推荐 | 微软SAR近邻协同过滤算法解析(一)
SAR(Simple Algorithm for Recommendation)是一种快速,可扩展的自适应算法,可根据用户交易历史记录提供个性化推荐.
SAR本质是近邻协同过滤
它通过理解项目之间的相似性来推动,并向用户具有现有亲和力的项目推荐类似项目.
SAR is a fast scalable adaptive algorithm for personalized recommendations based on user transaction history and items description. The core idea behind SAR is to recommend items like those that a user already has demonstrated an affinity to. It does this by
1) estimating the affinity of users for items,
2) estimating similarity across items, and then
3) combining the estimates to generate a set of recommendations for a given user.
SAR模型的效果:
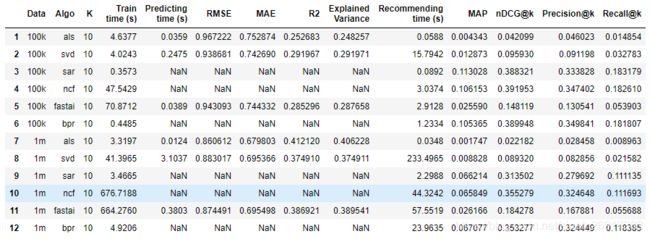
ALS可参考:练习题︱ python 协同过滤ALS模型实现:商品推荐 + 用户人群放大
文章目录
- 1 模型原理
-
- 1.1 SAR计算流程图
- 1.2 共现矩阵 ——co-occurence matrix
- 1.3 item相似矩阵 —— item similarity matrix
- 1.4 用户亲和力分数 —— affinity matrix
- 1.5 SAR的额外功能
- 2 案例一:简单版SAR使用
-
- 2.1 数据集的样子
- 2.2 训练/验证集分拆
- 2.3 SAR模型初始化
- 2.4 训练与预测
- 2.5 评估
- 2.6 独立预测
- 3 SAR的属性
-
- 3.1 **一些基本属性:**
- 3.2 **item发生的频次**
- 3.3 **item-2-item的共现矩阵C**
- 3.4 **affinity用户-item相关矩阵A**
- 3.5 **affinity用户-item相关矩阵A - 标准化**
- 3.6 recommendation score matrix - R矩阵
- 4 案例二:deep-dive SAR使用
-
- 4.1 Load data + Split the data
- 4.2 SAR初始化
- 4.3 模型训练+预测
- 4.4 评估
- 参考文献
1 模型原理
1.1 SAR计算流程图
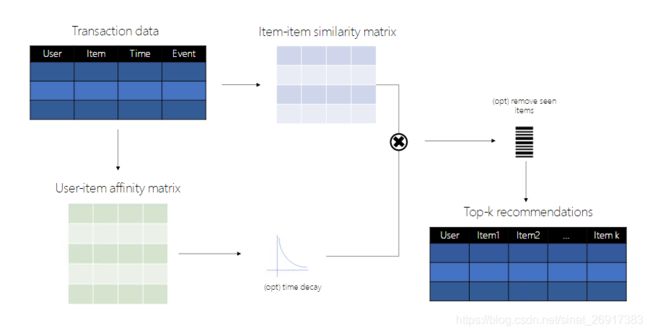
SAR 计算步骤:
- C C C矩阵,
co-occurence matrix,先计算item-to-item 的共现概率矩阵,矩阵的数值代表两个items同时出现在同一个用户的freq - S S S矩阵,
item similarity matrix(基于item共现概率矩阵)进行标准化(基于jaccard相似性,相当于i2i的一种加权平均, C C C矩阵的一次压缩/缩放) - A A A矩阵,
affinity matrix,用户-item的关联矩阵(通过排名或阅读,rating 或 viewing ) - S S S矩阵 * A A A矩阵 = R R R,
recommendation score matrix - 截取每个人的top-k结果
1.2 共现矩阵 ——co-occurence matrix
SAR基于项目到项目的共现数据来定义相似性.
共现定义为给定用户两个项目一起出现的次数.
