilient:弹性的
- 它表示的是数据可以保存在磁盘,也可以保存在内存中
- 数据分布式也是弹性的
- 弹性:并不是指他可以动态扩展,而是容错机制。
- RDD会在多个节点上存储,就和hdfs的分布式道理是一样的。hdfs文件被切分为多个block存储在各个节点上,而RDD是被切分为多个partition。不同的partition可能在不同的节点上
- spark读取hdfs的场景下,spark把hdfs的block读到内存就会抽象为spark的partition。
- spark计算结束,一般会把数据做持久化到hive,hbase,hdfs等等。我们就拿hdfs举例,将RDD持久化到hdfs上,RDD的每个partition就会存成一个文件,如果文件小于128M,就可以理解为一个partition对应hdfs的一个block。反之,如果大于128M,就会被且分为多个block,这样,一个partition就会对应多个block。
- 不可变 Rdd1->rdd2
- 可分区 partition
- 并行计算
2.2 RDD的创建
-
第一步 创建sparkContext
- SparkContext, Spark程序的入口. SparkContext代表了和Spark集群的链接, 在Spark集群中通过SparkContext来创建RDD
- SparkConf 创建SparkContext的时候需要一个SparkConf, 用来传递Spark应用的基本信息
conf = SparkConf().setAppName(appName).setMaster(master) sc = SparkContext(conf=conf) -
创建RDD
- 进入pyspark环境
[hadoop@hadoop000 ~]$ pyspark Python 3.5.0 (default, Nov 13 2018, 15:43:53) [GCC 4.8.5 20150623 (Red Hat 4.8.5-28)] on linux Type "help", "copyright", "credits" or "license" for more information. 19/03/08 12:19:55 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /__ / .__/\_,_/_/ /_/\_\ version 2.3.0 /_/ Using Python version 3.5.0 (default, Nov 13 2018 15:43:53) SparkSession available as 'spark'. >>> sc- 在spark shell中 已经为我们创建好了 SparkContext 通过sc直接使用
- 可以在spark UI中看到当前的Spark作业 在浏览器访问当前centos的4040端口 192.168.19.137:4040
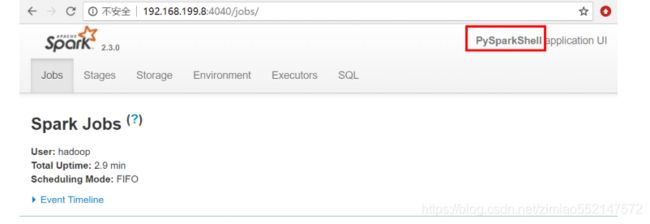
Parallelized Collections方式创建RDD
- 调用
SparkContext的parallelize方法并且传入已有的可迭代对象或者集合
data = [1, 2, 3, 4, 5]
distData = sc.parallelize(data)
>>> data = [1, 2, 3, 4, 5]
>>> distData = sc.parallelize(data)
>>> data
[1, 2, 3, 4, 5]
>>> distData
ParallelCollectionRDD[0] at parallelize at PythonRDD.scala:175
- 在spark ui中观察执行情况
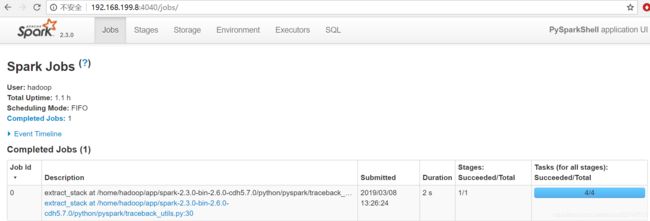
- 在通过
parallelize方法创建RDD 的时候可以指定分区数量
>>> distData = sc.parallelize(data,5)
>>> distData.reduce(lambda a, b: a + b)
15
- 在spark ui中观察执行情况
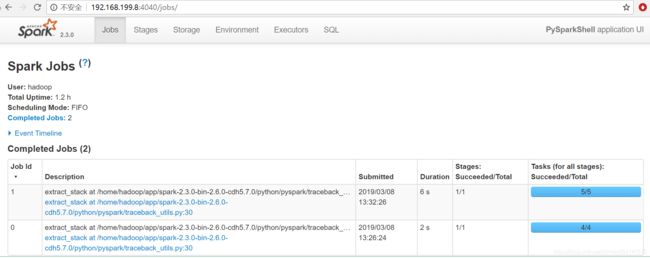
- Spark将为群集的每个分区(partition)运行一个任务(task)。 通常,可以根据CPU核心数量指定分区数量(每个CPU有2-4个分区)如未指定分区数量,Spark会自动设置分区数。
-
通过外部数据创建RDD
- PySpark可以从Hadoop支持的任何存储源创建RDD,包括本地文件系统,HDFS,Cassandra,HBase,Amazon S3等
- 支持整个目录、多文件、通配符
- 支持压缩文件
>>> rdd1 = sc.textFile('file:///root/tmp/word.txt') >>> rdd1.collect() ['foo foo quux labs foo bar quux abc bar see you by test welcome test', 'abc labs foo me python hadoop ab ac bc bec python']
spark-core RDD常用算子练习
课程目标
- 说出RDD的三类算子
- 掌握transformation和action算子的基本使用
3.1 RDD 常用操作
-
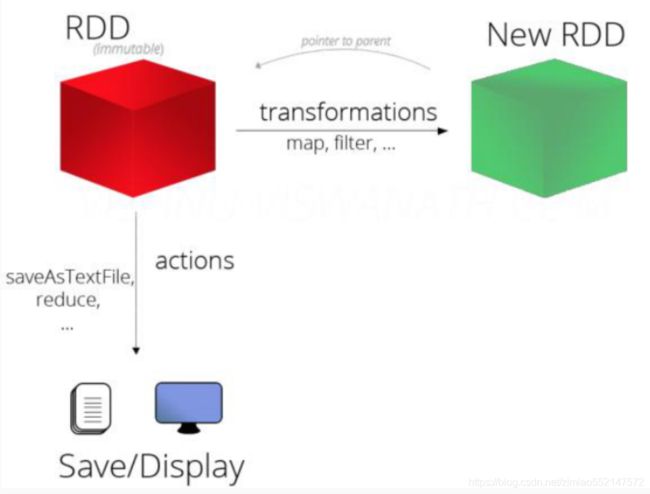
RDD 支持两种类型的操作:
- transformation
- 从一个已经存在的数据集创建一个新的数据集
- rdd a ----->transformation ----> rdd b
- 比如, map就是一个transformation 操作,把数据集中的每一个元素传给一个函数并返回一个新的RDD,代表transformation操作的结果
- 从一个已经存在的数据集创建一个新的数据集
- action
- 获取对数据进行运算操作之后的结果
- 比如, reduce 就是一个action操作,使用某个函数聚合RDD所有元素的操作,并返回最终计算结果
- transformation
-
所有的transformation操作都是惰性的(lazy)
- 不会立即计算结果
- 只记下应用于数据集的transformation操作
- 只有调用action一类的操作之后才会计算所有transformation
- 这种设计使Spark运行效率更高
- 例如map reduce 操作,map创建的数据集将用于reduce,map阶段的结果不会返回,仅会返回reduce结果。
- persist 操作
- persist操作用于将数据缓存 可以缓存在内存中 也可以缓存到磁盘上, 也可以复制到磁盘的其它节点上
3.2 RDD Transformation算子
-
map: map(func)
- 将func函数作用到数据集的每一个元素上,生成一个新的RDD返回
>>> rdd1 = sc.parallelize([1,2,3,4,5,6,7,8,9],3) >>> rdd2 = rdd1.map(lambda x: x+1) >>> rdd2.collect() [2, 3, 4, 5, 6, 7, 8, 9, 10]>>> rdd1 = sc.parallelize([1,2,3,4,5,6,7,8,9],3) >>> def add(x): ... return x+1 ... >>> rdd2 = rdd1.map(add) >>> rdd2.collect() [2, 3, 4, 5, 6, 7, 8, 9, 10]
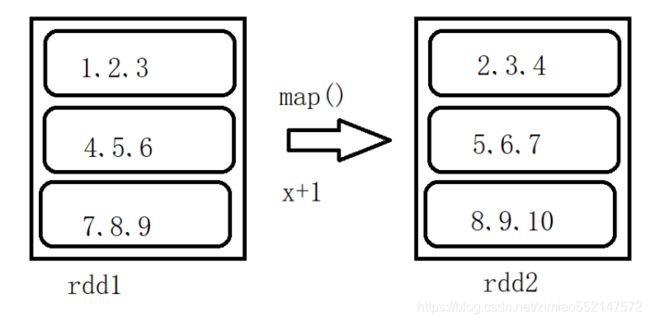
-
filter
- filter(func) 选出所有func返回值为true的元素,生成一个新的RDD返回
>>> rdd1 = sc.parallelize([1,2,3,4,5,6,7,8,9],3) >>> rdd2 = rdd1.map(lambda x:x*2) >>> rdd3 = rdd2.filter(lambda x:x>4) >>> rdd3.collect() [6, 8, 10, 12, 14, 16, 18] -
flatmap
- flatMap会先执行map的操作,再将所有对象合并为一个对象
>>> rdd1 = sc.parallelize(["a b c","d e f","h i j"]) >>> rdd2 = rdd1.flatMap(lambda x:x.split(" ")) >>> rdd2.collect() ['a', 'b', 'c', 'd', 'e', 'f', 'h', 'i', 'j']- flatMap和map的区别:flatMap在map的基础上将结果合并到一个list中
>>> rdd1 = sc.parallelize(["a b c","d e f","h i j"]) >>> rdd2 = rdd1.map(lambda x:x.split(" ")) >>> rdd2.collect() [['a', 'b', 'c'], ['d', 'e', 'f'], ['h', 'i', 'j']] -
union
- 对两个RDD求并集
