数据分析面试【机器学习】总结之-----朴素贝叶斯常见面试题整理
阅读之前看这里:博主是正在学习数据分析的一员,博客记录的是在学习过程中一些总结,也希望和大家一起进步,在记录之时,未免存在很多疏漏和不全,如有问题,还请私聊博主指正。
博客地址:天阑之蓝的博客,学习过程中不免有困难和迷茫,希望大家都能在这学习的过程中肯定自己,超越自己,最终创造自己。
目录
-
- 1、朴素贝叶斯原理
- 2、朴素贝叶斯为什么“朴素naive”?
- 3、朴素贝叶斯属于生成式模型,与判别式模型(LR)区别是?
- 4、写出全概率公式&贝叶斯公式
- 5、最大似然估计和最大后验概率的区别?
- 6、朴素贝叶斯的工作流程是怎么样的
- 7、朴素贝叶斯的优缺点
- 8、“朴素”是朴素贝叶斯在进行预测时候的缺点,那么有这么一个明显的假设缺点在,为什么朴素贝叶斯的预测仍然可以取得较好的效果?
- 9、朴素贝叶斯中有没有超参数可以调?
- 10、你知道朴素贝叶斯有哪些应用吗?
- 11、你觉得朴素贝叶斯对异常值敏不敏感?
- 12、在估计条件概率P(X|Y)时出现概率为0的情况怎么办?
- 13、朴素贝叶斯是高方差还是低方差模型?
- 总结
1、朴素贝叶斯原理
朴素贝叶斯采用属性条件独立性的假设,对于给定的待分类观测数据 X X X,计算在 X X X出现的条件下,各个目标类出现的概率(即后验概率),将该后验概率最大的类作为 X X X所属的类。
而计算后验概率的贝叶斯公式为: p ( A ∣ B ) = [ p ( A ) × p ( B ∣ A ) ] / p ( B ) p(A|B) =[ p(A)\times p(B|A)]/p(B) p(A∣B)=[p(A)×p(B∣A)]/p(B)因为 p ( B ) p(B) p(B)表示观测数据X出现的概率,它在所有关于 X X X的分类计算公式中都是相同的,所以我们可以把 p ( B ) p(B) p(B)忽略,则 p ( A ∣ B ) = p ( A ) × p ( B ∣ A ) p(A|B)= p(A) \times p(B|A) p(A∣B)=p(A)×p(B∣A)。
关于具体的统计学知识参见我的另一篇博客内容:《商务与经济统计》学习笔记(四)–贝叶斯定理之理解
2、朴素贝叶斯为什么“朴素naive”?
朴素贝叶斯中的朴素可以理解为是“简单、天真”的意思,因为“朴素”是假设了特征之间是同等重要、相互独立、互不影响的,但是在我们的现实社会中,属性之间并不是都是互相独立的,有些属性也会存在性,所以说朴素贝叶斯是一种很“朴素”的算法。
因为在计算条件概率分布 p ( X ∣ Y ) p(X|Y) p(X∣Y)时,朴素贝叶斯做了一个很强的条件独立假设(当 Y Y Y确定时, X X X的各个分量取值之间相互独立)
3、朴素贝叶斯属于生成式模型,与判别式模型(LR)区别是?
生成式:生成模型是先从数据中学习联合概率分布,然后利用贝叶斯公式求得特征和标签对应的条件概率分布。
包含:朴素贝叶斯、 H M M HMM HMM、 G a u s s i a n s Gaussians Gaussians、马尔科夫随机场
判别式:判别模型直接学习条件概率分布,直观的输入什么特征就预测可能的类别。
包含: L R LR LR, S V M SVM SVM,神经网络, C R F CRF CRF, B o o s t i n g Boosting Boosting
- 朴素贝叶斯是生成模型,根据已有样本进行贝叶斯估计学习出先验概率P(Y)和条件概率P(X|Y),进而求出联合分布概率P(XY),最后利用贝叶斯定理求解P(Y|X),
而LR是判别模型,根据极大化对数似然函数直接求出条件概率P(Y|X); - 朴素贝叶斯是基于很强的条件独立假设(在已知分类Y的条件下,各个特征变量取值是相互独立的),而LR则对此没有要求;
- 朴素贝叶斯适用于数据集少的情景,而LR适用于大规模数据集。
4、写出全概率公式&贝叶斯公式

5、最大似然估计和最大后验概率的区别?

