4. 文件组织管理与存储类型
C++文件组织
C++允许鼓励程序员将组件函数放在独立的文件中,可以单独编译这些文件,然后把他们链接起来(通常C++编译器既能编译程序,也能管理链接器)。如果一个更改,重新编译这一个,再重新链接。
多文件组织策略
- 头文件:包含结构的声明和使用这些结构的函数的原型
- 源代码文件:结构有关的函数代码
- 源代码文件:调用与结构相关的函数的代码
注意:
- 请不要把函数定义或变量声明放在头文件,可能可行,但文件一多,重定义的可能性越大
//pch.h
int a;
//cpp1
#include "pch.h"
void UseA1() { a = 1; }
//cpp2
#include "pch.h"
void UseA2() { a = 1; }
//cpp3
#include "pch.h"
void UseA3() { a = 1; }
报错类似于:
![]()
格式:错误 ***** 已经在 ****.obj 中定义
原因:报错的原因就是有三个个CPP,各自生成自己的obj,那么在查找符号的时候,都能发现对方那里也有一个变量a
所以,如果你能保证你的头文件只被包含一次,那么可以在其中在头文件里面定义;或者在一个文件中,使用extern,让其他文件使用
下面式头文件中常包含的内容
- 函数原型
- #define 或 const 定义的符号常量
- 结构与类的声明
- 模板声明
- 内联函数
头文件的管理
#include- 如果文件名在 <> 尖括号中,则C++编译器将在存储标准头文件的主机系统的文件系统中查找
- 如果文件名在 " " 双引号中,则C++编译器首先查找当前工作目录或源文件目录(或其他目录,这取决于编译器),如果没有找到,将在标准位置查找,因此包含自己的头文件时,用双引号
包含规则:同一个文件只能将同一个文件包含一次
如何避免:基于C++预编译器指令 #ifndef ( if not defined)
#ifndef COORDIN_H_
...
#endif
上面代码意义:当且仅当没有使用预处理编译器指令#define定义的名称 COORDIN_H_时,才处理两个#之间的内容
#ifndef COORDIN_H_
#define COORDIN_H_
//放入你需要包含的文件
...
#endif
通常 #define 语句类似 #define min 0
但只要将#define用于名称,就足以完成该名称的定义
#define COORDIN_H_
上面代码过程:
首先编译器遇到这个文件,发现 COORDIN_H_没有定义,处理两个#之间的内容,并读取 #define COORDIN_H_这一行
(如果同一个文件遇到其他包含coordin.h的代码,编译器就知道COORDIN_H_已经被定义,跳到#endif后面一行)
多个库的链接
C++允许程序员以合适的方式实现名称修饰(解决由于程序实体的名字必须唯一而导致的问题的一种技术),不同编译器创建的二进制模板(对象代码文件)很可能无法正确的链接,因为两个编译器为同一个函数生成不同的修饰名称,无法调用另一个编译器生成的函数定义匹配。
总结:链接编译模块时,请确保所有对象文件或库由同一编译器生成的
存储类型

一. 自动存储
1. 自动变量
分配内存时间:执行变量所属的函数代码块时分配内存
作用域:为其声明的位置,函数结束,变量消失
注:假如一个内部代码块定义了一个与外部代码块名字一样的,当执行到内部代码时,新定义隐藏了以前的定义,也就是使用的是新定义的
auto关键字
1)作用
- 显式地指出变量为自动存储
- 自动类型推断
在以前的用于显式地指出变量为自动存储,但这个几乎程序员不用,因此赋予新含义现在用于自动类型推断
保留的原因:又要兼容老版本,避免现有代码非法
注:自动推动只能用于单值厨师胡,而不能用初始化列表
2. 寄存器变量
建议CPU寄存器来存储自动变量,提高访问速度
register关键字
1)作用
以前会提示这个变量用得很多,编译器可以对其做特殊处理。但硬件编译器复杂化,现在这种提示作用失去了,关键字只显式地指出变量为自动存储,
保留的原因:又要兼容老版本,避免现有代码非法
二. 静态存储
程序整个执行都存在
关键字static
1)非类的static
- static 修饰的局部变量,指出该变量是无链接的静态变量,与局部变量区别是他一直存在,他只初始化一次,再调用不会变回去(链接性是可被访问的范围)
- static 修饰的全局变量,只能在当前文件访问,假如另一文件有相同名字的,会将static修饰的全局变量隐藏
- static 修饰的函数,只能在当前文件访问
2)类的static
| 格式 | 使用 | 数据初始化 / 函数定义 | 属于 | |
|---|---|---|---|---|
| 静态数据成员 | static int a | 类名: :a / 对象名 . a | 类外初始化 | 类的一部分 |
| 静态函数成员 | static int a() | 类名: :a() / 对象名 . a() | 类内外都可以定义 | 类的一部分 |