>>> rdd1 = sc.parallelize([("a",1),("b",2)]) >>> rdd2 = sc.parallelize([("c",1),("b",3)]) >>> rdd3 = rdd1.union(rdd2) >>> rdd3.collect() [('a', 1), ('b', 2), ('c', 1), ('b', 3)] -
intersection
- 对两个RDD求交集
>>> rdd1 = sc.parallelize([("a",1),("b",2)]) >>> rdd2 = sc.parallelize([("c",1),("b",3)]) >>> rdd3 = rdd1.union(rdd2) >>> rdd4 = rdd3.intersection(rdd2) >>> rdd4.collect() [('c', 1), ('b', 3)] -
groupByKey
- 以元组中的第0个元素作为key,进行分组,返回一个新的RDD
>>> rdd1 = sc.parallelize([("a",1),("b",2)]) >>> rdd2 = sc.parallelize([("c",1),("b",3)]) >>> rdd3 = rdd1.union(rdd2) >>> rdd4 = rdd3.groupByKey() >>> rdd4.collect() [('a',), ('c', ), ('b', )] - groupByKey之后的结果中 value是一个Iterable
>>> result[2] ('b',) >>> result[2][1] >>> list(result[2][1]) [2, 3] -
reduceByKey
- 将key相同的键值对,按照Function进行计算
>>> rdd = sc.parallelize([("a", 1), ("b", 1), ("a", 1)]) >>> rdd.reduceByKey(lambda x,y:x+y).collect() [('b', 1), ('a', 2)] -
sortByKey
-
sortByKey(ascending=True, numPartitions=None, keyfunc=>)Sorts this RDD, which is assumed to consist of (key, value) pairs.
>>> tmp = [('a', 1), ('b', 2), ('1', 3), ('d', 4), ('2', 5)] >>> sc.parallelize(tmp).sortByKey().first() ('1', 3) >>> sc.parallelize(tmp).sortByKey(True, 1).collect() [('1', 3), ('2', 5), ('a', 1), ('b', 2), ('d', 4)] >>> sc.parallelize(tmp).sortByKey(True, 2).collect() [('1', 3), ('2', 5), ('a', 1), ('b', 2), ('d', 4)] >>> tmp2 = [('Mary', 1), ('had', 2), ('a', 3), ('little', 4), ('lamb', 5)] >>> tmp2.extend([('whose', 6), ('fleece', 7), ('was', 8), ('white', 9)]) >>> sc.parallelize(tmp2).sortByKey(True, 3, keyfunc=lambda k: k.lower()).collect() [('a', 3), ('fleece', 7), ('had', 2), ('lamb', 5),...('white', 9), ('whose', 6)] -
3.3 RDD Action算子
-
collect
- 返回一个list,list中包含 RDD中的所有元素
- 只有当数据量较小的时候使用Collect 因为所有的结果都会加载到内存中
-
reduce
- reduce将RDD中元素两两传递给输入函数,同时产生一个新的值,新产生的值与RDD中下一个元素再被传递给输入函数直到最后只有一个值为止。
>>> rdd1 = sc.parallelize([1,2,3,4,5]) >>> rdd1.reduce(lambda x,y : x+y) 15 -
first
- 返回RDD的第一个元素
>>> sc.parallelize([2, 3, 4]).first() 2 -
take
- 返回RDD的前N个元素
take(num)
>>> sc.parallelize([2, 3, 4, 5, 6]).take(2) [2, 3] >>> sc.parallelize([2, 3, 4, 5, 6]).take(10) [2, 3, 4, 5, 6] >>> sc.parallelize(range(100), 100).filter(lambda x: x > 90).take(3) [91, 92, 93] -
count
返回RDD中元素的个数
>>> sc.parallelize([2, 3, 4]).count() 3
3.4 Spark RDD两类算子执行示意
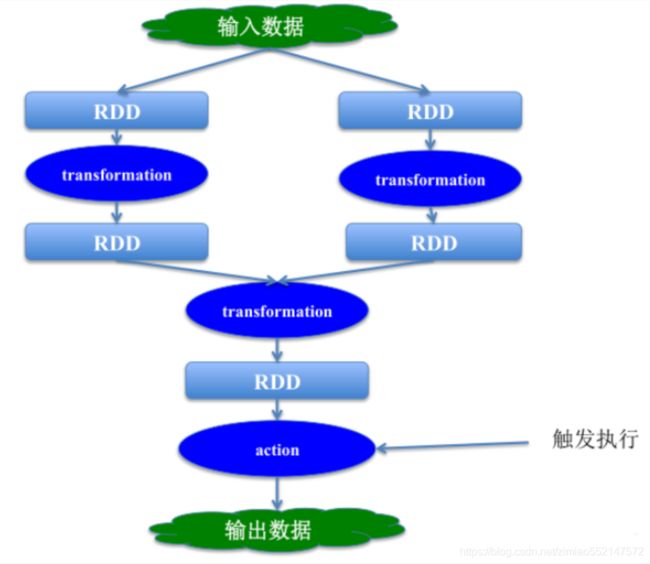
spark-core 实战案例
课程目标:
- 独立实现Spark RDD的word count案例
- 独立实现spark RDD的PV UV统计案例
4.1利用PyCharm编写spark wordcount程序
-
环境配置
将spark目录下的python目录下的pyspark整体拷贝到pycharm使用的python环境下
将下图中的pyspark

-
拷贝到pycharm使用的:xxx\Python\Python36\Lib\site-packages目录下
-
代码
import sys
from pyspark.sql import SparkSession
if __name__ == '__main__':
if len(sys.argv) != 2:
print("Usage: avg ", file=sys.stderr)
sys.exit(-1)
spark = SparkSession.builder.appName("test").getOrCreate()
sc = spark.sparkContext
counts = sc.textFile(sys.argv[1]) \
.flatMap(lambda line: line.split(" ")) \
.map(lambda x: (x, 1)) \
.reduceByKey(lambda a, b: a + b)
output = counts.collect()
for (word, count) in output:
print("%s: %i" % (word, count))
sc.stop()
-
将代码上传到远程cent-os系统上
-
在系统上执行指令
spark-submit --master local wc.py file:///root/bigdata/data/spark_test.log
4.2 通过spark实现点击流日志分析
在新闻类网站中,经常要衡量一条网络新闻的页面访问量,最常见的就是uv和pv,如果在所有新闻中找到访问最多的前几条新闻,topN是最常见的指标。
- 数据示例
#每条数据代表一次访问记录 包含了ip 访问时间 访问的请求方式 访问的地址...信息
194.237.142.21 - - [18/Sep/2013:06:49:18 +0000] "GET /wp-content/uploads/2013/07/rstudio-git3.png HTTP/1.1" 304 0 "-" "Mozilla/4.0 (compatible;)"
183.49.46.228 - - [18/Sep/2013:06:49:23 +0000] "-" 400 0 "-" "-"
163.177.71.12 - - [18/Sep/2013:06:49:33 +0000] "HEAD / HTTP/1.1" 200 20 "-" "DNSPod-Monitor/1.0"
163.177.71.12 - - [18/Sep/2013:06:49:36 +0000] "HEAD / HTTP/1.1" 200 20 "-" "DNSPod-Monitor/1.0"
101.226.68.137 - - [18/Sep/2013:06:49:42 +0000] "HEAD / HTTP/1.1" 200 20 "-" "DNSPod-Monitor/1.0"
101.226.68.137 - - [18/Sep/2013:06:49:45 +0000] "HEAD / HTTP/1.1" 200 20 "-" "DNSPod-Monitor/1.0"
60.208.6.156 - - [18/Sep/2013:06:49:48 +0000] "GET /wp-content/uploads/2013/07/rcassandra.png HTTP/1.0" 200 185524 "http://cos.name/category/software/packages/" "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/29.0.1547.66 Safari/537.36"