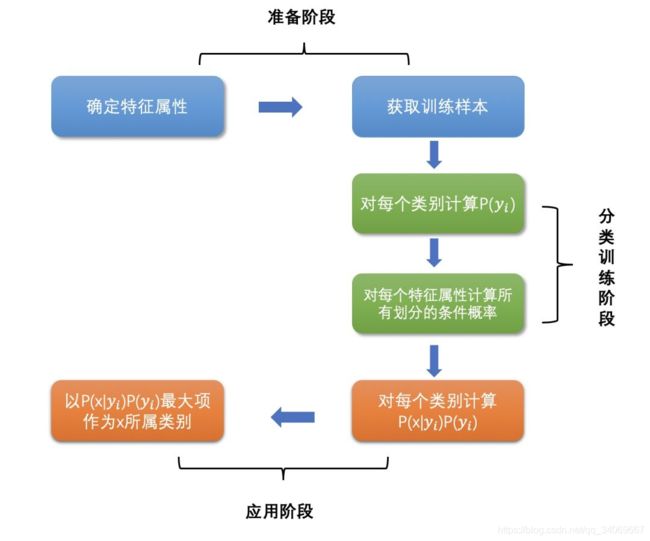
6、朴素贝叶斯的工作流程是怎么样的
回答:朴素贝叶斯的工作流程可以分为三个阶段进行,分别是准备阶段、分类器训练阶段和应用阶段。
- 准备阶段:这个阶段的任务是为朴素贝叶斯分类做必要的准备,主要工作是根据具体情况确定特征属性,并对每个特征属性进行适当划分,去除高度相关性的属性(如果两个属性具有高度相关性的话,那么该属性将会在模型中发挥了2次作用,会使得朴素贝叶斯所预测的结果向该属性所希望的方向偏离,导致分类出现偏差),然后由人工对一部分待分类项进行分类,形成训练样本集合。这一阶段的输入是所有待分类数据,输出是特征属性和训练样本。(这一阶段是整个朴素贝叶斯分类中唯一需要人工完成的阶段,其质量对整个过程将有重要影响。)
- 分类器训练阶段:这个阶段的任务就是生成分类器,主要工作是计算每个类别在训练样本中的出现频率及每个特征属性划分对每个类别的条件概率估计,并将结果记录。其输入是特征属性和训练样本,输出是分类器。这一阶段是机械性阶段,根据前面讨论的公式可以由程序自动计算完成。
- 应用阶段:这个阶段的任务是使用分类器对待分类项进行分类,其输入是分类器和待分类项,输出是待分类项与类别的映射关系。这一阶段也是机械性阶段,由程序完成。
7、朴素贝叶斯的优缺点
回答:朴素贝叶斯的优点有4个,分别是:
- 朴素贝叶斯模型发源于古典数学理论,有稳定的分类效率。
- 对缺失数据不太敏感,算法也比较简单,常用于文本分类。
- 分类准确度高,速度快。
- 对小规模的数据表现很好,能处理多分类任务,适合增量式训练,当数据量超出内存时,我们可以一批批的去增量训练(朴素贝叶斯在训练过程中只需要计算各个类的概率和各个属性的类条件概率,这些概率值可以快速地根据增量数据进行更新,无需重新全量计算)。
朴素贝叶斯的缺点有3个,分别是:
- 对训练数据的依赖性很强,如果训练数据误差较大,那么预测出来的效果就会不佳。
- 理论上,朴素贝叶斯模型与其他分类方法相比具有最小的误差率。
但是在实际中,因为朴素贝叶斯“朴素,”的特点,导致在属性个数比较多或者属性之间相关性较大时,分类效果不好。
而在属性相关性较小时,朴素贝叶斯性能最为良好。
对于这一点,有半朴素贝叶斯之类的算法通过考虑部分关联性适度改进。 - 需要知道先验概率,且先验概率很多时候是基于假设或者已有的训练数据所得的,这在某些时候可能会因为假设先验概率的原因出现分类决策上的错误。
8、“朴素”是朴素贝叶斯在进行预测时候的缺点,那么有这么一个明显的假设缺点在,为什么朴素贝叶斯的预测仍然可以取得较好的效果?
