Python爬取六国家(地区)最流行的股票并保存到excel的不同的工作表中
问题
爬取“英为财情”网站中最活跃股票数据。
网站url:https://cn.investing.com/equities/most-active-stocks
爬取括号内指定6个热门数据(中国、中国香港、新加坡、美国、英国和德国),保存在excel的一个工作簿中,但要对不同的国家保存为不同的工作表。
打开网站后页面显示如下
网页分析
查看网页的源代码后发现股票名都在class为left bold plusIconTd elp的td下的a标签的text文本中
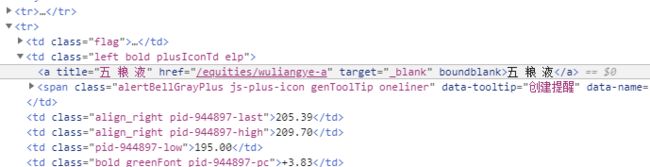
当我们选择新加坡的时候,URL变为https://cn.investing.com/equities/most-active-stocks?country=singapore

所以只需要修改?后面country的值既可以获得其它国家(地区)的股票数据。
步骤
一、获得请求头
使用审查元素功能可以简单的获得host和user-agent
headers={
'Host': 'cn.investing.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36 Edg/84.0.522.40'
二、导入需要的库
#!/usr/bin/env python
# coding: utf-8
import pandas as pd
import time
import requests
import openpyxl
from bs4 import BeautifulSoup
三、定义获取页面的函数
def get_page(url,params=None,headers=None,proxies=None,timeout=None):
response = requests.get(url, headers=headers, params=params, proxies=proxies, timeout=timeout)
print("解析网址:",response.url)
page = BeautifulSoup(response.text, 'lxml')
print("响应状态码:", response.status_code)
return page
四、循环获得每个国家(地区)的股票
先将国家(地区)传入的参数放入列表中
countrys = [
'china',
'hong-kong',
'singapore',
'uk',
'usa',
'germany'
]
因为防止工作表覆盖,所以先定义一个writer对象
writer = pd.ExcelWriter('stocks.xlsx')
根据之前的分析获取股票数据并将其保存到stocks.xlsx文件中。
每个国家(地区)对应一个工作表。
time.sleep(1)防止爬取太快导致被反爬
for country in countrys:
url = 'https://cn.investing.com/equities/most-active-stocks'
headers={
'Host': 'cn.investing.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36 Edg/84.0.522.40'
}
params={
'country' : country
}
page = get_page(url,headers=headers,params=params)
stocks = []
stocks_list = page.find_all('td','left bold plusIconTd elp')
for stock in stocks_list:
stocks.append(stock.a.text)
dataframe = pd.DataFrame({
'股票':stocks})
dataframe.to_excel(writer, sheet_name=country, header=None, index=False)
time.sleep(1)
writer.close()
完整代码
#!/usr/bin/env python
# coding: utf-8
import pandas as pd
import time
import requests
import openpyxl
from bs4 import BeautifulSoup
def get_page(url,params=None,headers=None,proxies=None,timeout=None):
response = requests.get(url, headers=headers, params=params, proxies=proxies, timeout=timeout)
print("解析网址:",response.url)
page = BeautifulSoup(response.text, 'lxml')
print("响应状态码:", response.status_code)
return page
countrys = [
'china',
'hong-kong',
'singapore',
'uk',
'usa',
'germany'
]
writer = pd.ExcelWriter('stocks.xlsx')
for country in countrys:
url = 'https://cn.investing.com/equities/most-active-stocks'
headers={
'Host': 'cn.investing.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36 Edg/84.0.522.40'
}
params={
'country' : country
}
page = get_page(url,headers=headers,params=params)
stocks = []
stocks_list = page.find_all('td','left bold plusIconTd elp')
for stock in stocks_list:
stocks.append(stock.a.text)
dataframe = pd.DataFrame({
'股票':stocks})
dataframe.to_excel(writer, sheet_name=country, header=None, index=False)
time.sleep(1)
writer.close()