222.68.172.190 - - [18/Sep/2013:06:49:57 +0000] "GET /images/my.jpg HTTP/1.1" 200 19939 "http://www.angularjs.cn/A00n" "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/29.0.1547.66 Safari/537.36"
222.68.172.190 - - [18/Sep/2013:06:50:08 +0000] "-" 400 0 "-" "-"
-
访问的pv
pv:网站的总访问量
from pyspark.sql import SparkSession spark = SparkSession.builder.appName("pv").getOrCreate() sc = spark.sparkContext rdd1 = sc.textFile("file:///root/bigdata/data/access.log") #把每一行数据记为("pv",1) rdd2 = rdd1.map(lambda x:("pv",1)).reduceByKey(lambda a,b:a+b) rdd2.collect() sc.stop() -
访问的uv
uv:网站的独立用户访问量
from pyspark.sql import SparkSession spark = SparkSession.builder.appName("pv").getOrCreate() sc = spark.sparkContext rdd1 = sc.textFile("file:///root/bigdata/data/access.log") #对每一行按照空格拆分,将ip地址取出 rdd2 = rdd1.map(lambda x:x.split(" ")).map(lambda x:x[0]) #把每个ur记为1 rdd3 = rdd2.distinct().map(lambda x:("uv",1)) rdd4 = rdd3.reduceByKey(lambda a,b:a+b) rdd4.saveAsTextFile("hdfs:///uv/result") sc.stop() -
访问的topN
from pyspark.sql import SparkSession spark = SparkSession.builder.appName("topN").getOrCreate() sc = spark.sparkContext rdd1 = sc.textFile("file:///root/bigdata/data/access.log") #对每一行按照空格拆分,将url数据取出,把每个url记为1 rdd2 = rdd1.map(lambda x:x.split(" ")).filter(lambda x:len(x)>10).map(lambda x:(x[10],1)) #对数据进行累加,按照url出现次数的降序排列 rdd3 = rdd2.reduceByKey(lambda a,b:a+b).sortBy(lambda x:x[1],ascending=False) #取出序列数据中的前n个 rdd4 = rdd3.take(5) rdd4.collect() sc.stop()
spark-core实战
课程目标
- 独立实现ip地址查询
- 说出广播变量的概念
5.1通过spark实现ip地址查询
需求
在互联网中,我们经常会见到城市热点图这样的报表数据,例如在百度统计中,会统计今年的热门旅游城市、热门报考学校等,会将这样的信息显示在热点图中。
因此,我们需要通过日志信息(运行商或者网站自己生成)和城市ip段信息来判断用户的ip段,统计热点经纬度。
ip日志信息
在ip日志信息中,我们只需要关心ip这一个维度就可以了,其他的不做介绍
思路
1、 加载城市ip段信息,获取ip起始数字和结束数字,经度,纬度
2、 加载日志数据,获取ip信息,然后转换为数字,和ip段比较
3、 比较的时候采用二分法查找,找到对应的经度和纬度
4,对相同的经度和纬度做累计求和
-
代码
from pyspark.sql import SparkSession # 255.255.255.255 0~255 256 2^8 8位2进制数 32位2进制数 #将ip转换为特殊的数字形式 223.243.0.0|223.243.191.255| 255 2^8 #11011111 #00000000 #1101111100000000 # 11110011 #11011111111100110000000000000000 def ip_transform(ip): ips = ip.split(".")#[223,243,0,0] 32位二进制数 ip_num = 0 for i in ips: ip_num = int(i) | ip_num << 8 return ip_num #二分法查找ip对应的行的索引 def binary_search(ip_num, broadcast_value): start = 0 end = len(broadcast_value) - 1 while (start <= end): mid = int((start + end) / 2) if ip_num >= int(broadcast_value[mid][0]) and ip_num <= int(broadcast_value[mid][1]): return mid if ip_num < int(broadcast_value[mid][0]): end = mid if ip_num > int(broadcast_value[mid][1]): start = mid def main(): spark = SparkSession.builder.appName("test").getOrCreate() sc = spark.sparkContext city_id_rdd = sc.textFile("file:///root/tmp/ip.txt").map(lambda x:x.split("|")).map(lambda x: (x[2], x[3], x[13], x[14])) #创建一个广播变量 city_broadcast = sc.broadcast(city_id_rdd.collect()) dest_data = sc.textFile("file:///root/tmp/20090121000132.394251.http.format").map( lambda x: x.split("|")[1]) #根据取出对应的位置信息 def get_pos(x): city_broadcast_value = city_broadcast.value #根据单个ip获取对应经纬度信息 def get_result(ip): ip_num = ip_transform(ip) index = binary_search(ip_num, city_broadcast_value) #((纬度,精度),1) return ((city_broadcast_value[index][2], city_broadcast_value[index][3]), 1) x = map(tuple,[get_result(ip) for ip in x]) return x dest_rdd = dest_data.mapPartitions(lambda x: get_pos(x)) #((纬度,精度),1) result_rdd = dest_rdd.reduceByKey(lambda a, b: a + b) print(result_rdd.collect()) sc.stop() if __name__ == '__main__': main() -
广播变量的使用
- 要统计Ip所对应的经纬度, 每一条数据都会去查询ip表
- 每一个task 都需要这一个ip表, 默认情况下, 所有task都会去复制ip表
- 实际上 每一个Worker上会有多个task, 数据也是只需要进行查询操作的, 所以这份数据可以共享,没必要每个task复制一份
- 可以通过广播变量, 通知当前worker上所有的task, 来共享这个数据,避免数据的多次复制,可以大大降低内存的开销
- sparkContext.broadcast(要共享的数据)
spark 安装部署及standalone模式介绍
学习目标
-
知道Spark的安装过程,知道standalone启动模式
-
知道spark作业提交集群的过程
1 spark 安装部署
- 修改配置文件
- spark-env.sh(需要将spark-env.sh.template重命名)
- 配置java环境变量
- export JAVA_HOME=java_home_path
- 配置PYTHON环境
- export PYSPARK_PYTHON=/xx/pythonx_home/bin/pythonx
- 配置master的地址
- export SPARK_MASTER_HOST=node-teach
- 配置master的端口
- export SPARK_MASTER_PORT=7077
