上篇文章中我们着重介绍了HDFS的基本架构和读写流程,本章主要来认识HDFS的NameNode,
简单来讲,NameNode就是HDFS的大脑,任何客户端或者DataNode的数据迁移、目录操作都是由NameNode来完成的。
再了解了NameNode会干什么事情之后,最好深入的办法就是来看NameNode有哪些重要的数据结构,每个数据结构都干什么事情。
我们提到NameNode主要是维护文件在哪里这个映射关系。故而主要包含的内容是:
1、fileName和目录block的关系。
2、block到mist(机器列表)的关系。
fileName到block的关系是fsimage(类似镜像文件)写入到本地,每次启动的时候进行加载。block到mlist的的关系则是通过HDFS启动后,DataNode向NameNode报告心跳实现。为什么这样设计的原因:
1、文件和目录block的关系存在的时候不会发生变化。
2、block和mlist的关系会因为均衡数据迁移,机器故障数据迁移发生变化。
3、架构考虑点。
NameNode只有三种交互。
1、client访问NameNode获取相关DataNode信息。
2、DataNode心跳汇报当前block情况。
3、SecondaryNameNode做checkpoint交互。
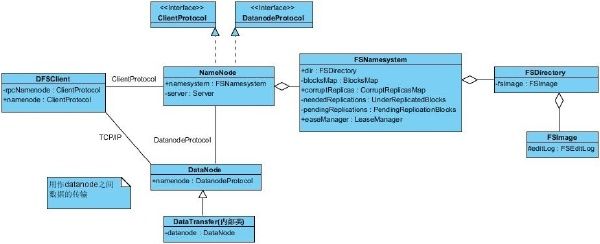
先来看类图:
FSNameSystem
在NameNode中,基本上重要的创建,维护,同步,更新都操作都是通过FSNameSystem来完成的。各种关键的数据结构也是在FSNameSystem中维护的。可以这样说基本上做的所有操作都是通过和FSNameSystem打交道来完成的。
FSDirectory
顾名思义,该类是用来维护所有以文件路径的。这个类维护着HDFS中所有的目录信息,并且会被持久化到NameNode本地作为FSImage(非常紧凑的二进制文件)存储起来。FSImage的相关操作也是通过FSDirectory完成的,HDFS的各种操作,会记录到EditLog中(EditLog也是通过FSDriectory维护),周期性的把FSImage和EditLog合并起来就是当前所有的目录信息。
HDFS所有的目录信息是通过树的方式来维护的。(想象一下普通的电脑上的文件不都是以树的方式维护的吗),在HDFS中所有文件的抽象是INode,目录则是INodeDirectory,文件则是INodeFile。
FSImage
从上一部分我们已经了解到了,FSImage就是文件目录元数据的某个时间段的镜像文件。每次启动后所有文件目录操作都会通过FSDriectory记录到EditLog,这带来一个问题,启动的时间越长EditLog中的内容会更多,下次再做合并的时候(这个合并我们称为checkpoint),会随着EidtLog文件的大小增加合并的时间,HDFS针对这个问题设置了两种机制进行条件合并,例如配置EditLog达到多大做一次合并,或者离上次合并过了多久做一次合并。 但是如果NameNode合并文件占用过多的资源,可能会引发其他的问题。那么如何来避免这样一个问题呢?后续我们会介绍,如何用
SecondaryNameNode来避免这个问题。
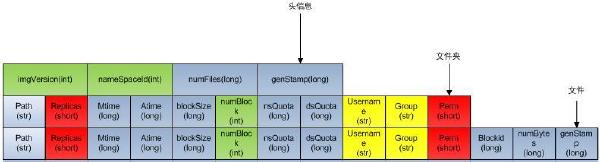
FSImage文件格式如下:
当namenode重启加载fsimage时,就是按照如下格式协议从文件流中加载元数据信息。从fsimag的存储格式可以看出,fsimage保存有如下信息:
一、加载Img头信息,如下:
1、 imgVersion(int):当前image的版本信息
2、namespaceID(int):用来确保别的HDFS instance中的datanode不会误连上当前NN。
3、numFiles(long):整个文件系统中包含有多少文件和目录
4、genStamp(long):生成该image时的时间戳信息。
二 、如果加载目录,包含以下信息:
1、path(String):该目录的路径,如”/user/build/build-index”