| 普通数据成员 | int a | 非静态数据成员必须与特定对象相对 | 类内外都可以初始化 | 对象一部分 |
| 普通函数成员 | int a() | 非静态函数成员必须与特定对象相对 | 类内外都可以定义 | 对象一部分 |
关键字extern
为了能扩展本文件作用域或者在其他文件中可以使用
1)extern 是个声明
1.extern 作用于外部变量与函数原型(函数本身就是外部)
2.告诉编译器这个全局变量或函数定义在本文件或者文件中定义
2)加不同文件的extern作用域变化
| 在定义全局变量或函数的文件使用extern | 在非定义全局变量或函数的其他文件使用extern | |
|---|---|---|
| extern +全局变量 | 扩展变量的作用域 由【定义到本文件结束】变成【 声明到本文件结束】 | 扩展该变量的作用域到本文件 那么这个文件中的生效范围【从声明到本文件结束】 |
| extern+函数原型=函数原型 | 扩展该函数作用域 由【定义到本文件结束】变成【 声明到本文件结束】 | 扩展该函数的作用域到本文件 那么这个文件中的生效范围【从声明到本文件结束】 |
3)extern检测
1.首先检测本文件中有没有这个外部变量或者函数,有就extern本行开始作用
2.没有就去其他文件找外部变量或者函数,有就扩展到本文件extern本行开始
4)应用
1.一个文件中主要是为了扩展作用域,比如你定义的外部变量在一个滞后的位置,但你想在定义的前面用,就是前面做声明就能合法使用,函数同理
2.多个文件中也是为了扩展作用域到本文件,多文件用同一个名字的外部变量,不能分别定义;程序链接时会出现 重复定义的错误
5)如何防止外部变量或函数随便被其他文件引用
如上面的讲述不难得到,在定义全局变量函数的时候 +static (静态外部变量,函数),只能在本文件中使用,其他文件不许使用
最后一句:const全局变量的链接性为内部,这里与使用static一致
(附)关于链接性问题
| 链接性 | 可访问的 | 定义 | 需求关键字 |
|---|---|---|---|
| 无链接性 | 当前函数访问 | 函数内 | 无 |
| 内部链接性 | 只能在当前文件访问 | 函数外 | 使用static |
| 外部链接性 | 其他文件可访问 | 函数外 | 其他文件访问,使用extern关键字 |
- 没有显式地初始化静态变量,编译器将设置为0
- static 修饰的局部变量,指出该变量时无链接的静态变量,与局部变量区别是他一直存在,他只初始化一次,再调用不会变回去
- C++的单定义规则,变量只能定义一次,其他文件访问,使用extern关键字
- static 修饰的全局变量,假如另一文件有相同名字的,会将他隐藏
- 一个链接性为外部的,根据单定义规则,只能在一个文件中声明,其他文件extern引用,但是const 定义的量可以放在头文件中,说明他的链接性为内部,是他声明他文件私有的,其他文件不能共享,假如需要更改const的链接性为外部,需要extern关键字来覆盖:extern const int a=1;
报错
![]()
这是由于我删除了pch.cpp的原因
(附)函数链接性
函数自动为静态,外部链接性
要设置为内部链接 static+原型和定义
何寻找函数
static 本文件查找
非static 所有文件查找(找到两个相同的定义 报错)
然后库里面找 (库里面找到一样的,使用程序员手写的那个)
三.动态存储
new 操作符是由语言内建的,就像sizeof那样,不能被改变意义,做相同的事情,下面两件
- 它调用 operator new 分配足够的内存
void *operator new(size_t size)
直接调用 operator new 返回指针,指向一块足够容纳对象的内存
int *p=operator new(sizeof(int));
- 调用 constructor 为分配的内存设置初值
string *a = new string(''666'');
void *memory //取得原始内存
=operator new(sizeof(string)) //放置string对象
call string::string("666") //调用constructor 对象初始化
on *memory;
string *ps=static_cast<string*>(memory);
1)指针与new
- 编译与运行阶段的决策
编译阶段:编译器将程序组合起来
运行阶段:程序正在运行时
面对过程偏向于编译阶段决策,就好像假期去哪个景点,预先设定好行程
面对对象偏向于运行阶段决策,就好像假期去哪个景点,取决于当时的天气等 - 例子
比如C++声明数组需要指定长度
面对过程偏向于编译阶段决策,为了安全必须包含最大值,但是可能会造成空间浪费
面对对象偏向于运行阶段决策,我们可以推迟到运行阶段再决定数组大小,C++采用关键字new来请求正确数量的内存和指针来跟踪新分配的内存位置
为什么我们不直接使用指针来操作空间,不需要new?