- 配置java环境变量
- spark-env.sh(需要将spark-env.sh.template重命名)
- 配置spark环境变量
- export SPARK_HOME=/xxx/spark2.x
- export PATH=$PATH:$SPARK_HOME/bin
2 Spark Standalone模式启动
启动Spark集群
-
进入到$SPARK_HOME/sbin目录
- 启动Master
./start-master.sh -h 192.168.19.137- 启动Slave
./start-slave.sh spark://192.168.19.137:7077- jps查看进程
27073 Master 27151 Worker- 关闭防火墙
systemctl stop firewalld- 通过SPARK WEB UI查看Spark集群及Spark
- http://192.168.19.137:8080/ 监控Spark集群
- http://192.168.19.137:4040/ 监控Spark Job
3 spark 集群相关概念
-
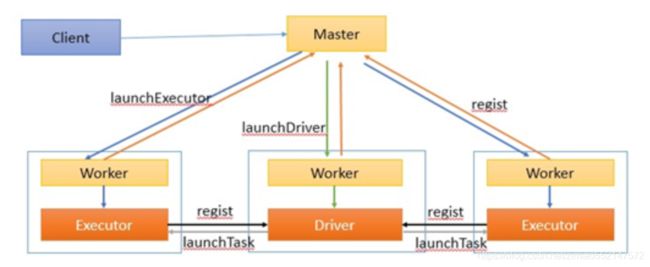
spark集群架构(Standalone模式)
-
-
-
Application
用户自己写的Spark应用程序,批处理作业的集合。Application的main方法为应用程序的入口,用户通过Spark的API,定义了RDD和对RDD的操作。
-
Master和Worker
整个集群分为 Master 节点和 Worker 节点,相当于 Hadoop 的 Master 和 Slave 节点。
- Master:Standalone模式中主控节点,负责接收Client提交的作业,管理Worker,并命令Worker启动Driver和Executor。
- Worker:Standalone模式中slave节点上的守护进程,负责管理本节点的资源,定期向Master汇报心跳,接收Master的命令,启动Driver和Executor。
-
Client:客户端进程,负责提交作业到Master。
-
Driver: 一个Spark作业运行时包括一个Driver进程,也是作业的主进程,负责作业的解析、生成Stage并调度Task到Executor上。包括DAGScheduler,TaskScheduler。
-
Executor:即真正执行作业的地方,一个集群一般包含多个Executor,每个Executor接收Driver的命令Launch Task,一个Executor可以执行一到多个Task。
-
-
Spark作业相关概念
-
Stage:一个Spark作业一般包含一到多个Stage。
-
Task:一个Stage包含一到多个Task,通过多个Task实现并行运行的功能。
-
DAGScheduler: 实现将Spark作业分解成一到多个Stage,每个Stage根据RDD的Partition个数决定Task的个数,然后生成相应的Task 放到TaskScheduler中。
-
TaskScheduler:实现Task分配到Executor上执行。
-
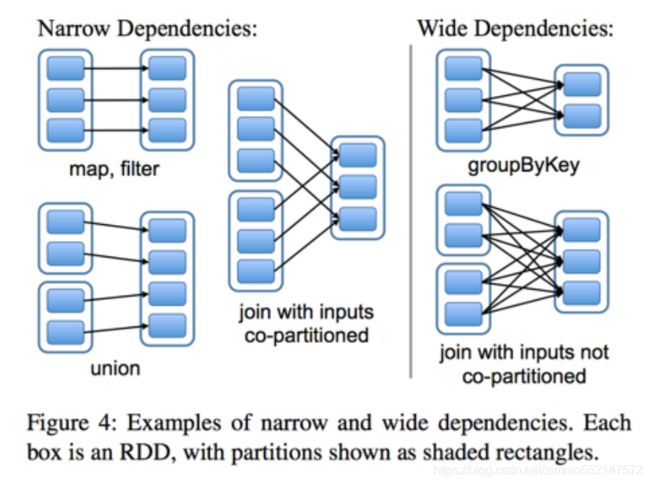
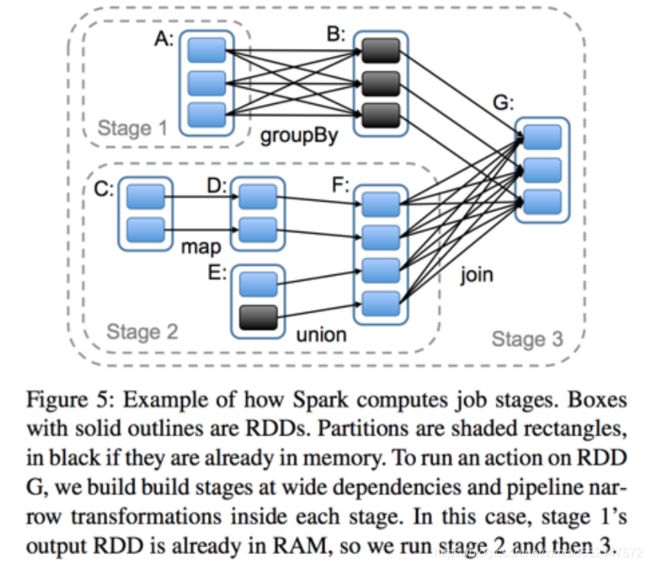
1、Spark SQL 概述
Spark SQL概念
- Spark SQL is Apache Spark's module for working with structured data.
- 它是spark中用于处理结构化数据的一个模块
Spark SQL历史
- Hive是目前大数据领域,事实上的数据仓库标准。
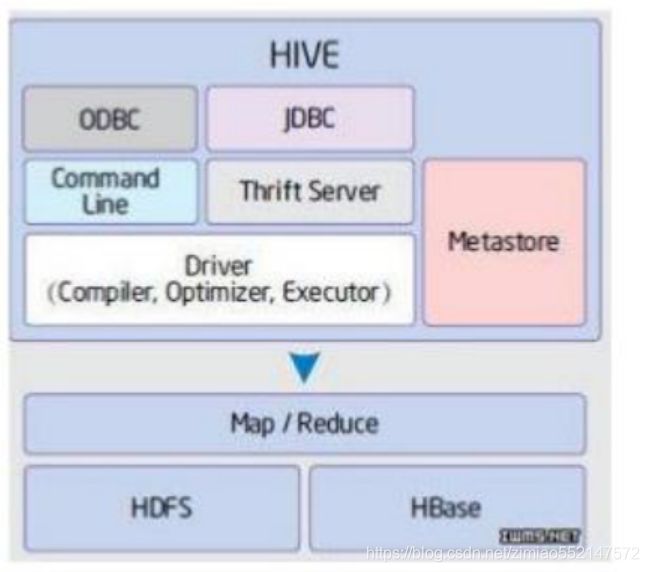
- Shark:shark底层使用spark的基于内存的计算模型,从而让性能比Hive提升了数倍到上百倍。
- 底层很多东西还是依赖于Hive,修改了内存管理、物理计划、执行三个模块
- 2014年6月1日的时候,Spark宣布了不再开发Shark,全面转向Spark SQL的开发
Spark SQL优势
- Write Less Code

- Performance
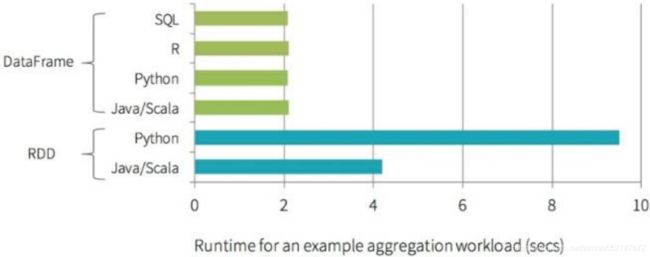
python操作RDD,转换为可执行代码,运行在java虚拟机,涉及两个不同语言引擎之间的切换,进行进程间 通信很耗费性能。
DataFrame
- 是RDD为基础的分布式数据集,类似于传统关系型数据库的二维表,dataframe记录了对应列的名称和类型
- dataFrame引入schema和off-heap(使用操作系统层面上的内存)
- 1、解决了RDD的缺点
- 序列化和反序列化开销大
- 频繁的创建和销毁对象造成大量的GC
- 2、丢失了RDD的优点
- RDD编译时进行类型检查
- RDD具有面向对象编程的特性
用scala/python编写的RDD比Spark SQL编写转换的RDD慢,涉及到执行计划
- CatalystOptimizer:Catalyst优化器
- ProjectTungsten:钨丝计划,为了提高RDD的效率而制定的计划
- Code gen:代码生成器
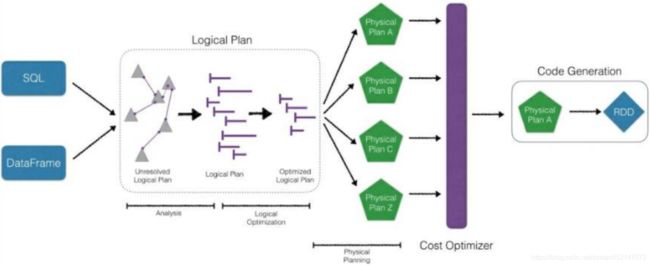
直接编写RDD也可以自实现优化代码,但是远不及SparkSQL前面的优化操作后转换的RDD效率高,快1倍左右
优化引擎:类似mysql等关系型数据库基于成本的优化器
首先执行逻辑执行计划,然后转换为物理执行计划(选择成本最小的),通过Code Generation最终生成为RDD
-
Language-independent API
用任何语言编写生成的RDD都一样,而使用spark-core编写的RDD,不同的语言生成不同的RDD
-
Schema
结构化数据,可以直接看出数据的详情
在RDD中无法看出,解释性不强,无法告诉引擎信息,没法详细优化。
为什么要学习sparksql
sparksql特性
- 1、易整合
- 2、统一的数据源访问
- 3、兼容hive
- 4、提供了标准的数据库连接(jdbc/odbc)
2、DataFrame
2.1 介绍
在Spark语义中,DataFrame是一个分布式的行集合,可以想象为一个关系型数据库的表,或者一个带有列名的Excel表格。它和RDD一样,有这样一些特点:
- Immuatable:一旦RDD、DataFrame被创建,就不能更改,只能通过transformation生成新的RDD、DataFrame
- Lazy Evaluations:只有action才会触发Transformation的执行
- Distributed:DataFrame和RDD一样都是分布式的
- dataframe和dataset统一,dataframe只是dataset[ROW]的类型别名。由于Python是弱类型语言,只能使用DataFrame
DataFrame vs RDD
- RDD:分布式的对象的集合,Spark并不知道对象的详细模式信息
- DataFrame:分布式的Row对象的集合,其提供了由列组成的详细模式信息,使得Spark SQL可以进行某些形式的执行优化。
- DataFrame和普通的RDD的逻辑框架区别如下所示:
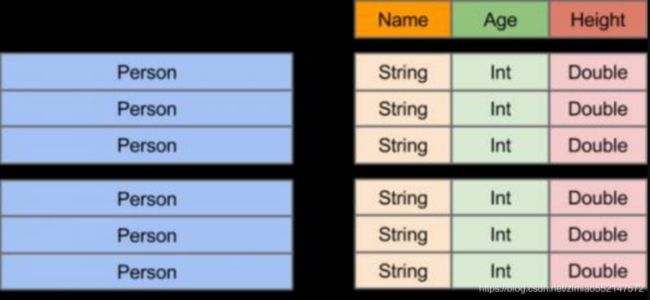
-
左侧的RDD Spark框架本身不了解 Person类的内部结构。
-
右侧的DataFrame提供了详细的结构信息(schema——每列的名称,类型)
- DataFrame还配套了新的操作数据的方法,DataFrame API(如df.select())和SQL(select id, name from xx_table where ...)。
-
DataFrame还引入了off-heap,意味着JVM堆以外的内存, 这些内存直接受操作系统管理(而不是JVM)。
-
RDD是分布式的Java对象的集合。DataFrame是分布式的Row对象的集合。DataFrame除了提供了比RDD更丰富的算子以外,更重要的特点是提升执行效率、减少数据读取以及执行计划的优化。
- DataFrame的抽象后,我们处理数据更加简单了,甚至可以用SQL来处理数据了
- 通过DataFrame API或SQL处理数据,会自动经过Spark 优化器(Catalyst)的优化,即使你写的程序或SQL不仅高效,也可以运行的很快。
- DataFrame相当于是一个带着schema的RDD
Pandas DataFrame vs Spark DataFrame
- Cluster Parallel:集群并行执行
- Lazy Evaluations: 只有action才会触发Transformation的执行
- Immutable:不可更改
- Pandas rich API:比Spark SQL api丰富
2.2 创建DataFrame
1,创建dataFrame的步骤
调用方法例如:spark.read.xxx方法
2,其他方式创建dataframe
-
createDataFrame:pandas dataframe、list、RDD
-
数据源:RDD、csv、json、parquet、orc、jdbc
