使用CNN对CIFAR-10数据集进行分类(tensorflow)
一、CIFAR10数据集
如果下载不了就直接 官网下载CIFAR-10数据集 http://www.cs.toronto.edu/~kriz/cifar.html
下载 CIFAR-10 binary version,解压后文件夹如下
二、CIFAR10数据集官方读取程序(cifar10_input.py)
"""Routine for decoding the CIFAR-10 binary file format."""
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import os
from six.moves import xrange # pylint: disable=redefined-builtin
import tensorflow as tf
# Process images of this size. Note that this differs from the original CIFAR
# image size of 32 x 32. If one alters this number, then the entire model
# architecture will change and any model would need to be retrained.
# 原图像的尺度为32*32,但根据常识,信息部分通常位于图像的中央,
# 这里定义了以中心裁剪后图像的尺寸
IMAGE_SIZE = 24
# Global constants describing the CIFAR-10 data set.
NUM_CLASSES = 10
NUM_EXAMPLES_PER_EPOCH_FOR_TRAIN = 50000
NUM_EXAMPLES_PER_EPOCH_FOR_EVAL = 10000
def read_cifar10(filename_queue):
"""Reads and parses examples from CIFAR10 data files.
Recommendation: if you want N-way read parallelism, call this function
N times. This will give you N independent Readers reading different
files & positions within those files, which will give better mixing of
examples.
Args:
filename_queue: A queue of strings with the filenames to read from.
Returns:
An object representing a single example, with the following fields:
height: number of rows in the result (32)
width: number of columns in the result (32)
depth: number of color channels in the result (3)
key: a scalar string Tensor describing the filename & record number
for this example.
label: an int32 Tensor with the label in the range 0..9.
uint8image: a [height, width, depth] uint8 Tensor with the image data
"""
# 定义一个空的类对象,类似于c语言里面的结构体定义
class CIFAR10Record(object):
pass
result = CIFAR10Record()
# Dimensions of the images in the CIFAR-10 dataset.
# See http://www.cs.toronto.edu/~kriz/cifar.html for a description of the
# input format.
label_bytes = 1 # 2 for CIFAR-100
result.height = 32
result.width = 32
result.depth = 3
# 一张图像占用空间
image_bytes = result.height * result.width * result.depth
# Every record consists of a label followed by the image, with a
# fixed number of bytes for each.
# 数据集中一条记录的组成
record_bytes = label_bytes + image_bytes
# Read a record, getting filenames from the filename_queue. No
# header or footer in the CIFAR-10 format, so we leave header_bytes
# and footer_bytes at their default of 0.
# 定义一个Reader,它每次能从文件中读取固定字节数
reader = tf.FixedLengthRecordReader(record_bytes=record_bytes)
# 返回从filename_queue中读取的(key, value)对,key和value都是字符串类型的tensor,并且当队列中的某一个文件读完成时,该文件名会dequeue
result.key, value = reader.read(filename_queue)
# Convert from a string to a vector of uint8 that is record_bytes long.
# 解码操作可以看作读二进制文件,把字符串中的字节转换为数值向量,每一个数值占用一个字节,在[0, 255]区间内,因此out_type要取uint8类型
record_bytes = tf.decode_raw(value, tf.uint8) # 将字符串Tensor转化成uint8类型
# The first bytes represent the label, which we convert from uint8->int32.
# 从一维tensor对象中截取一个slice,类似于从一维向量中筛选子向量,因为record_bytes中包含了label和feature,故要对向量类型tensor进行'parse'操作
result.label = tf.cast(
tf.strided_slice(record_bytes, [0], [label_bytes]), tf.int32) # 分别表示待截取片段的起点和长度,并且把标签由之前的uint8转变成int32数据类型
# The remaining bytes after the label represent the image, which we reshape.
# from [depth * height * width] to [depth, height, width].
# 提取每条记录中的图像数据为result.depth, result.height, result.width
depth_major = tf.reshape(
tf.strided_slice(record_bytes, [label_bytes],
[label_bytes + image_bytes]),
[result.depth, result.height, result.width])
# Convert from [depth, height, width] to [height, width, depth].
# 改变为height, width, depth
result.uint8image = tf.transpose(depth_major, [1, 2, 0])
return result
# 构建一个排列后的一组图片和分类
def _generate_image_and_label_batch(image, label, min_queue_examples,
batch_size, shuffle):
"""Construct a queued batch of images and labels.
Args:
image: 3-D Tensor of [height, width, 3] of type.float32.
label: 1-D Tensor of type.int32
min_queue_examples: int32, minimum number of samples to retain
in the queue that provides of batches of examples.
batch_size: Number of images per batch.
shuffle: boolean indicating whether to use a shuffling queue.
Returns:
images: Images. 4D tensor of [batch_size, height, width, 3] size.
labels: Labels. 1D tensor of [batch_size] size.
