CNN中的卷积、反卷积与反池化
图示理解卷积、反卷积(Deconvolution)、上采样(UNSampling)与上池化(UnPooling)
使用三张图进行说明: 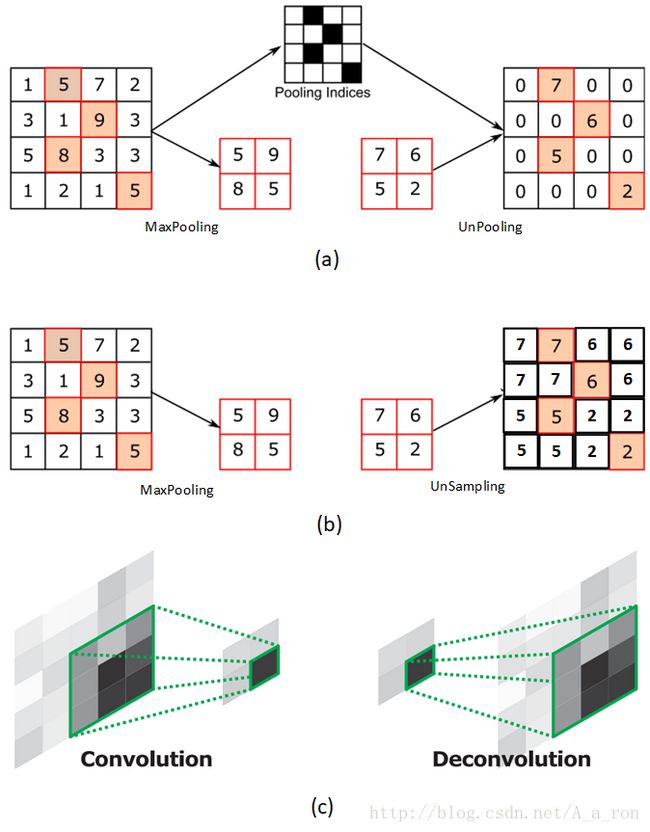
图(a)表示UnPooling的过程,特点是在Maxpooling的时候保留最大值的位置信息,之后在unPooling阶段使用该信息扩充Feature Map,除最大值位置以外,其余补0。
与之相对的是图(b),两者的区别在于UnSampling阶段没有使用MaxPooling时的位置信息,而是直接将内容复制来扩充Feature Map。从图中即可看到两者结果的不同。
图(c)为反卷积的过程,反卷积是卷积的逆过程,又称作转置卷积。最大的区别在于反卷积过程是有参数要进行学习的(类似卷积过程),理论是反卷积可以实现UnPooling和unSampling,只要卷积核的参数设置的合理。
1 反卷积DeConvolution
反卷积(Deconvolution)的概念第一次出现是Zeiler在2010年发表的论文Deconvolutional networks中,但是并没有指定反卷积这个名字,反卷积这个术语正式的使用是在其之后的工作中(Adaptive deconvolutional networks for mid and high level feature learning)。随着反卷积在神经网络可视化上的成功应用,其被越来越多的工作所采纳比如:场景分割、生成模型等。其中反卷积(Deconvolution)也有很多其他的叫法,比如:Transposed Convolution,Fractional Strided Convolution等等。
这篇文章的目的主要有两方面:
1. 解释卷积层和反卷积层之间的关系;
2. 弄清楚反卷积层输入特征大小和输出特征大小之间的关系。
1.1 卷积层回顾
卷积层大家应该都很熟悉了,为了方便说明,定义如下:
- 二维的离散卷积(N=2N=2)
- 方形的特征输入(i1=i2=ii1=i2=i)
- 方形的卷积核尺寸(k1=k2=kk1=k2=k)
- 每个维度相同的步长(s1=s2=ss1=s2=s)
- 每个维度相同的padding (p1=p2=pp1=p2=p)
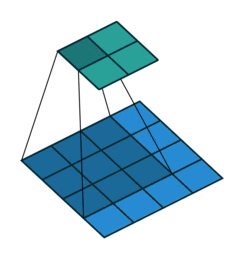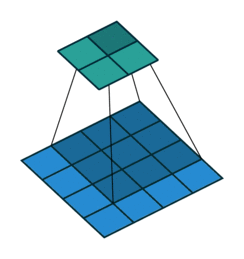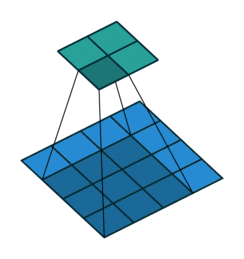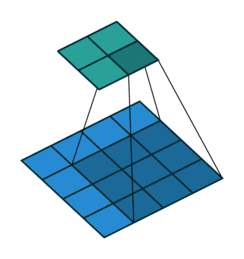
下图表示参数为 (i=5,k=3,s=2,p=1)(i=5,k=3,s=2,p=1) 的卷积计算过程,从计算结果可以看出输出特征的尺寸为 (o1=o2=o=3)。

下图表示参数为 (i=6,k=3,s=2,p=1)(i=6,k=3,s=2,p=1) 的卷积计算过程,从计算结果可以看出输出特征的尺寸为 (o1=o2=o=3)(o1=o2=o=3)。