我们可以将所有项目的共现表示为 m × m m\times m m×m(代表item个数)
共现矩阵 C C C具有以下特性:
- 对称的,所以 c i , j = c j , i c_{i,j} = c_{j,i} ci,j=cj,i
- 非负的: c i , j ≥ 0 c_{i,j} \geq 0 ci,j≥0
- 事件至少与同时发生的一样大.即,每行(和列)的最大元素位于主对角线上: ∀ ( i , j ) C i , i , C j , j ≥ C i , j \forall(i,j) C_{i,i},C_{j,j} \geq C_{i,j} ∀(i,j)Ci,i,Cj,j≥Ci,j.
1.3 item相似矩阵 —— item similarity matrix
S S S矩阵 = C C C矩阵的一次压缩/缩放
一旦我们具有共生矩阵,就可以通过根据给定度量重新缩放共现来获得项目相似性矩阵 :Jaccard, lift, and counts (就是计数,其实等于没改变,没压缩/缩放).
如果 c i i c_{ii} cii 和 c j j c_{jj} cjj 是 矩阵 C C C的第 i i i个 和 第 j j j个对角元素 , 则重新缩放选项为:
Jaccard: s i j = c i j ( c i i + c j j − c i j ) s_{ij}=\frac{c_{ij}}{(c_{ii}+c_{jj}-c_{ij})} sij=(cii+cjj−cij)cijlift: s i j = c i j ( c i i × c j j ) s_{ij}=\frac{c_{ij}}{(c_{ii} \times c_{jj})} sij=(cii×cjj)cijcounts: s i j = c i j s_{ij}=c_{ij} sij=cij
通常,使用
counts 作为相似性度量有利于可预测性,这意味着大多数时候都会推荐最受欢迎的项目.相反的.
lift 有利于发现性/意外发现:一个不太受欢迎但总体上受到一小部分用户青睐的项目更有可能被推荐.
Jaccard 是两者之间的妥协
1.4 用户亲和力分数 —— affinity matrix
SAR中的亲和度矩阵捕获每个用户与用户已与之交互的项之间关系的强度. SAR包含两个可能影响用户亲和力的因素:
它可以通过不同事件的不同加权来考虑关于用户项交互的类型的信息(例如,它可以权衡用户对特定项目评级比用户查看项目的事件更重的事件).
当用户项目事件发生时,它可以考虑关于的信息(例如,它可以折扣在遥远的过去发生的事件的价值.
将这些因素形式化为我们提供了用户项亲和关系的表达式:
a i j = ∑ k w k ( 1 2 ) t 0 − t k T a_{ij}=\sum_k w_k \left(\frac{1}{2}\right)^{\frac{t_0-t_k}{T}} aij=k∑wk(21)Tt0−tk
- 亲和力 a i j a_{ij} aij 代表第 i i i 用户和第 j j j个item是所有 k k k事件(包括第 i i i 用户和第 j j j个item) 的加权和。
- w k w_k wk 表示特定事件的权重,2个术语的权力反映了暂时打折的事件.
- ( 1 2 ) n (\frac{1}{2})^n (21)n 比例因子导致参数 T T T作为半衰期:事件 T T T单位在 t 0 t_0 t0之前将被赋予一半的权重作为发生的那些在 t 0 t_0 t0
- 对所有 n n n 用户和 m m m项重复此计算会产生 n × m n\times m n×m 矩阵 A A A…
通过将所有权重设置为等于1(有效忽略事件类型),或通过将半衰期参数 T T T设置为无穷大(忽略事务时间),可以获得上述表达式的简化
1.5 SAR的额外功能
SAR的优点:
- 高精度,易于训练和部署算法
- 快速训练,只需要简单的计数来构造用于预测时间的矩阵。
- 快速评分,只涉及相似性矩阵与亲和向量的乘法
弊端:
- 没有利用side infomations信息,所以是一个大问题,用户的属性、item的属性都没有
- 会形成一个m*m的矩阵,m是item的数量,吃内存
- SAR支持隐式评级方案,但它不预测评级
- 暂时无法增量训练,只能预测已知的,如果新用户/新item,就比较难推送
额外的功能点:
- 预测的时候,可以去除掉训练集中项目,意义在不建议再次由用户先前浏览的项目,详见:
model.recommend_k_items(test, remove_seen=True) - (flag to remove items seen in training from recommendation) - 时间衰退机制
time decay半衰期来看,时间越久既会被不重视一些
2 案例一:简单版SAR使用
冗长的代码不做额外赘述,具体可见:sar_movielens.ipynb,这边只挑核心的说。
2.1 数据集的样子
data = movielens.load_pandas_df(
size=MOVIELENS_DATA_SIZE
)
# Convert the float precision to 32-bit in order to reduce memory consumption
data['rating'] = data['rating'].astype(np.float32)
data.head()
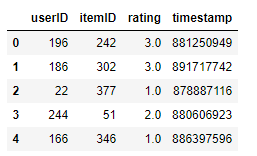
基本要素如下:<用户>,< item >,<得分>,<时间>,而且格式主要是pandas
2.2 训练/验证集分拆
train, test = python_stratified_split(data, ratio=0.75, col_user='userID', col_item='itemID', seed=42)