"""
# Create a queue that shuffles the examples, and then
# read 'batch_size' images + labels from the example queue.
# 线程数
num_preprocess_threads = 16
# 布尔指示是否使用一个shuffling队列
if shuffle:
images, label_batch = tf.train.shuffle_batch(
[image, label],
batch_size=batch_size,
num_threads=num_preprocess_threads,
capacity=min_queue_examples + 3 * batch_size,
min_after_dequeue=min_queue_examples)
else:
# tf.train.batch(tensors, batch_size, num_threads=1, capacity=32,
# enqueue_many=False, shapes=None, dynamic_pad=False,
# allow_smaller_final_batch=False, shared_name=None, name=None)
# 这里是用队列实现,已经默认使用enqueue_runner将enqueue_runner加入到Graph'senqueue_runner集合中
# 其默认enqueue_many=False时,输入的tensor为一个样本【x,y,z】,输出为Tensor的一批样本
# capacity:队列中允许最大元素个数
images, label_batch = tf.train.batch(
[image, label],
batch_size=batch_size,
num_threads=num_preprocess_threads,
capacity=min_queue_examples + 3 * batch_size)
# Display the training images in the visualizer.
# 将训练图片可视化,可拱直接检查图片正误
tf.summary.image('images', images)
return images, tf.reshape(label_batch, [batch_size])
# 为CIFAR评价构建输入
# data_dir路径
# batch_size一个组的大小
def distorted_inputs(data_dir, batch_size):
"""Construct distorted input for CIFAR training using the Reader ops.
Args:
data_dir: Path to the CIFAR-10 data directory.
batch_size: Number of images per batch.
Returns:
images: Images. 4D tensor of [batch_size, IMAGE_SIZE, IMAGE_SIZE, 3] size.
labels: Labels. 1D tensor of [batch_size] size.
"""
filenames = [os.path.join(data_dir, 'data_batch_%d.bin' % i)
for i in xrange(1, 6)]
for f in filenames:
if not tf.gfile.Exists(f):
raise ValueError('Failed to find file: ' + f)
# Create a queue that produces the filenames to read.
filename_queue = tf.train.string_input_producer(filenames)
# Read examples from files in the filename queue.
read_input = read_cifar10(filename_queue)
reshaped_image = tf.cast(read_input.uint8image, tf.float32)
height = IMAGE_SIZE
width = IMAGE_SIZE
# Image processing for training the network. Note the many random
# distortions applied to the image.
# Randomly crop a [height, width] section of the image.
distorted_image = tf.random_crop(reshaped_image, [height, width, 3])
# Randomly flip the image horizontally.
distorted_image = tf.image.random_flip_left_right(distorted_image)
# Because these operations are not commutative, consider randomizing
# the order their operation.
# NOTE: since per_image_standardization zeros the mean and makes
# the stddev unit, this likely has no effect see tensorflow#1458.
distorted_image = tf.image.random_brightness(distorted_image,
max_delta=63)
distorted_image = tf.image.random_contrast(distorted_image,
lower=0.2, upper=1.8)
# Subtract off the mean and divide by the variance of the pixels.
float_image = tf.image.per_image_standardization(distorted_image)
# Set the shapes of tensors.
# 设置张量的型
float_image.set_shape([height, width, 3])
read_input.label.set_shape([1])
# Ensure that the random shuffling has good mixing properties.
# 确保洗牌的随机性
min_fraction_of_examples_in_queue = 0.4
min_queue_examples = int(NUM_EXAMPLES_PER_EPOCH_FOR_TRAIN *
min_fraction_of_examples_in_queue)
print('Filling queue with %d CIFAR images before starting to train. '
'This will take a few minutes.' % min_queue_examples)
# Generate a batch of images and labels by building up a queue of examples.
return _generate_image_and_label_batch(float_image, read_input.label,
min_queue_examples, batch_size,
shuffle=True)
# 为CIFAR评价构建输入
# eval_data使用训练还是评价数据集
# data_dir路径
# batch_size一个组的大小
def inputs(eval_data, data_dir, batch_size):
"""Construct input for CIFAR evaluation using the Reader ops.
Args:
eval_data: bool, indicating if one should use the train or eval data set.
data_dir: Path to the CIFAR-10 data directory.
batch_size: Number of images per batch.
Returns:
images: Images. 4D tensor of [batch_size, IMAGE_SIZE, IMAGE_SIZE, 3] size.
labels: Labels. 1D tensor of [batch_size] size.