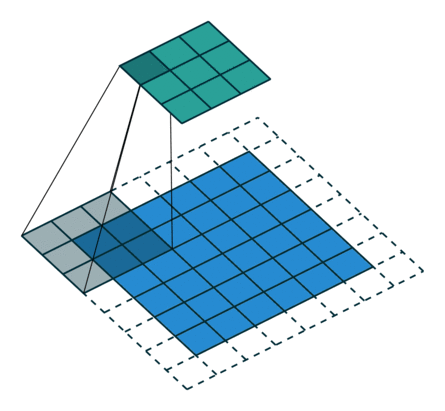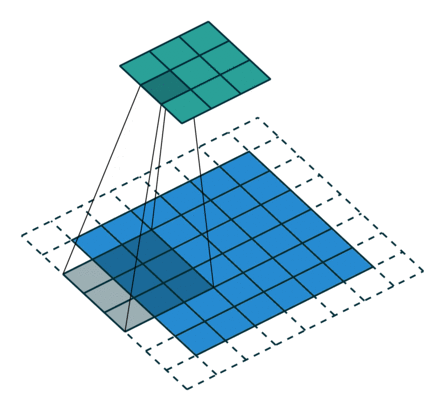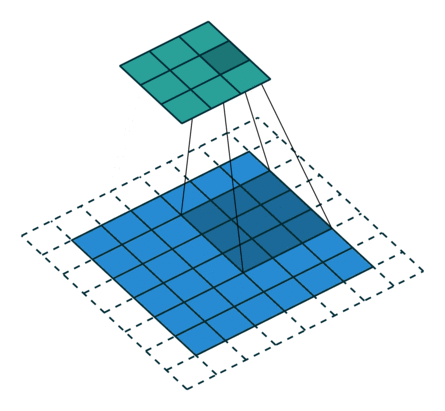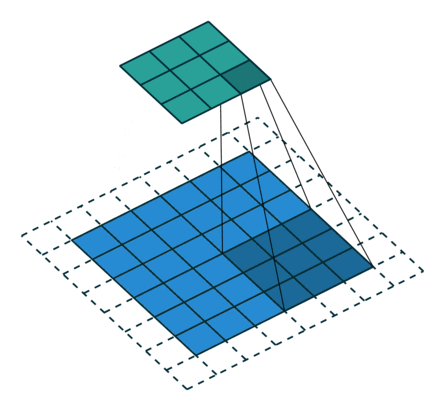
从上述两个例子我们可以总结出卷积层输入特征与输出特征尺寸和卷积核参数的关系为:
o=⌊i+2p−ks⌋+1.o=⌊i+2p−ks⌋+1.其中 ⌊x⌋⌊x⌋ 表示对 xx 向下取整。
1.2 反卷积层
卷积和矩阵相乘
考虑如下一个简单的卷积层运算,其参数为 (i=4,k=3,s=1,p=0)(i=4,k=3,s=1,p=0),输出 o=2o=2。
对于上述卷积运算,我们把上图所示的3×3卷积核展成一个如下所示的[4,16]的稀疏矩阵 CC, 其中非0元素 wi,jwi,j 表示卷积核的第 i 行和第 j 列。

我们再把4×4的输入特征展成[16,1]的矩阵 XX,那么 Y=CXY=CX 则是一个[4,1]的输出特征矩阵,把它重新排列2×2的输出特征就得到最终的结果,从上述分析可以看出卷积层的计算其实是可以转化成矩阵相乘的。值得注意的是,在一些深度学习网络的开源框架中并不是通过这种这个转换方法来计算卷积的,因为这个转换会存在很多无用的0乘操作,Caffe中具体实现卷积计算的方法可参考:Implementing convolution as a matrix multiplication。
这是一个toeplitz 托普利兹矩阵。
通过上述的分析,我们已经知道卷积层的前向操作可以表示为和矩阵CC相乘,那么 我们很容易得到卷积层的反向传播就是和C的转置相乘。
反卷积和卷积的关系
全面我们已经说过反卷积又被称为Transposed(转置) Convolution,我们可以看出其实卷积层的前向传播过程就是反卷积层的反向传播过程,卷积层的反向传播过程就是反卷积层的前向传播过程。因为卷积层的前向反向计算分别为乘 CC 和 CT,而反卷积层的前向反向计算分别为乘 CTCT 和 (CT)T(CT)T,所以它们的前向传播和反向传播刚好交换过来。,所以它们的前向传播和反向传播刚好交换过来。
,所以它们的前向传播和反向传播刚好交换过来。
反卷积计算
下图表示一个和上图卷积计算对应的反卷积操作,其中他们的输入输出关系正好相反。如果不考虑通道以卷积运算的反向运算来计算反卷积运算的话,我们还可以通过离散卷积的方法来求反卷积(这里只是为了说明,实际工作中不会这么做)。
同样为了说明,定义反卷积操作参数如下:
- 二维的离散卷积(N=2N=2)
- 方形的特征输入(i′1=i′2=i′i1′=i2′=i′)
- 方形的卷积核尺寸(k′1=k′2=k′k1′=k2′=k′)
- 每个维度相同的步长(s′1=s′2=s′s1′=s2′=s′)
- 每个维度相同的padding (p′1=p′2=p′p1′=p2′=p′)