回答:
- 对于分类任务来说,只要各个条件概率之间的排序正确,那么就可以通过比较概率大小来进行分类,不需要知道精确的概率值(朴素贝叶斯分类的核心思想是找出后验概率最大的那个类,而不是求出其精确的概率)
- 如果属性之间的相互依赖对所有类别的影响相同,或者相互依赖关系可以互相抵消,那么属性条件独立性的假设在降低计算开销的同时不会对分类结果产生不良影响。
9、朴素贝叶斯中有没有超参数可以调?
回答:朴素贝叶斯是没有超参数可以调的,所以它不需要调参,朴素贝叶斯是根据训练集进行分类,分类出来的结果基本上就是确定了的,拉普拉斯估计器不是朴素贝叶斯中的参数,不能通过拉普拉斯估计器来对朴素贝叶斯调参。
10、你知道朴素贝叶斯有哪些应用吗?
朴素贝叶斯的应用最广的应该就是在文档分类、垃圾文本过滤(如垃圾邮件、垃圾信息等)、情感分析(微博、论坛上的积极、消极等情绪判别)这些方面,除此之外还有多分类实时预测、推荐系统(贝叶斯与协同过滤组合使用)、拼写矫正(当你输入一个错误单词时,可以通过文档库中出现的概率对你的输入进行矫正)等。
11、你觉得朴素贝叶斯对异常值敏不敏感?
朴素贝叶斯对异常值不敏感。所以在进行数据处理时,我们可以不去除异常值,因为保留异常值可以保持朴素贝叶斯算法的整体精度,而去除异常值则可能在进行预测的过程中由于失去部分异常值导致模型的泛化能力下降。
12、在估计条件概率P(X|Y)时出现概率为0的情况怎么办?
简单来说:引入λ,当λ=1时称为拉普拉斯平滑。
13、朴素贝叶斯是高方差还是低方差模型?
回答:朴素贝叶斯是低方差模型。(误差 = 偏差 + 方差)对于复杂模型来说,由于复杂模型充分拟合了部分数据,使得它们的偏差变小,但由于对部分数据过分拟合,这就导致预测的方差会变大。因为朴素贝叶斯假设了各个属性之间是相互的,算是一个简单的模型。对于简单的模型来说,则恰恰相反,简单模型的偏差会更大,相对的,方差就会较小。(偏差是模型输出值与真实值的误差,也就是模型的精准度,方差是预测值与模型输出期望的的误差,即模型的稳定性,也就是数据的集中性的一个指标)
总结
朴素贝叶斯的假设条件是“属性条件独立性”,这一假设很简单很朴素,它给我们省去了很多复杂的计算步骤,大大减少了贝叶斯分类器的计算量。但是它也有缺点存在,对于它的修正有半朴素贝叶斯、贝叶斯网络等模型。
参考:
李航《统计学习方法》第2版
数据挖掘面试题之:朴素贝叶斯
朴素贝叶斯算法面试问题汇总
—————————————————————————————————————————————————
博主码字不易,大家关注点个赞转发再走呗 ,您的三连是激发我创作的源动力^ - ^