jsonDF = spark.read.json("xxx.json") jsonDF = spark.read.format('json').load('xxx.json') parquetDF = spark.read.parquet("xxx.parquet") jdbcDF = spark.read.format("jdbc").option("url","jdbc:mysql://localhost:3306/db_name").option("dbtable","table_name").option("user","xxx").option("password","xxx").load() -
Transformation:延迟性操作
-
action:立即操作

2.3 DataFrame API实现
基于RDD创建
from pyspark.sql import SparkSession
from pyspark.sql import Row
spark = SparkSession.builder.appName('test').getOrCreate()
sc = spark.sparkContext
# spark.conf.set("spark.sql.shuffle.partitions", 6)
# ================直接创建==========================
l = [('Ankit',25),('Jalfaizy',22),('saurabh',20),('Bala',26)]
rdd = sc.parallelize(l)
#为数据添加列名
people = rdd.map(lambda x: Row(name=x[0], age=int(x[1])))
#创建DataFrame
schemaPeople = spark.createDataFrame(people)
从csv中读取数据
# ==================从csv读取======================
#加载csv类型的数据并转换为DataFrame
df = spark.read.format("csv"). \
option("header", "true") \
.load("iris.csv")
#显示数据结构
df.printSchema()
#显示前10条数据
df.show(10)
#统计总量
df.count()
#列名
df.columns
增加一列
# ===============增加一列(或者替换) withColumn===========
#定义一个新的列,数据为其他某列数据的两倍
#如果操作的是原有列,可以替换原有列的数据
df.withColumn('newWidth',df.SepalWidth * 2).show()
删除一列
# ==========删除一列 drop=========================
#删除一列
df.drop('cls').show()
统计信息
#================ 统计信息 describe================
df.describe().show()
#计算某一列的描述信息
df.describe('cls').show()
提取部分列
# ===============提取部分列 select==============
df.select('SepalLength','SepalWidth').show()
基本统计功能
# ==================基本统计功能 distinct count=====
df.select('cls').distinct().count()
分组统计
# 分组统计 groupby(colname).agg({'col':'fun','col2':'fun2'})
df.groupby('cls').agg({'SepalWidth':'mean','SepalLength':'max'}).show()
# avg(), count(), countDistinct(), first(), kurtosis(),
# max(), mean(), min(), skewness(), stddev(), stddev_pop(),
# stddev_samp(), sum(), sumDistinct(), var_pop(), var_samp() and variance()
自定义的汇总方法
# 自定义的汇总方法
import pyspark.sql.functions as fn
#调用函数并起一个别名
df.agg(fn.count('SepalWidth').alias('width_count'),fn.countDistinct('cls').alias('distinct_cls_count')).show()
拆分数据集
#====================数据集拆成两部分 randomSplit ===========
#设置数据比例将数据划分为两部分
trainDF, testDF = df.randomSplit([0.6, 0.4])
采样数据
# ================采样数据 sample===========
#withReplacement:是否有放回的采样
#fraction:采样比例
#seed:随机种子
sdf = df.sample(False,0.2,100)
查看两个数据集在类别上的差异
#查看两个数据集在类别上的差异 subtract,确保训练数据集覆盖了所有分类
diff_in_train_test = testDF.select('cls').subtract(trainDF.select('cls'))
diff_in_train_test.distinct().count()
交叉表
# ================交叉表 crosstab=============
df.crosstab('cls','SepalLength').show()
udf
udf:自定义函数
#================== 综合案例 + udf================
# 测试数据集中有些类别在训练集中是不存在的,找到这些数据集做后续处理
trainDF,testDF = df.randomSplit([0.99,0.01])
diff_in_train_test = trainDF.select('cls').subtract(testDF.select('cls')).distinct().show()
#首先找到这些类,整理到一个列表
not_exist_cls = trainDF.select('cls').subtract(testDF.select('cls')).distinct().rdd.map(lambda x :x[0]).collect()
#定义一个方法,用于检测
def should_remove(x):
if x in not_exist_cls:
return -1
else :
return x
#创建udf,udf函数需要两个参数:
# Function
# Return type (in my case StringType())
#在RDD中可以直接定义函数,交给rdd的transformatioins方法进行执行
#在DataFrame中需要通过udf将自定义函数封装成udf函数再交给DataFrame进行调用执行
from pyspark.sql.types import StringType
from pyspark.sql.functions import udf
check = udf(should_remove,StringType())
resultDF = trainDF.withColumn('New_cls',check(trainDF['cls'])).filter('New_cls <> -1')
resultDF.show()3、JSON数据的处理
3.1 介绍
JSON数据
-
Spark SQL can automatically infer the schema of a JSON dataset and load it as a DataFrame
Spark SQL能够自动将JSON数据集以结构化的形式加载为一个DataFrame
-
This conversion can be done using SparkSession.read.json on a JSON file
读取一个JSON文件可以用SparkSession.read.json方法
从JSON到DataFrame
-
指定DataFrame的schema
1,通过反射自动推断,适合静态数据
2,程序指定,适合程序运行中动态生成的数据
加载json数据
#使用内部的schema
jsonDF = spark.read.json("xxx.json")
jsonDF = spark.read.format('json').load('xxx.json')
#指定schema
jsonDF = spark.read.schema(jsonSchema).json('xxx.json')
嵌套结构的JSON
-
重要的方法
1,get_json_object
2,get_json
3,explode
3.2 实践
3.1 静态json数据的读取和操作
无嵌套结构的json数据