下图表示的是参数为( i′=2,k′=3,s′=1,p′=2i′=2,k′=3,s′=1,p′=2)的反卷积操作,其对应的卷积操作参数为 (i=4,k=3,s=1,p=0)(i=4,k=3,s=1,p=0)。我们可以发现对应的卷积和非卷积操作其 (k=k′,s=s′)(k=k′,s=s′),但是反卷积却多了p′=2p′=2。通过对比我们可以发现卷积层中左上角的输入只对左上角的输出有贡献,所以反卷积层会出现 p′=k−p−1=2p′=k−p−1=2。通过示意图,我们可以发现,反卷积层的输入输出在 s=s′=1s=s′=1 的情况下关系为:
o′=i′−k′+2p′+1=i′+(k−1)−2p
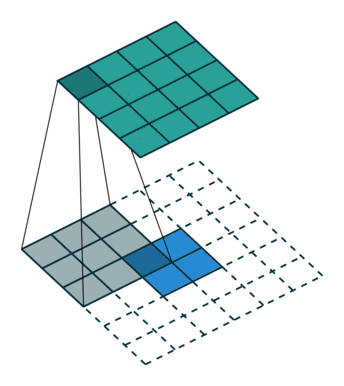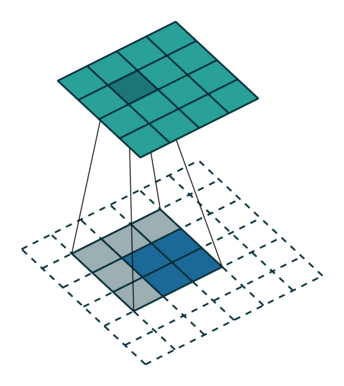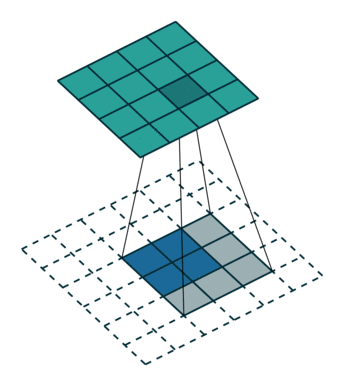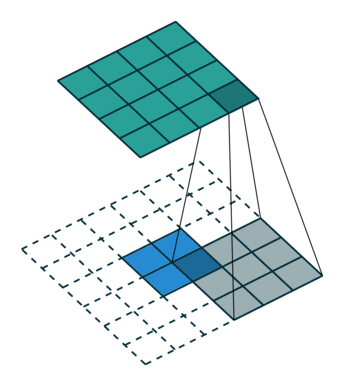
Fractionally Strided Convolution
反卷积有时候也被叫做Fractionally Strided Convolution,翻译过来大概意思就是小数步长的卷积。对于步长 s>1s>1的卷积,我们可能会想到其对应的反卷积步长 s′<1s′<1。 如下图所示为一个参数为 i=5,k=3,s=2,p=1i=5,k=3,s=2,p=1的卷积操作(就是第一张图所演示的)所对应的反卷积操作。对于反卷积操作的小数步长我们可以理解为:在其输入特征单元之间插入 s−1s−1 个0,插入0后把其看出是新的特征输入,然后此时步长 s′s′ 不再是小数而是为1。因此,结合上面所得到的结论,我们可以得出Fractionally Strided Convolution的输入输出关系为:
o′=s(i′−1)+k−2p

FCN中的使用
之所以说FCN中的反卷积操作不是原则意义上transposed convolution,是因为作者设置其中的学习率lr_mult为0,没有让该层学习。即卷积核是固定不变的。
下列为train.prototxt关于DeConv层的代码:
layer {
name: "upscore"
type: "Deconvolution"
bottom: "score_fr"
top: "upscore"
param {
lr_mult: 0
}
convolution_param {
num_output: 21
bias_term: false
kernel_size: 64
stride: 32
}
}2 TF中的使用
tf中的conv2d_transpose函数
上采样的过程也类似于一个卷积的过程,只不过在卷积之前将输入特征插值到一个更大的特征图然后进行卷积。下面举例子说明这个过程。
上采样利用的是conv2d_transpose函数,这个函数输入的有几个关键的参数,(value,filter,output_shape,strides,padding..)