你没有申请,这个是不允许的
2)常规变量与指针变量
常规变量找地址: 如 a 运用地址运算符 &a就能知道地址,使用常规变量,值是指定的量,而地址为派生量
指针变量找地址:指针名是地址,*运算被称为间接值或解除引用,将其运用于指针,可以得到该地址处存储的值(C++根据上下文来确定是乘法还是解除引用),地址是指定的量,而值为派生量
C++创建指针时计算机给指针的是用来存储地址的内存,而不是分配地址指向数据的内存,指针指向不同长度的类型时,一般来说要2字节或4字节,根据系统来定
3)指针与引用
void Init(int* &ht1)
{
ht1 = (int* )malloc(sizeof(int));
}
void InitNoR(int* ht1)
{
ht1 = (int*)malloc(sizeof(int));
}
int main()
{
int* ht;
Init(ht);
}
int* &ht1
优先级*& 同级结合结合方向从右到左,&先结合,是个引用 int* &ht 也就是int* 型的引用 int* 是指向int的指针,连起来就是指向 int的指针的引用
引用必须声明时将其初始化,而不能像指针那样,先声明再赋值
int &a=b int* const c=&b a与c的作用相同
在C中关于引用的性质:如果程序中声明b是a的引用,实际上是为b开辟了一个指针型的存储单元,其中存放变量a的地址,输出b时,就输出b所指向变量a的值,相当于 *b 。引用的实质是一个 指针常量 (比如 const int *p)不能改变指针指向不能改变里面存储的内存地址
int* &ht1 与 int* ht1的区别,造成 int* ht1不能初始化的原因
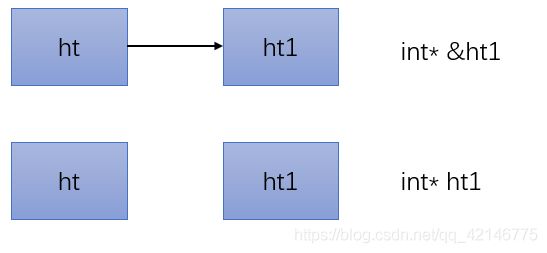
也就是说
对于int* &ht1 是两个相关联的 对于ht1 进行mallco就是对ht mallco
对于int* ht1 是两个不相关联的 对于ht1 进行mallco,并没有对ht mallco,所以会报错说,使用未初始化的指针
一定要在应用之前,将指针初始化为一个确定的,适当的地址(这是关于使用指针的金科玉律)
4)指针的初始化两种方式:
- 初始化为变量的地址(变量是在编译时分配有名称的内存)
- 运行阶段分配未命名的内存以存储值
① mallco
② new 运行阶段为一个类型的值分配未命名的内存以存储值,并使用指针访问,还要需要new告诉哪种类型分配,new找到一个正确的内存块,返回该内存地址给指针变量
虽然地址只是数字,并没有提供类型或长度,只指出了对象存储地址开始的地方,
但我们通过 int * a=new int; 知道 * a是4个字节int,cout的时候就知道怎么读取了
int A=3;
int *nA=new int;
*nA=3;
// nA是用来访问的指针
// new int new找到一个正确的内存块,返回该内存地址给指针变量
- A和nA分配的内存块不同,A是栈区,nA是堆区或自由存储区
- new 与delete 配对使用,否则发生内存泄露
4)创建使用动态数组
//创建动态数组
int i;
int* a = new int[5] {1,2,3,4,5};
//必须在类型名后加上方括号,其中包含元素数目,意思就是创建5个int大小的数组,用指针变量a来访问,并指向第一个
//使用动态数组两种方法
1.
for (i = 0; i < 5; i++)
cout << a[i] << " ";
2.
for (i = 0; i < 5; i++)
{
cout << a[0]<<" ";
a++;
}
delete[] a;
注:动态的数组 用列表初始化;一个使用圆括号
int* a = new int[5] {1,2,3,4,5};
int *a = new int (1);
1. 那么这与普通数组a[5]的不同呢
编译器不能跟踪new出来的数组分配情况,所以必须让运行时程序来跟踪,的确,程序确实跟踪了,以便 delete [ ] 运算符能够正确地释放这些内存,但信息不能用,所以sizeof无法来确定动态分配地数组包含地字节数
- 我们可以像数组一样来使用
- 也可以进行指针算术 a= a+1;cout<
- 数组不可以进行指针运算
2. new 二维数组
int* a = new int[i*j];
cout<<*(a+m*j+n); //相当于输出 a[m][n]
5)new的变体
称为定位new运算符,让你能够指定要使用的位置,使用这种特性来设置其内存管理规程,处理需要通过特定地址进行访问的硬件或在特定位置创建对象
注:其实这里调用的是特殊版本的 operator new 称为 placement new 为了在以及分配好的内存上面,构造对象
void * operator new(size_t,void *location)
{
return location;
}
使用
char a;
int *p1;
p1=new(&a) int[20]; // 从 a 变量的地址开始,使用20个int类型的空间
() 括号里面需要地址参数
注:
- 定位new运算符 使用他传递过来的地址,他不跟踪哪些内存单元被使用,也不查找未使用的内存块
int *p2;
p2=new (&a) int[20]; //这样会覆盖上面代码写入的内容
-
delete只能用于常规new运算符分配的空间,所以定位new运算符不需要delete取出来,但是假如上述的 char a 是new分配的,可以使用常规的delete来释放
-
对于类里面的定位new运算符来为对象分配空间,必须保证他的析构函数被调用,如何调用?显式调用析构函数
产生于heap , 要调用constructor 使用new ,不要调用constructor 使用operator new,如果想要自己写一个内存分配方式,自己写一个 operator new
产生于已分配的 ,调用 placement new