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName('json_demo').getOrCreate()
sc = spark.sparkContext
# ==========================================
# 无嵌套结构的json
# ==========================================
jsonString = [
"""{ "id" : "01001", "city" : "AGAWAM", "pop" : 15338, "state" : "MA" }""",
"""{ "id" : "01002", "city" : "CUSHMAN", "pop" : 36963, "state" : "MA" }"""
]
从json字符串数组得到DataFrame
# 从json字符串数组得到rdd有两种方法
# 1. 转换为rdd,再从rdd到DataFrame
# 2. 直接利用spark.createDataFrame(),见后面例子
jsonRDD = sc.parallelize(jsonString) # stringJSONRDD
jsonDF = spark.read.json(jsonRDD) # convert RDD into DataFrame
jsonDF.printSchema()
jsonDF.show()
直接从文件生成DataFrame
# -- 直接从文件生成DataFrame
#只有被压缩后的json文件内容,才能被spark-sql正确读取,否则格式化后的数据读取会出现问题
jsonDF = spark.read.json("xxx.json")
# or
# jsonDF = spark.read.format('json').load('xxx.json')
jsonDF.printSchema()
jsonDF.show()
jsonDF.filter(jsonDF.pop>4000).show(10)
#依照已有的DataFrame,创建一个临时的表(相当于mysql数据库中的一个表),这样就可以用纯sql语句进行数据操作
jsonDF.createOrReplaceTempView("tmp_table")
resultDF = spark.sql("select * from tmp_table where pop>4000")
resultDF.show(10)
3.2 动态json数据的读取和操作
指定DataFrame的Schema
3.1节中的例子为通过反射自动推断schema,适合静态数据
下面我们来讲解如何进行程序指定schema
没有嵌套结构的json
jsonString = [
"""{ "id" : "01001", "city" : "AGAWAM", "pop" : 15338, "state" : "MA" }""",
"""{ "id" : "01002", "city" : "CUSHMAN", "pop" : 36963, "state" : "MA" }"""
]
jsonRDD = sc.parallelize(jsonString)
from pyspark.sql.types import *
#定义结构类型
#StructType:schema的整体结构,表示JSON的对象结构
#XXXStype:指的是某一列的数据类型
jsonSchema = StructType() \
.add("id", StringType(),True) \
.add("city", StringType()) \
.add("pop" , LongType()) \
.add("state",StringType())
jsonSchema = StructType() \
.add("id", LongType(),True) \
.add("city", StringType()) \
.add("pop" , DoubleType()) \
.add("state",StringType())
reader = spark.read.schema(jsonSchema)
jsonDF = reader.json(jsonRDD)
jsonDF.printSchema()
jsonDF.show()
带有嵌套结构的json
from pyspark.sql.types import *
jsonSchema = StructType([
StructField("id", StringType(), True),
StructField("city", StringType(), True),
StructField("loc" , ArrayType(DoubleType())),
StructField("pop", LongType(), True),
StructField("state", StringType(), True)
])
reader = spark.read.schema(jsonSchema)
jsonDF = reader.json('data/nest.json')
jsonDF.printSchema()
jsonDF.show(2)
jsonDF.filter(jsonDF.pop>4000).show(10)4、数据清洗
前面我们处理的数据实际上都是已经被处理好的规整数据,但是在大数据整个生产过程中,需要先对数据进行数据清洗,将杂乱无章的数据整理为符合后面处理要求的规整数据。
数据去重
'''
1.删除重复数据
groupby().count():可以看到数据的重复情况
'''
df = spark.createDataFrame([
(1, 144.5, 5.9, 33, 'M'),
(2, 167.2, 5.4, 45, 'M'),
(3, 124.1, 5.2, 23, 'F'),
(4, 144.5, 5.9, 33, 'M'),
(5, 133.2, 5.7, 54, 'F'),
(3, 124.1, 5.2, 23, 'F'),
(5, 129.2, 5.3, 42, 'M'),
], ['id', 'weight', 'height', 'age', 'gender'])
# 查看重复记录
#无意义重复数据去重:数据中行与行完全重复
# 1.首先删除完全一样的记录
df2 = df.dropDuplicates()
#有意义去重:删除除去无意义字段之外的完全重复的行数据
# 2.其次,关键字段值完全一模一样的记录(在这个例子中,是指除了id之外的列一模一样)
# 删除某些字段值完全一样的重复记录,subset参数定义这些字段
df3 = df2.dropDuplicates(subset = [c for c in df2.columns if c!='id'])
# 3.有意义的重复记录去重之后,再看某个无意义字段的值是否有重复(在这个例子中,是看id是否重复)
# 查看某一列是否有重复值
import pyspark.sql.functions as fn
df3.agg(fn.count('id').alias('id_count'),fn.countDistinct('id').alias('distinct_id_count')).collect()
# 4.对于id这种无意义的列重复,添加另外一列自增id
df3.withColumn('new_id',fn.monotonically_increasing_id()).show()
缺失值处理
'''
2.处理缺失值
2.1 对缺失值进行删除操作(行,列)
2.2 对缺失值进行填充操作(列的均值)
2.3 对缺失值对应的行或列进行标记
'''
df_miss = spark.createDataFrame([
(1, 143.5, 5.6, 28,'M', 100000),
(2, 167.2, 5.4, 45,'M', None),
(3, None , 5.2, None, None, None),
(4, 144.5, 5.9, 33, 'M', None),
(5, 133.2, 5.7, 54, 'F', None),
(6, 124.1, 5.2, None, 'F', None),
(7, 129.2, 5.3, 42, 'M', 76000),],
['id', 'weight', 'height', 'age', 'gender', 'income'])
# 1.计算每条记录的缺失值情况
df_miss.rdd.map(lambda row:(row['id'],sum([c==None for c in row]))).collect()
[(1, 0), (2, 1), (3, 4), (4, 1), (5, 1), (6, 2), (7, 0)]
# 2.计算各列的缺失情况百分比
df_miss.agg(*[(1 - (fn.count(c) / fn.count('*'))).alias(c + '_missing') for c in df_miss.columns]).show()
# 3、删除缺失值过于严重的列
# 其实是先建一个DF,不要缺失值的列
df_miss_no_income = df_miss.select([
c for c in df_miss.columns if c != 'income'
])
# 4、按照缺失值删除行(threshold是根据一行记录中,缺失字段的百分比的定义)
df_miss_no_income.dropna(thresh=3).show()