"""
if not eval_data:
filenames = [os.path.join(data_dir, 'data_batch_%d.bin' % i)
for i in xrange(1, 6)]
num_examples_per_epoch = NUM_EXAMPLES_PER_EPOCH_FOR_TRAIN
else:
filenames = [os.path.join(data_dir, 'test_batch.bin')]
num_examples_per_epoch = NUM_EXAMPLES_PER_EPOCH_FOR_EVAL
for f in filenames:
if not tf.gfile.Exists(f):
raise ValueError('Failed to find file: ' + f)
# Create a queue that produces the filenames to read.
# 文件名队列
# def string_input_producer(string_tensor,
# num_epochs=None,
# shuffle=True,
# seed=None,
# capacity=32,
# shared_name=None,
# name=None,
# cancel_op=None):
# 根据上面的函数可以看出下面的这个默认对输入队列进行shuffle,string_input_producer返回的是字符串队列,
# 使用enqueue_runner将enqueue_runner加入到Graph'senqueue_runner集合中
filename_queue = tf.train.string_input_producer(filenames)
# Read examples from files in the filename queue.
# 从文件队列中读取解析出的图片队列
# read_cifar10从输入文件名队列中读取一条图像记录
read_input = read_cifar10(filename_queue)
# 将记录中的图像记录转换为float32
reshaped_image = tf.cast(read_input.uint8image, tf.float32)
height = IMAGE_SIZE
width = IMAGE_SIZE
# Image processing for evaluation.
# Crop the central [height, width] of the image.
# 将图像裁剪成24*24
resized_image = tf.image.resize_image_with_crop_or_pad(reshaped_image,
height, width)
# Subtract off the mean and divide by the variance of the pixels.
# 对图像数据进行归一化
float_image = tf.image.per_image_standardization(resized_image)
# Set the shapes of tensors.
float_image.set_shape([height, width, 3])
read_input.label.set_shape([1])
# Ensure that the random shuffling has good mixing properties.
min_fraction_of_examples_in_queue = 0.4
min_queue_examples = int(num_examples_per_epoch *
min_fraction_of_examples_in_queue)
# Generate a batch of images and labels by building up a queue of examples.
# 根据当前记录中第一条记录的值,采用多线程的方法,批量读取一个batch中的数据
return _generate_image_and_label_batch(float_image, read_input.label,
min_queue_examples, batch_size,
shuffle=False)
三、训练程序
输入层—>卷积层1(最大池化)—>卷积层2(最大池化)—>全连接1—>全连接2—>全连接3—>输出层
#coding:utf-8
import cifar10_input
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
import time
start =time.clock() #取开始时间
step = [] #step,test_accuracy,training_accuracy均为列表,为保存训练精度曲线的数据
test_accuracy = []
training_accuracy = []
batch_size = 2500 #每次喂入2500个样本,去这个值,在程序运行时CPU的使用率大概在95%,不让CPU满载,
keep_prob = tf.placeholder("float")
#加入指数衰减学习率
LEARNING_RATE_BASE = 0.001 #最初学习率
LEARNING_RATE_DECAY = 0.999 #学习率衰减率
LEARNING_RATE_STEP \
= 50000/batch_size#喂入多少轮BATCH_SIZE后,更新一次学习率,一般设为:总样本数/BATCH_SIZE
#运行了几轮BATCH_SIZE的计数器,初值给0,设为不被训练
global_step = tf.Variable(0, trainable=False)
data_dir = 'C:/tmp/cifar10_data/cifar-10-batches-bin'#cifar数据集的地址
with tf.device('/cpu:0'): #如果没有这一行数据增强时,将会在Gpu上进行,会特别慢
images_train, labels_train = cifar10_input.distorted_inputs(data_dir=data_dir,batch_size=batch_size)#训练时随机进行数据增强(翻转)
#images_train, labels_train = cifar10_input.inputs(eval_data = False,data_dir = data_dir, batch_size = batch_size)#训练时直接进行训练
images_test, labels_test = cifar10_input.inputs(eval_data = True, data_dir = data_dir, batch_size = batch_size)
def weight_variable(shape): #权重变量
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial)
def bias_variable(shape): #阈值变量
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial)
def conv2d(x, W): #卷积层变量(2D)
return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME')
def max_pool_2x2(x): #池化层变量
return tf.nn.max_pool(x, ksize=[1, 2, 2, 1],
strides=[1, 2, 2, 1], padding='SAME')
def avg_pool_6x6(x): #池化层变量
