android开发类库SparseArray与HashMap的研究
android系统建议我们用SparseArray
SparseArray内部主要使用两个一维数组来保存数据,一个用来存key,一个用来存value:
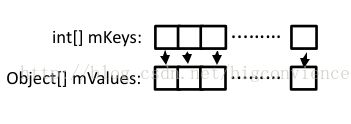
Hashmap是一个数组和链表的结合体

可以查看这篇技术文章,http://www.open-open.com/lib/view/open1402906434918.html
详细阐述了在内存使用、插入、检索、删除等常用操作的比较, 看归看,不要忘了手动实践一下!
代码1:
int MAX = 100000;
long start = System.currentTimeMillis();
HashMap hash = new HashMap();
for (int i = 0; i < MAX; i++) {
hash.put(i, String.valueOf(i));
}
long ts = System.currentTimeMillis() - start; 代码2:
int MAX = 100000;
long start = System.currentTimeMillis();
SparseArray sparse = new SparseArray();
for (int i = 0; i < MAX; i++) {
sparse.put(i, String.valueOf(i));
}
long ts = System.currentTimeMillis() - start; 我们分别在long start处和long ts处设置断点,然后通过DDMS工具查看内存使用情况。
代码1中,我们使用HashMap来创建100000条数据,开始创建前的系统内存情况为: 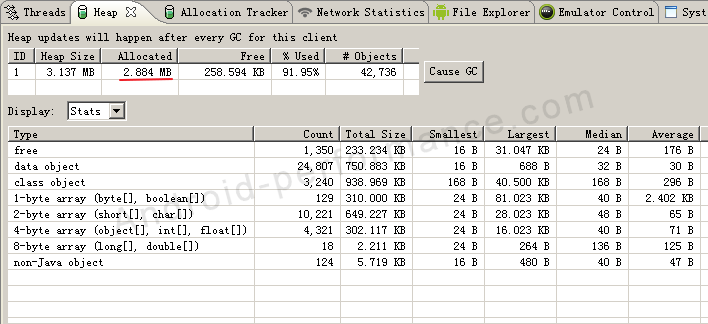
创建HashMap之后,应用内存情况为: 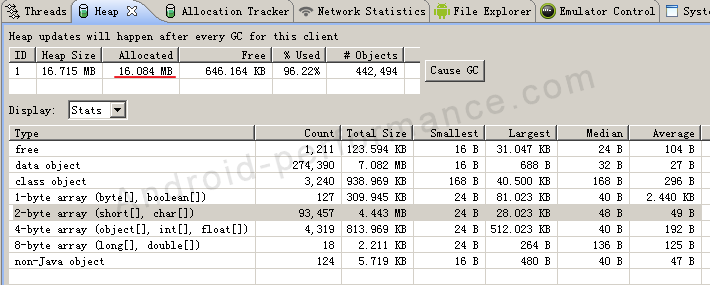 可见创建HashMap用去约 13.2M内存。
可见创建HashMap用去约 13.2M内存。
再看 代码2,同样是创建100000条数据,我们用SparseArray来试试,开始创建前的内存使用情况为: 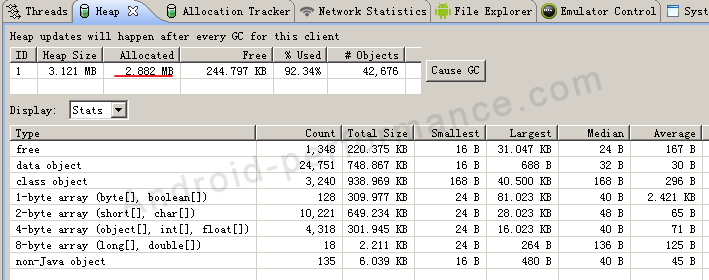
创建SparseArray之后的情况: 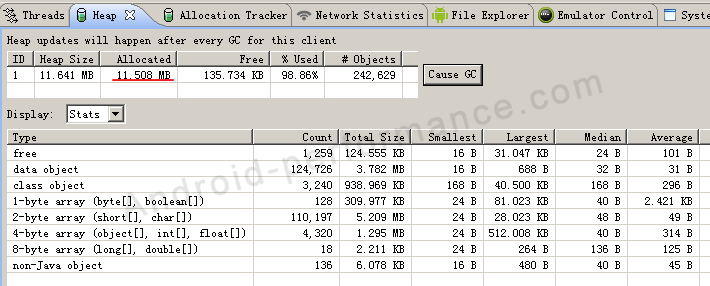 创建SparseArray共用去 8.626M内存。
创建SparseArray共用去 8.626M内存。
可见使用 SparseArray 的确比 HashMap 节省内存,大概节省 35%左右的内存。
我们再比较一下插入数据的效率如何,我们在加两段代码(主要就是把插入顺序变换一下,从大到小插入):
代码3:
int MAX = 100000;
long start = System.currentTimeMillis();
HashMap hash = new HashMap();
for (int i = 0; i < MAX; i++) {
hash.put(MAX - i -1, String.valueOf(i));
}
long ts = System.currentTimeMillis() - start; 代码4:
int MAX = 100000;
long start = System.currentTimeMillis();
SparseArray sparse = new SparseArray();
for (int i = 0; i < MAX; i++) {
sparse.put(MAX - i -1, String.valueOf(i));
}
long ts = System.currentTimeMillis() - start; 我们分别把这4代码分别运行5次,对比一下ts的时间(单位毫秒):
| # | 代码1 | 代码2 | 代码3 | 代码4 |
|---|---|---|---|---|
| 1 | 10750ms | 7429ms | 10862ms | 90527ms |
| 2 | 10718ms | 7386ms | 10711ms | 87990ms |
| 3 | 10816ms | 7462ms | 11033ms | 88259ms |
| 4 | 10943ms | 7386ms | 10854ms | 88474ms |
| 5 | 10671ms | 7317ms | 10786ms | 90630ms |
通过结果我们看出,在正序插入数据时候,SparseArray比HashMap要快一些;HashMap不管是倒序还是正序开销几乎是一样的;但是SparseArray的倒序插入要比正序插入要慢10倍以上,这时为什么呢?我们再看下面一段代码:
代码5:
SparseArray sparse = new SparseArray(3); sparse.put(1, "s1");
sparse.put(3, "s3");
sparse.put(2, "s2"); 我们在Eclipse的debug模式中,看Variables窗口,如图: 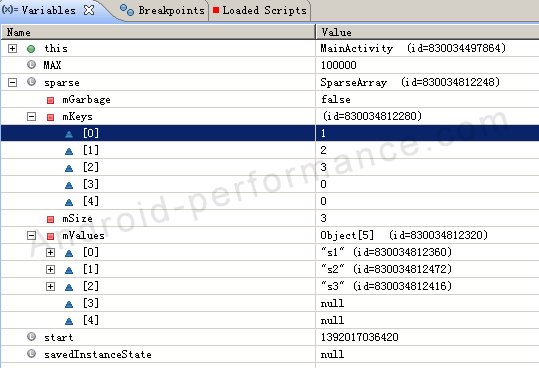
及时我们是按照1,3,2的顺序排列的,但是在SparseArray内部还是按照正序排列的,这时因为SparseArray在检索数据的时候使用的是二分查找,所以每次插入新数据的时候SparseArray都需要重新排序,所以代码4中,逆序是最差情况。
下面我们在简单看下检索情况:
代码5:
long start4search = System.currentTimeMillis();
for (int i = 0; i < MAX; i++) {
hash.get(33333); //针对固定值检索
}
long end4search = System.currentTimeMillis() - start4search;代码6:
long start4search = System.currentTimeMillis();
for (int i = 0; i < MAX; i++) {
hash.get(i); //顺序检索
}
long end4search = System.currentTimeMillis() - start4search;代码7:
long start4search = System.currentTimeMillis();
for (int i = 0; i < MAX; i++) {
sparse.get(33333); //针对固定值检索
}
long end4search = System.currentTimeMillis() - start4search;代码8:
long start4search = System.currentTimeMillis();
for (int i = 0; i < MAX; i++) {
sparse.get(i); //顺序检索
}
long end4search = System.currentTimeMillis() - start4search;表1:
| # | 代码5 | 代码6 | 代码7 | 代码8 |
|---|---|---|---|---|
| 1 | 4072ms | 4318ms | 3442ms | 3390ms |
| 2 | 4349ms | 4536ms | 3402ms | 3420ms |
| 3 | 4599ms | 4203ms | 3472ms | 3376ms |
| 4 | 4149ms | 4086ms | 3429ms | 3786ms |
| 5 | 4207ms | 4219ms | 3439ms | 3376ms |
代码9,我们试一些离散的数据。
//使用Foo为了避免由原始类型被自动封装(auto-boxing,比如把int类型自动转存Integer对象类型)造成的干扰。
class FOO{
Integer objKey;
int intKey;
}
...
int MAX = 100000;
HashMap hash = new HashMap();
SparseArray sparse = new SparseArray();
for (int i = 0; i < MAX; i++) {
hash.put(i, String.valueOf(i));
sparse.put(i, String.valueOf(i));
}
List keylist4search = new ArrayList();
for (int i = 0; i < MAX; i++) {
FOO f = new FOO();
f.intKey = i;
f.objKey = Integer.valueOf(i);
keylist4search.add(f);
}
long start4search = System.currentTimeMillis();
for (int i = 0; i < MAX; i++) {
hash.get(keylist4search.get(i).objKey);
}
long end4searchHash = System.currentTimeMillis() - start4search;
long start4search2 = System.currentTimeMillis();
for (int i = 0; i < MAX; i++) {
sparse.get(keylist4search.get(i).intKey);
}
long end4searchSparse = System.currentTimeMillis() - start4search2; 代码9,运行5次之后的结果如下:
表2:
| # | end4searchHash | end4searchSparse |
|---|---|---|
| 1 | 2402ms | 4577ms |
| 2 | 2249ms | 4188ms |
| 3 | 2649ms | 4821ms |
| 4 | 2404ms | 4598ms |
| 5 | 2413ms | 4547ms |
从上面两个表中我们可以看出,当SparseArray中存在需要检索的下标时,SparseArray的性能略胜一筹(表1)。但是当检索的下标 比较离散时,SparseArray需要使用多次二分检索,性能显然比hash检索方式要慢一些了(表2),但是按照官方文档的说法性能差异不是很大,不 超过50%( For containers holding up to hundreds of items, the performance difference is not significant, less than 50%.)
总体而言,在Android这种内存比CPU更金贵的系统中,能经济地使用内存还是上策,何况SparseArray在其他方面的表现也不算差(另外,SparseArray删除数据的时候也做了优化——使用了延迟整理数组的方法,可参考官方文档SparseArray,读者可以自行把代码9中的hash.get和sparse.get改成hash.remove和sparse.delete试试,你会发现二者的性能相差无几)。