# 5、填充缺失值,可以用fillna来填充缺失值,
# 对于bool类型、或者分类类型,可以为缺失值单独设置一个类型,missing
# 对于数值类型,可以用均值或者中位数等填充
# fillna可以接收两种类型的参数:
# 一个数字、字符串,这时整个DataSet中所有的缺失值都会被填充为相同的值。
# 也可以接收一个字典{列名:值}这样
# 先计算均值,并组织成一个字典
means = df_miss_no_income.agg( *[fn.mean(c).alias(c) for c in df_miss_no_income.columns if c != 'gender']).toPandas().to_dict('records')[0]
# 然后添加其它的列
means['gender'] = 'missing'
df_miss_no_income.fillna(means).show()
异常值处理
'''
3、异常值处理
异常值:不属于正常的值 包含:缺失值,超过正常范围内的较大值或较小值
分位数去极值
中位数绝对偏差去极值
正态分布去极值
上述三种操作的核心都是:通过原始数据设定一个正常的范围,超过此范围的就是一个异常值
'''
df_outliers = spark.createDataFrame([
(1, 143.5, 5.3, 28),
(2, 154.2, 5.5, 45),
(3, 342.3, 5.1, 99),
(4, 144.5, 5.5, 33),
(5, 133.2, 5.4, 54),
(6, 124.1, 5.1, 21),
(7, 129.2, 5.3, 42),
], ['id', 'weight', 'height', 'age'])
# 设定范围 超出这个范围的 用边界值替换
# approxQuantile方法接收三个参数:参数1,列名;参数2:想要计算的分位点,可以是一个点,也可以是一个列表(0和1之间的小数),第三个参数是能容忍的误差,如果是0,代表百分百精确计算。
cols = ['weight', 'height', 'age']
bounds = {}
for col in cols:
quantiles = df_outliers.approxQuantile(col, [0.25, 0.75], 0.05)
IQR = quantiles[1] - quantiles[0]
bounds[col] = [
quantiles[0] - 1.5 * IQR,
quantiles[1] + 1.5 * IQR
]
>>> bounds
{'age': [-11.0, 93.0], 'height': [4.499999999999999, 6.1000000000000005], 'weight': [91.69999999999999, 191.7]}
# 为异常值字段打标志
outliers = df_outliers.select(*['id'] + [( (df_outliers[c] < bounds[c][0]) | (df_outliers[c] > bounds[c][1]) ).alias(c + '_o') for c in cols ])
outliers.show()
#
# +---+--------+--------+-----+
# | id|weight_o|height_o|age_o|
# +---+--------+--------+-----+
# | 1| false| false|false|
# | 2| false| false|false|
# | 3| true| false| true|
# | 4| false| false|false|
# | 5| false| false|false|
# | 6| false| false|false|
# | 7| false| false|false|
# +---+--------+--------+-----+
# 再回头看看这些异常值的值,重新和原始数据关联
df_outliers = df_outliers.join(outliers, on='id')
df_outliers.filter('weight_o').select('id', 'weight').show()
# +---+------+
# | id|weight|
# +---+------+
# | 3| 342.3|
# +---+------+
df_outliers.filter('age_o').select('id', 'age').show()
# +---+---+
# | id|age|
# +---+---+
# | 3| 99|
# +---+---+1、sparkStreaming概述
1.1 SparkStreaming是什么
-
它是一个可扩展,高吞吐具有容错性的流式计算框架
吞吐量:单位时间内成功传输数据的数量
之前我们接触的spark-core和spark-sql都是处理属于离线批处理任务,数据一般都是在固定位置上,通常我们写好一个脚本,每天定时去处理数据,计算,保存数据结果。这类任务通常是T+1(一天一个任务),对实时性要求不高。
但在企业中存在很多实时性处理的需求,例如:双十一的京东阿里,通常会做一个实时的数据大屏,显示实时订单。这种情况下,对数据实时性要求较高,仅仅能够容忍到延迟1分钟或几秒钟。

实时计算框架对比
Storm
- 流式计算框架
- 以record为单位处理数据
- 也支持micro-batch方式(Trident)
Spark
- 批处理计算框架
- 以RDD为单位处理数据
- 支持micro-batch流式处理数据(Spark Streaming)
对比:
- 吞吐量:Spark Streaming优于Storm
- 延迟:Spark Streaming差于Storm
1.2 SparkStreaming的组件
- Streaming Context
- 一旦一个Context已经启动(调用了Streaming Context的start()),就不能有新的流算子(Dstream)建立或者是添加到context中
- 一旦一个context已经停止,不能重新启动(Streaming Context调用了stop方法之后 就不能再次调 start())
- 在JVM(java虚拟机)中, 同一时间只能有一个Streaming Context处于活跃状态, 一个SparkContext创建一个Streaming Context
- 在Streaming Context上调用Stop方法, 也会关闭SparkContext对象, 如果只想仅关闭Streaming Context对象,设置stop()的可选参数为false
- 一个SparkContext对象可以重复利用去创建多个Streaming Context对象(不关闭SparkContext前提下), 但是需要关一个再开下一个
- DStream (离散流)
- 代表一个连续的数据流
- 在内部, DStream由一系列连续的RDD组成
- DStreams中的每个RDD都包含确定时间间隔内的数据
- 任何对DStreams的操作都转换成了对DStreams隐含的RDD的操作
- 数据源
- 基本源
- TCP/IP Socket
- FileSystem
- 高级源
- Kafka
- Flume
- 基本源
2、Spark Streaming编码实践
Spark Streaming编码步骤:
- 1,创建一个StreamingContext
- 2,从StreamingContext中创建一个数据对象
- 3,对数据对象进行Transformations操作
- 4,输出结果
- 5,开始和停止
利用Spark Streaming实现WordCount
需求:监听某个端口上的网络数据,实时统计出现的不同单词个数。
1,需要安装一个nc工具:sudo yum install -y nc
2,执行指令:nc -lk 9999 -v
import os
# 配置spark driver和pyspark运行时,所使用的python解释器路径
PYSPARK_PYTHON = "/miniconda2/envs/py365/bin/python"
JAVA_HOME='/root/bigdata/jdk'
SPARK_HOME = "/root/bigdata/spark"
# 当存在多个版本时,不指定很可能会导致出错
os.environ["PYSPARK_PYTHON"] = PYSPARK_PYTHON
os.environ["PYSPARK_DRIVER_PYTHON"] = PYSPARK_PYTHON
os.environ['JAVA_HOME']=JAVA_HOME
os.environ["SPARK_HOME"] = SPARK_HOME
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
if __name__ == "__main__":
sc = SparkContext("local[2]",appName="NetworkWordCount")
#参数2:指定执行计算的时间间隔
ssc = StreamingContext(sc, 1)
#监听ip,端口上的上的数据