return tf.nn.avg_pool(x, ksize=[1, 6, 6, 1],
strides=[1, 6, 6, 1], padding='SAME')
#搭建神经网络 输入层——>卷积层1(最大池化)——>卷积层2(最大池化)——>全连接1——>全连接2——>全连接3——>输出层
x = tf.placeholder(tf.float32, [None, 24,24,3]) # 维度 24*24
y = tf.placeholder(tf.float32, [None, 10]) # 0-9 数字=> 10 classes
W_conv1 = weight_variable([5, 5, 3, 64])
b_conv1 = bias_variable([64])
x_image = tf.reshape(x, [-1,24,24,3])
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1)
h_pool1 = max_pool_2x2(h_conv1)
W_conv2 = weight_variable([5, 5, 64, 64])
b_conv2 = bias_variable([64])
h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2)
h_pool2 = max_pool_2x2(h_conv2)
W_fc1 = weight_variable([6 * 6 * 64, 256])
b_fc1 = bias_variable([256])
h_pool2_flat = tf.reshape(h_pool2, [-1, 6*6*64])
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1)
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
W_fc2 = weight_variable([256, 512])
b_fc2 = bias_variable([512])
h_fc2 = tf.nn.relu(tf.matmul(h_fc1_drop, W_fc2) + b_fc2)
h_fc2_drop = tf.nn.dropout(h_fc2, keep_prob)
W_fc3 = weight_variable([512, 128])
b_fc3 = bias_variable([128])
h_fc3 = tf.nn.relu(tf.matmul(h_fc2_drop, W_fc3) + b_fc3)
h_fc3_drop = tf.nn.dropout(h_fc3, keep_prob)
W_fc4 = weight_variable([128, 10])
b_fc4 = bias_variable([10])
y_conv=tf.nn.softmax(tf.matmul(h_fc3_drop, W_fc4) + b_fc4)
#指数衰减学习率
learning_rate = tf.train.exponential_decay(LEARNING_RATE_BASE,global_step,
LEARNING_RATE_STEP, LEARNING_RATE_DECAY, staircase=True)
#cross_entropy = -tf.reduce_sum(y*tf.log(y_conv)) #不使用正则化的交叉熵
reg = 0.1
cross_entropy = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=y_conv, labels=y)) \
+ tf.nn.l2_loss(W_fc1)*reg + tf.nn.l2_loss(W_fc2)*reg
#不同的优化方法测测效果
#train_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(cross_entropy,global_step=global_step)
train_step = tf.train.AdamOptimizer(learning_rate).minimize(cross_entropy,global_step=global_step)
#train_step = tf.train.AdagradOptimizer(learning_rate).minimize(cross_entropy,global_step=global_step)
correct_prediction = tf.equal(tf.argmax(y_conv,1), tf.argmax(y,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
sess = tf.Session()
sess.run(tf.global_variables_initializer())
tf.train.start_queue_runners(sess=sess)
for i in range(10000):
image_batch, label_batch = sess.run([images_train, labels_train])
label_b = np.eye(10, dtype=float)[label_batch] # one hot
train_step.run(feed_dict={x: image_batch, y: label_b, keep_prob: 0.8}, session=sess)
if i % 10 == 0:
step.append(i)
train_acc = accuracy.eval(feed_dict={
x: image_batch, y: label_b, keep_prob: 1.0}, session=sess)
print("step %d, training accuracy %g " % (i, train_acc))
print(sess.run(learning_rate))
training_accuracy.append(train_acc)
image_batch, label_batch = sess.run([images_test, labels_test]) #训练中不断测试
label_b = np.eye(10, dtype=float)[label_batch] # one hot
test_acc = accuracy.eval(feed_dict={
x: image_batch, y: label_b, keep_prob: 1.0}, session=sess)
print("test accuracy %g" % test_acc)
test_accuracy.append(test_acc)
end = time.clock() #结束时间
Running_time=float(end-start)/60 #计算分钟,
print('Running time: %g 分钟'% float(Running_time))
plt.plot(step, test_accuracy) #显示图形
plt.plot(step, training_accuracy)
plt.show()
writer = tf.summary.FileWriter("./tensorBoard",sess.graph)
writer.close()
四、结果
step 9990, training accuracy 0.7488
0.00060698984
test accuracy 0.7464
Running time: 27.4042 分钟 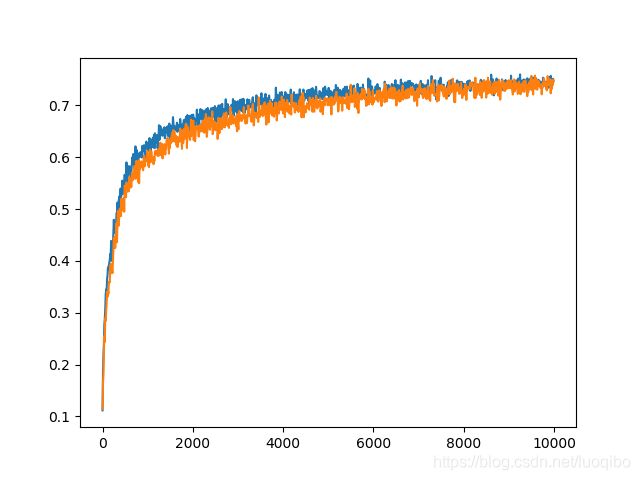
tensorBoard的可视化
网络搭建的不好,并没看出来什么,