由于SAR生成建议基于用户偏好,所有用户在测试设置也必须存在于训练集。
对于这种情况,我们可以使用提供的python_stratified_split函数伸出一个百分比(在本例中25%)从每个用户的物品,但确保所有用户都在训练和测试数据集。
需要所有用户都在系统之中,所以拆分训练集、测试集的时候,确保每个人都在,然后可能某个人有10次行为,从中抽取x次作为测试集,10-x作为训练集
分拆函数为:
python_stratified_split(
data,
ratio=0.75,
min_rating=1,
filter_by='user',
col_user='userID',
col_item='itemID',
seed=42,
)
"""Pandas stratified splitter.
For each user / item, the split function takes proportions of ratings which is
specified by the split ratio(s). The split is stratified.
Args:
data (pd.DataFrame): Pandas DataFrame to be split.
ratio (float or list): Ratio for splitting data. If it is a single float number
it splits data into two halves and the ratio argument indicates the ratio of
training data set; if it is a list of float numbers, the splitter splits
data into several portions corresponding to the split ratios. If a list is
provided and the ratios are not summed to 1, they will be normalized.
seed (int): Seed.
min_rating (int): minimum number of ratings for user or item.
filter_by (str): either "user" or "item", depending on which of the two is to
filter with min_rating.
col_user (str): column name of user IDs.
col_item (str): column name of item IDs.
Returns:
list: Splits of the input data as pd.DataFrame.
"""
其中,还有min_rating=1最小rating,作为阈值。
train数据集:
2.3 SAR模型初始化
示例:
logging.basicConfig(level=logging.DEBUG,
format='%(asctime)s %(levelname)-8s %(message)s')
model = SAR(
col_user="userID",
col_item="itemID",
col_rating="rating",
col_timestamp="timestamp",
similarity_type="jaccard",
time_decay_coefficient=30,
timedecay_formula=True,
normalize=True
)
SAR函数初始化:
SAR(
col_user='userID',
col_item='itemID',
col_rating='rating',
col_timestamp='timestamp',
col_prediction='prediction',
similarity_type='jaccard',
time_decay_coefficient=30,
time_now=None,
timedecay_formula=False,
threshold=1,
normalize=False,
)
英文解释:
Args:
col_user (str): user column name
col_item (str): item column name
col_rating (str): rating column name
col_timestamp (str): timestamp column name
col_prediction (str): prediction column name
similarity_type (str): ['cooccurrence', 'jaccard', 'lift'] option for computing item-item similarity
time_decay_coefficient (float): number of days till ratings are decayed by 1/2
time_now (int | None): current time for time decay calculation
timedecay_formula (bool): flag to apply time decay
threshold (int): item-item co-occurrences below this threshold will be removed
normalize (bool): option for normalizing predictions to scale of original ratings
其中包括:
- similarity_type,从C矩阵 -> S矩阵的阶段,相似函数类型,similarity_type包括三种:Options for the metric include Jaccard, lift, and counts
- col_timestamp,时间衰减
- time_decay_coefficient,时间衰减参数
- time_now,当下时间,确认时间衰减
- threshold,共现C矩阵,低频进行移除
- normalize,亲和力矩阵A是否标准化
2.4 训练与预测
训练代码:
with Timer() as train_time:
model.fit(train)
print("Took {} seconds for training.".format(train_time.interval))
整体数据集预测:
with Timer() as test_time:
top_k = model.recommend_k_items(test, remove_seen=True)
print("Took {} seconds for prediction.".format(test_time.interval))
test格式与train格式一样:
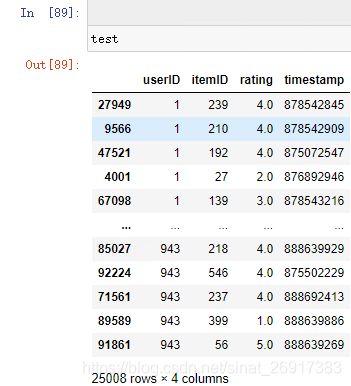
此时预测recommend_k_items表示为::
model.recommend_k_items(test, top_k=10, sort_top_k=True, remove_seen=False)
Args:
test (pd.DataFrame): users to test,pandas即可
top_k (int): number of top items to recommend,top items的排名
sort_top_k (bool): flag to sort top k results,是否排序
remove_seen (bool): flag to remove items seen in training from recommendation,移除训练中推荐的item,把一些之前没有推荐的引申出来
Returns:
pd.DataFrame: top k recommendation items for each user
其中几个注意,
remove_seen就是移除训练中推荐的item,把一些之前没有推荐的引申出来。
适用场景是,推荐你没有看到过的内容。
2.5 评估
我们根据reco_utils中的python_evaluate模块提供的几个常见排名指标来评估SAR的执行情况。
我们将考虑使用SAR计算出的每个用户前k个产品的平均平均精度(MAP)、归一化累积收益(NDCG)、精度和召回率。
每个评估方法都指定用户、产品和评级列名称。
eval_map = map_at_k(test, top_k, col_user='userID', col_item='itemID', col_rating='rating', k=TOP_K)
eval_ndcg = ndcg_at_k(test, top_k, col_user='userID', col_item='itemID', col_rating='rating', k=TOP_K)
eval_precision = precision_at_k(test, top_k, col_user='userID', col_item='itemID', col_rating='rating', k=TOP_K)
...
2.6 独立预测
# Now let's look at the results for a specific user
user_id = 876
ground_truth = test[test['userID']==user_id].sort_values(by='rating', ascending=False)[:TOP_K]
prediction = model.recommend_k_items(pd.DataFrame(dict(userID=[user_id])), remove_seen=True)
pd.merge(ground_truth, prediction, on=['userID', 'itemID'], how='left')
输出:
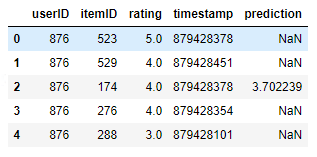
输入某个特殊用户编号,输出对应的内容
其中,此时测试数据样式为:
以上,我们看到,前面通过模型top-k推荐得到的测试集的最高评分物品被调整,而其他物品未变。离线评估算法很困难,因为此时测试集仅包含历史记录,也不能代表用户在所有物品范围内的实际偏好。对于这一问题,我们也可以通过其他算法 (1) 或使用 hyper-parameters (2) 进行优化。
实际应用中,多为混合集成的推荐系统,比如 UserCF + ItemCF、ItemCF + Content-based 或其他一些独特的优化方式。关于这一部分,在 Aggarwal 的《推荐系统》中有详细描述。 hyper-parameters:是机器学习 (ML, Machine Learning) 的概念,在 ML 中,已经设置的参数称为
hyper-parameters。按照我个人理解,这里原文想说的是通过 对增量数据进行机器学习 来持续优化模型。
3 SAR的属性
两个官方例子中:
from reco_utils.recommender.sar import SAR
from reco_utils.recommender.sar.sar_singlenode import SARSingleNode
两者是同一程序:from .sar_singlenode import SARSingleNode as SAR
具体属性可见:sar_singlenode.py
3.1 一些基本属性:
