python 爬虫 3 (实例:爬取网站照片、一句代码抓取图片)
爬取下厨房网站照片
-
- 写在前面
-
- 1、爬取下厨房网站照片
- 2、把代码改成正则表达式
- 3、在linux里面用一句代码抓取下载所有的图片
-
- 补充知识
- 一句代码抓取下载所有的图片
写在前面
下厨房官网:
http://www.xiachufang.com/
一个简单的实例爬取图片:用到requests、bs4、正则等
1、爬取下厨房网站照片
分析下厨房的源码,图片在img标签下

这里我们获取它的ing标签

from bs4 import BeautifulSoup
import requests
r = requests.get('http://www.xiachufang.com/')
soup = BeautifulSoup(r.text)
print(soup.select('img'))
查看我们获取的数据,我们发现部分src里面存的是一个b64码,真正的图片地址在data-src里面

所以把img标签里的有data-src的就取data-src
img_list = []
for img in soup.select('img'):
if img.has_attr("data-src"):
img_list.append(img.attr['data-src'])
else:
img_list.append(img.attr['src'])
创建文件夹
# 在当前目录创建文件夹img
img_dir = os.path.join(os.curdir, "img")
# 如果img目录不存在,创建img文件夹
if not os.path.isdir(img_dir):
os.mkdir(img_dir)
o = urlparse(img)
print(o.path)
查看img的路径是这样的
![]()
解析img的路径并切割,保存图片
# 下载图片
for img in img_list:
# urlparse()方法进行URL的解析,返回值包括了scheme、netloc、path等
o = urlparse(img)
# o.path[1:]截取path中除第一位以后的字符。 split("@")[0]以@为切割点,取第一个数据
img_name = o.path[1:].split("@")[0]
# 图片名(文件)
img_path = os.path.join(img_dir, img_name)
# 图片下载地址
url = '%s://%s/%s' % (o.scheme, o.netloc, img_name)
# 图片的二进制数据
resp = requests.get(url)
# 把二进制数据写入图片中
with open(img_path, "wb") as f:
# 每次写1024个字节
for c in resp.iter_content(1024):
f.write(c)
运行后

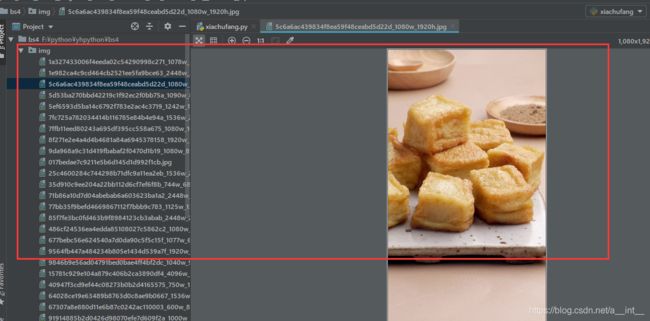
后面会报这样的错误

我们打印一下img_name(它后面的都先注释掉)

运行后我们发现最后有两张svg矢量图,里面夹带了二级目录,所以我们在写入图片之前加一个判断
再运行就没有错误了,下面是除去注释后的全部代码
from bs4 import BeautifulSoup
from urllib.parse import urlparse
import requests
import os
r = requests.get('http://www.xiachufang.com/')
soup = BeautifulSoup(r.text)
img_list = []
for img in soup.select('img'):
if img.has_attr("data-src"):
img_list.append(img.attrs['data-src'])
else:
img_list.append(img.attrs['src'])
img_dir = os.path.join(os.curdir, "img")
if not os.path.isdir(img_dir):
os.mkdir(img_dir)
for img in img_list:
o = urlparse(img)
img_name = o.path[1:].split("@")[0]
img_path = os.path.join(img_dir, img_name)
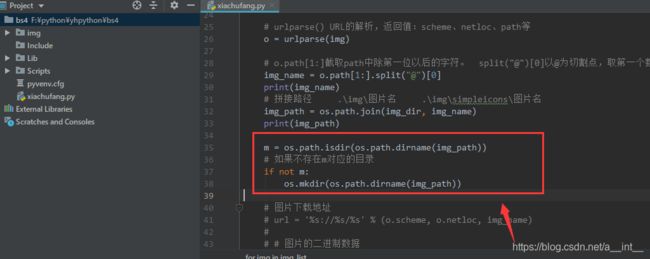
m = os.path.isdir(os.path.dirname(img_path))
if not m:
os.mkdir(os.path.dirname(img_path))
url = '%s://%s/%s' % (o.scheme, o.netloc, img_name)
resp = requests.get(url)
with open(img_path, "wb") as f:
for c in resp.iter_content(1024):
f.write(c)
2、把代码改成正则表达式
先获取网页数据,这里我们改用Curl获取