lines = ssc.socketTextStream('localhost',9999)
#将数据按空格进行拆分为多个单词
words = lines.flatMap(lambda line: line.split(" "))
#将单词转换为(单词,1)的形式
pairs = words.map(lambda word:(word,1))
#统计单词个数
wordCounts = pairs.reduceByKey(lambda x,y:x+y)
#打印结果信息,会使得前面的transformation操作执行
wordCounts.pprint()
#启动StreamingContext
ssc.start()
#等待计算结束
ssc.awaitTermination()
可视化查看效果:http://192.168.19.137:4040
点击streaming,查看效果
3、Spark Streaming的状态操作
在Spark Streaming中存在两种状态操作
- UpdateStateByKey
- Windows操作
使用有状态的transformation,需要开启Checkpoint
- spark streaming 的容错机制
- 它将足够多的信息checkpoint到某些具备容错性的存储系统如hdfs上,以便出错时能够迅速恢复
3.1 updateStateByKey
Spark Streaming实现的是一个实时批处理操作,每隔一段时间将数据进行打包,封装成RDD,是无状态的。
无状态:指的是每个时间片段的数据之间是没有关联的。
需求:想要将一个大时间段(1天),即多个小时间段的数据内的数据持续进行累积操作
一般超过一天都是用RDD或Spark SQL来进行离线批处理
如果没有UpdateStateByKey,我们需要将每一秒的数据计算好放入mysql中取,再用mysql来进行统计计算
Spark Streaming中提供这种状态保护机制,即updateStateByKey
步骤:
- 首先,要定义一个state,可以是任意的数据类型
- 其次,要定义state更新函数--指定一个函数如何使用之前的state和新值来更新state
- 对于每个batch,Spark都会为每个之前已经存在的key去应用一次state更新函数,无论这个key在batch中是否有新的数据。如果state更新函数返回none,那么key对应的state就会被删除
- 对于每个新出现的key,也会执行state更新函数
举例:词统计。
案例:updateStateByKey
需求:监听网络端口的数据,获取到每个批次的出现的单词数量,并且需要把每个批次的信息保留下来
代码
import os
# 配置spark driver和pyspark运行时,所使用的python解释器路径
PYSPARK_PYTHON = "/miniconda2/envs/py365/bin/python"
JAVA_HOME='/root/bigdata/jdk'
SPARK_HOME = "/root/bigdata/spark"
# 当存在多个版本时,不指定很可能会导致出错
os.environ["PYSPARK_PYTHON"] = PYSPARK_PYTHON
os.environ["PYSPARK_DRIVER_PYTHON"] = PYSPARK_PYTHON
os.environ['JAVA_HOME']=JAVA_HOME
os.environ["SPARK_HOME"] = SPARK_HOME
from pyspark.streaming import StreamingContext
from pyspark.sql.session import SparkSession
# 创建SparkContext
spark = SparkSession.builder.master("local[2]").getOrCreate()
sc = spark.sparkContext
ssc = StreamingContext(sc, 3)
#开启检查点
ssc.checkpoint("checkpoint")
#定义state更新函数
def updateFunc(new_values, last_sum):
return sum(new_values) + (last_sum or 0)
lines = ssc.socketTextStream("localhost", 9999)
# 对数据以空格进行拆分,分为多个单词
counts = lines.flatMap(lambda line: line.split(" ")) \
.map(lambda word: (word, 1)) \
.updateStateByKey(updateFunc=updateFunc)#应用updateStateByKey函数
counts.pprint()
ssc.start()
ssc.awaitTermination()
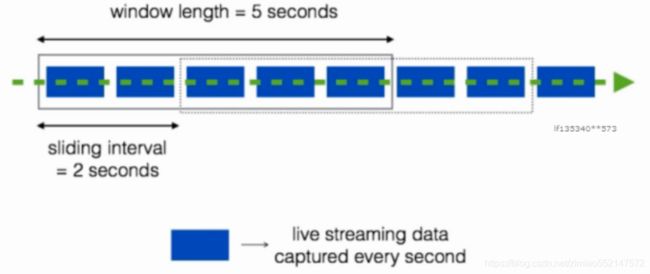
3.2 Windows
- 窗口长度L:运算的数据量
- 滑动间隔G:控制每隔多长时间做一次运算
每隔G秒,统计最近L秒的数据
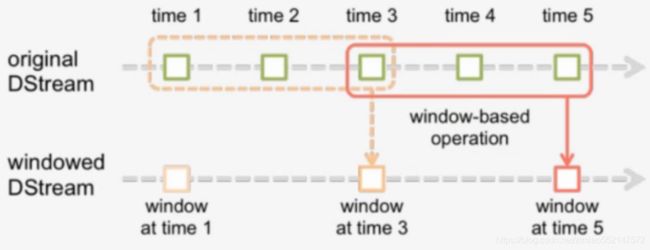
操作细节
- Window操作是基于窗口长度和滑动间隔来工作的
- 窗口的长度控制考虑前几批次数据量
- 默认为批处理的滑动间隔来确定计算结果的频率
相关函数

- Smart computation
- invAddFunc
reduceByKeyAndWindow(func,invFunc,windowLength,slideInterval,[num,Tasks])
func:正向操作,类似于updateStateByKey
invFunc:反向操作
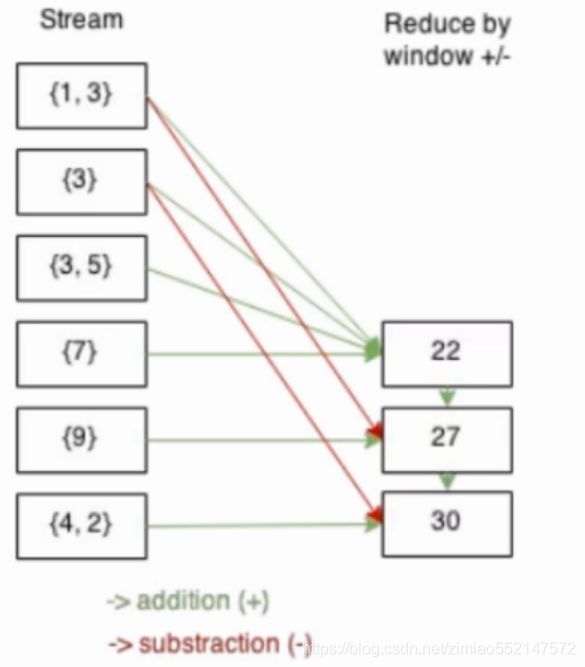
例如在热词时,在上一个窗口中可能是热词,这个一个窗口中可能不是热词,就需要在这个窗口中把该次剔除掉
典型案例:热点搜索词滑动统计,每隔10秒,统计最近60秒钟的搜索词的搜索频次,并打印出最靠前的3个搜索词出现次数。
案例
监听网络端口的数据,每隔3秒统计前6秒出现的单词数量
import os
# 配置spark driver和pyspark运行时,所使用的python解释器路径
PYSPARK_PYTHON = "/miniconda2/envs/py365/bin/python"
JAVA_HOME='/root/bigdata/jdk'
SPARK_HOME = "/root/bigdata/spark"
# 当存在多个版本时,不指定很可能会导致出错
os.environ["PYSPARK_PYTHON"] = PYSPARK_PYTHON
os.environ["PYSPARK_DRIVER_PYTHON"] = PYSPARK_PYTHON
os.environ['JAVA_HOME']=JAVA_HOME
os.environ["SPARK_HOME"] = SPARK_HOME
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
from pyspark.sql.session import SparkSession
def get_countryname(line):
country_name = line.strip()
if country_name == 'usa':
output = 'USA'
elif country_name == 'ind':
output = 'India'
elif country_name == 'aus':
output = 'Australia'
else:
output = 'Unknown'
return (output, 1)
if __name__ == "__main__":
#定义处理的时间间隔
batch_interval = 1 # base time unit (in seconds)
#定义窗口长度
window_length = 6 * batch_interval
#定义滑动时间间隔
frequency = 3 * batch_interval
#获取StreamingContext
spark = SparkSession.builder.master("local[2]").getOrCreate()
sc = spark.sparkContext
ssc = StreamingContext(sc, batch_interval)
#需要设置检查点
ssc.checkpoint("checkpoint")
lines = ssc.socketTextStream('localhost', 9999)
addFunc = lambda x, y: x + y
invAddFunc = lambda x, y: x - y
#调用reduceByKeyAndWindow,来进行窗口函数的调用
window_counts = lines.map(get_countryname) \
.reduceByKeyAndWindow(addFunc, invAddFunc, window_length, frequency)
#输出处理结果信息
window_counts.pprint()
ssc.start()
ssc.awaitTermination()