这是这几个参数的解释:
Args:
filter是卷积核的大小,也是四维的[h,w,in_channel,out_channel],h和w是卷积核的大小,in_channel是输入特征图的数量,out_channel是输出特征图的数量。
output_shape是要上采样得到的特征图的大小,格式与value一致。
strides是步长,四维格式,分别对应value四个维度的步长。
我的输入图片是1*1248*384*3的图片,经过卷积网络之后得到的输出是1*39*12*2的特征图,我们要将这个输出特征首先上采样到pool4输出的大小(1*78*24*2)。选择的卷积核的大小是4*4*2*2,步长为[1,2,2,1]
抛开batch数量和特征图数量,我们只关注特征图的大小。首先我们将39*12的特征图插值得到H*W的大小,使的这个H*W的特征图在经过4*4-s-2的卷积核之后能够得到一个78*24的特征图,那么我们要插值得到的特征图到底是多大呢。根据卷积公式我们知道应该是宽为4+2*(78-1)和高为4+2*(24-1)的特征图,其中的4表示卷积核的宽和高,2是步长。在这个特征图上进行4*4的卷积就能够得到78*24的特征图,至此上采样完成。
3 Unpooling
也就是反池化,用的不是太多。参考论文Visualizing and Understanding Convolutional Networks,还有SegNet和DeconvNet
,实现代码可以看SegNet的实现。
简单原理:在池化过程中,记录下max-pooling在对应kernel中的坐标,在反池化过程中,将一个元素根据kernel进行放大,根据之前的坐标将元素填写进去,其他位置补0 。
目前Keras中只有UnSampling和反卷积的函数,还没有UnPooling的实现代码。
4 反卷积与UnPooling的可视化
对网络层进行可视化的结果: 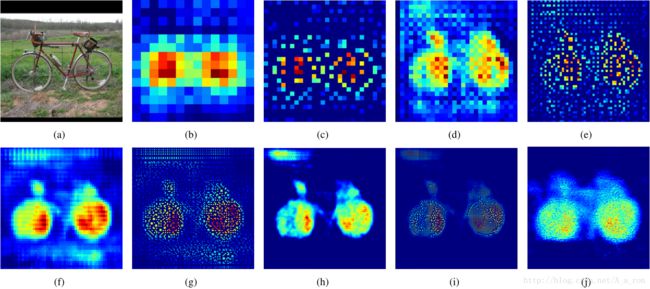
图(a)是输入层;图(b)是14*14反卷积的结果;图(c)是28*28的UnPooling结果;图(d)是28*28的反卷积结果;图(e)是56*56的Unpooling结果;图(f)是56*56反卷积的结果;图(g)是112*112 UnPooling的结果;图(h)是112*112的反卷积的结果;图(i)和图(j)分别是224*224的UnPooling和反卷积的结果。两者各有特点。
图像来自论文《Learning Deconvolution Network for Semantic Segmentation》
参考:
1.FCN中反卷积、上采样、双线性插值之间的关系
2.Transposed Convolution, Fractionally Strided Convolution or Deconvolution
http://buptldy.github.io/2016/10/29/2016-10-29-deconv/
3.更多关于卷积和反卷积的可视化理解
4.FCN全卷积网络上采样理解
5.反卷积(Transposed Convolution, Fractionally Strided Convolution or Deconvolution)
6.重点参看详细介绍:
如何理解深度学习中的deconvolution networks?
7.反卷积(Deconvolution)、上采样(UNSampling)与上池化(UnPooling)
https://blog.csdn.net/xiewenbo/article/details/80760658