观察我们需要爬取的数据:src=…
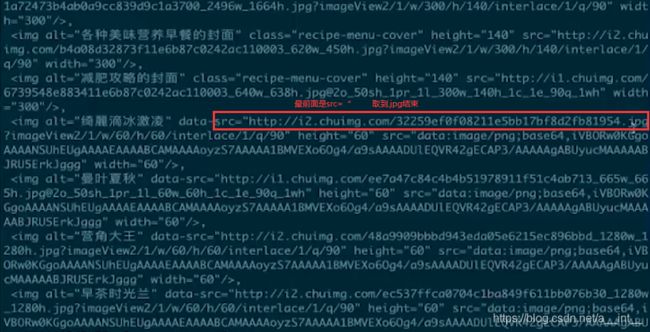
用正则搜索数据

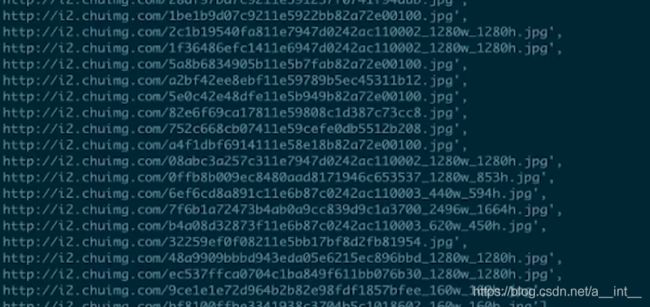
搜索结果
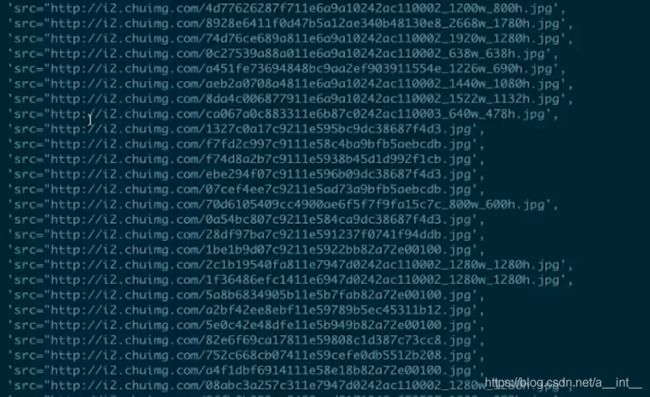
我们只需要网址部分,括起来
![]()
搜索结果
其余部分和之前基本一样
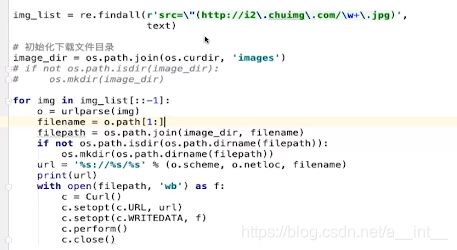
3、在linux里面用一句代码抓取下载所有的图片
补充知识
安装curl后可直接使用:cur url返回网页内容,-s表示不打印访问连接信息
curl -s url
正则里面: 匹配abc但不想包含abc写法
(?<=abc)
linux管道、搜索语法:| 是管道工具,grep搜索: -o 显示被模式匹配到的字符串,-P 支持正则表达式
数据 | grep -oP ‘正则语法’
linux语法: |xargs 把前面的数据作为一个参数供下个函数使用,-i如果没有指定参数, 则使用字符串 "{ }“
数据 |xargs -i curl { } -o
curl 语法:curl -o 下载文件
curl url -o
curl 语法:curl -O指定路径
curl url -O
curl 语法:创建目录
–create-dir
一句代码抓取下载所有的图片
![]()
curl -s http://www.xiachufang.com/|grep -oP '(?<=src=\")http://i2\.chuimg\.com/\w+\.jpg'|xargs -i curl {
} -o
目前这些图片会下载到这个窗口的路径下,接下来我们指定一下路径
curl -s http://www.xiachufang.com/|grep -oP '(?<=src=\")http://i2\.chuimg\.com/\w+\.jpg'|xargs -i curl --create-dir {
} -O ./img/{
}
这里的两次{}是同一个东西,也就是前面xargs 过来的url