# 模型item的编号 ; user的编号
len(model.item2index),model.user2index
# items的数量
model.n_items
# 模型中人的个数
model.n_users
# 评分最高值
model.rating_max
# 评分最低值
model.rating_min
# 相似性类型 : jaccard - 初始化SAR中控制,相关矩阵`affinity matrix` 的生成
model.similarity_type
3.2 item发生的频次
model.item_frequencies
# array([126., 69., 66., ..., 1., 1., 1.])
3.3 item-2-item的共现矩阵C
# 模型item-item之间的相似性
# (1649, 1649)
model.item_similarity
3.4 affinity用户-item相关矩阵A
# 常规affinity矩阵 (943, 1649)
# U is the user_affinity matrix The co-occurrence matrix is defined as :math:`C = U^T * U`
model.user_affinity.todense()
这个矩阵比较大,是稀疏矩阵,具体用法:scipy.sparse、pandas.sparse、sklearn稀疏矩阵的使用
3.5 affinity用户-item相关矩阵A - 标准化
# 常规affinity矩阵 (943, 1649)
# U is the user_affinity matrix The co-occurrence matrix is defined as :math:`C = U^T * U`
model.normalize # True 是否标准化
model.unity_user_affinity.todense()
这个矩阵比较大,是稀疏矩阵,具体用法:scipy.sparse、pandas.sparse、sklearn稀疏矩阵的使用
3.6 recommendation score matrix - R矩阵
这里没有R矩阵,
需要 S S S矩阵 * A A A矩阵 = R R R,recommendation score matrix
4 案例二:deep-dive SAR使用
冗长的代码不做额外赘述,具体可见:sar_deep_dive.ipynb,这边只挑核心的说。
4.1 Load data + Split the data
data = movielens.load_pandas_df(
size=MOVIELENS_DATA_SIZE,
header=['UserId', 'MovieId', 'Rating', 'Timestamp'],
title_col='Title'
)
# Convert the float precision to 32-bit in order to reduce memory consumption
data.loc[:, 'Rating'] = data['Rating'].astype(np.float32)
data.head()
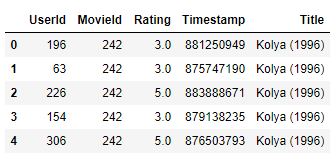
切分数据:
train, test = python_stratified_split(data, ratio=0.75, col_user=header["col_user"], col_item=header["col_item"], seed=42)
4.2 SAR初始化
# set log level to INFO
logging.basicConfig(level=logging.DEBUG,
format='%(asctime)s %(levelname)-8s %(message)s')
header = {
"col_user": "UserId",
"col_item": "MovieId",
"col_rating": "Rating",
"col_timestamp": "Timestamp",
"col_prediction": "Prediction",
}
model = SARSingleNode(
similarity_type="jaccard",
time_decay_coefficient=30,
time_now=None,
timedecay_formula=True,
**header
)
跟之前的案例初始化差不多,其中主要属性为:
SARSingleNode(
col_user='userID',
col_item='itemID',
col_rating='rating',
col_timestamp='timestamp',
col_prediction='prediction',
similarity_type='jaccard',
time_decay_coefficient=30,
time_now=None,
timedecay_formula=False,
threshold=1,
normalize=False,
)
In this case, for the illustration purpose, the following parameter values are used:
| Parameter | Value | Description |
|---|---|---|
similarity_type |
jaccard |
Method used to calculate item similarity. 其他还可以是:Jaccard, lift, and counts |
time_decay_coefficient |
30 | 衰减时间,Period in days (term of T T T shown in the formula of Section 1.2) |
time_now |
None |
当下时间,Time decay reference. |
timedecay_formula |
True |
Whether time decay formula is used. |
4.3 模型训练+预测
# train
model.fit(train)
# 预测
top_k = model.recommend_k_items(test, remove_seen=True)
# 展示
top_k_with_titles = (top_k.join(data[['MovieId', 'Title']].drop_duplicates().set_index('MovieId'),
on='MovieId',
how='inner').sort_values(by=['UserId', 'Prediction'], ascending=False))
display(top_k_with_titles.head(10))
4.4 评估
# all ranking metrics have the same arguments
args = [test, top_k]
kwargs = dict(col_user='UserId',
col_item='MovieId',
col_rating='Rating',
col_prediction='Prediction',
relevancy_method='top_k',
k=TOP_K)
eval_map = map_at_k(*args, **kwargs)
eval_ndcg = ndcg_at_k(*args, **kwargs)
eval_precision = precision_at_k(*args, **kwargs)
eval_recall = recall_at_k(*args, **kwargs)
计算的指标如下:
Model:
Top K: 10
MAP: 0.095544
NDCG: 0.350232
Precision@K: 0.305726
Recall@K: 0.164690
参考文献
1 推荐系统 SAR 模型
2 sar_movielens.ipynb
3 sar_deep_dive.ipynb
4 核心代码是:sar_singlenode.py
5 【翻译】微软SAR——推荐系统实践笔记