2、replications(short):副本数(目录虽然没有副本,但这里记录的目录副本数也为3)
3、mtime(long):该目录的修改时间的时间戳信息
4、atime(long):该目录的访问时间的时间戳信息
5、blocksize(long):目录的blocksize都为0
6、numBlocks(int):实际有多少个文件块,目录的该值都为-1,表示该item为目录
7、nsQuota(long):namespace Quota值,若没加Quota限制则为-1
8、dsQuota(long):disk Quota值,若没加限制则也为-1
9、username(String):该目录的所属用户名
10、group(String):该目录的所属组
11、permission(short):该目录的permission信息,如644等,有一个short来记录。
三、如果加载文件,则还会额外包含如下信息:
1、blockid(long):属于该文件的block的blockid,
2、numBytes(long):该block的大小
3、genStamp(long):该block的时间戳
当该文件对应的numBlocks数不为1,而是大于1时,表示该文件对应有多个block信息,此时紧接在该fsimage之后的就会有多个blockid,numBytes和genStamp信息。
因此,在namenode启动时,就需要对fsimage按照如下格式进行顺序的加载,以将fsimage中记录的HDFS元数据信息加载到内存中。
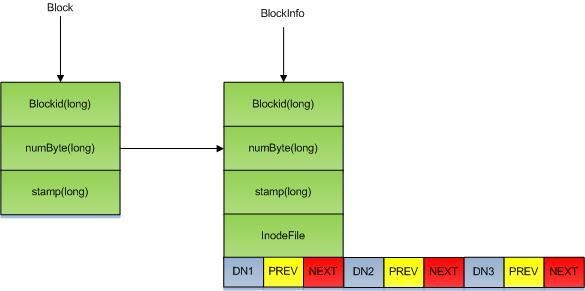
BlocksMap
最初我们提到过FSImage中没有block到机器列表的映射关系的原因。每一个DataNode启动的时候会通过BlockReport将当前机器所有block信息汇报给NameNode。汇报的相关信息就是维护在BlockMaps中的,
BlocksMap结构如下:
我们前面提到,FSImage中维护的是文件和block的关系,那么block和机器的关系便是从BlocksMap中获取的。
BlocksMap维护了三种关系:
1、file-blcoks
2、block-datanodelist
3、datanode-blocks
从上图中我们也可以看到,BlocksMap中的BlockInfo中维护了包括:
1、blockid,块ID。
2、块大小。
3、块的修改时间戳。
4、块对应的文件。
5、块对应的机器列表信息。
DataNode列表
在上图中已经看到,每一个BlockInfo上都有一个DN1,DN2,DN3其实就是一个block在三台机器上的备份。每一个DataNode对应的是一个Object[]的三元数组,prev表示当前block在该机器上的上一个block,next表示当前block在该机器上的下一个数组。目的很简单,查询一个DataNode上的所有BlockList需求非常少。这样做一来可以节省大量的内存(我们说过,内存会成为NameNode的瓶颈哦),二来直接根据next的指向就可以获取一个DN上的所有blocklist数据。
CorruptReplicationMap
简单来理解,在DN上有问题的block(磁盘坏,校验不对)都会在这里,下一次DN做心跳的时候有问题的block会返回给DN并删除。
UnderReplicationMap
默认的block副本数目是3,没有达到这个数目(磁盘坏了,DN挂了)的都会在这里,并且离的越远,数据迁移优先级会越高。
PeddingReplicationMap
block坏了,咱要做数据拷贝吧,在迁移中的5分钟没有成功的就认为失败,则添加到neededReplicationBlocks中,以便下次再做数据拷贝。
本篇文章,我们简单的介绍了NameNode的基本数据结构,但是对于NameNode的单点问题,checkpoint的问题,包括文中提到的SecondaryNameNode等并没有做详细的介绍。
下一篇:
HDFS读书笔记-如何让NameNode高可用(三)