ORC提取图片中文字
前因:
事情是这样的:目前有一个需求,将pdf中的一些内容做成PPT,PDF中的文字不能选中,是以图片形式保存的。如果人工对照PDF打字速度较慢,费时费力,下面不介绍ORC的实现,是介绍如何使用。
主题:
orc实现图片中的文字提取
实现:
1.安装
pip install cnocr
首次使用cnocr时,系统会自动从 cnocr-models 下载zip格式的模型压缩文件,并存于 ~/.cnocr目录。 下载后的zip文件代码会自动对其解压,然后把解压后的模型相关目录放于~/.cnocr/1.1.0目录中。
如果系统不能自动从 cnocr-models 成功下载zip文件,则需要手动下载此zip文件并把它放于 ~/.cnocr/1.1.0目录。如果Github下载太慢,也可以从 百度云盘 下载, 提取码为 ri27。
放置好zip文件后,后面的事代码就会自动执行了。
具体使用参照:这里
2.使用
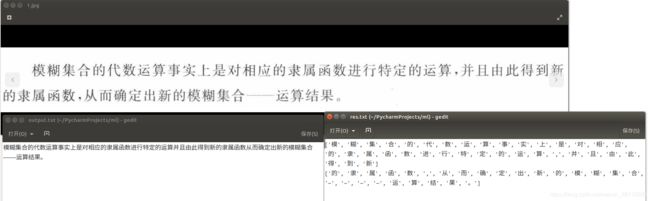
需要提取文字的图片:

这里先贴上我的代码:
from cnocr import CnOcr
file = 'res.txt'
ocr = CnOcr()
res = ocr.ocr('1.jpg')
with open(file, 'w') as f1:
f1.write("")
with open(file, 'a') as file_:
for r in res:
print(r)
file_.write(str(r) + '\n')
res = ""
# 对文字中的空格,单引号、逗号、【】进行处理
with open(file) as f:
for line in f.readlines():
print(line.strip('[').strip('\n').strip(']'))
for word in line.strip('[').strip('\n').strip(']'):
if ord(word) not in [32, 39, 44]:
res += str(word)
with open("output.txt", 'w') as f:
f.write(res)
 从图中可以看出返回值是一个列标,我将其输出到res.txt中得到如下结果:
从图中可以看出返回值是一个列标,我将其输出到res.txt中得到如下结果:
['模', '糊', '集', '合', '的', '代', '数', '运', '算', '事', '实', '上', '是', '对', '相', '应', '的', '隶', '属', '函', '数', '进', '行', '特', '定', '的', '运', '算', ',', '并', '且', '由', '此', '得', '到', '新']
['的', '隶', '属', '函', '数', ',', '从', '而', '确', '定', '出', '新', '的', '模', '糊', '集', '合', '—', '—', '—', '—', '运', '算', '结', '果', '。']
PS:建议自己运行一下查看程序中:
ocr = CnOcr()
res = ocr.ocr('1.jpg')
具体输出结果后,在阅读下面的文字。
我想得到的效果是一段不包含多余字符的文字,于是又重新对输出结果进行处理,得到了最终结果:
模糊集合的代数运算事实上是对相应的隶属函数进行特定的运算并且由此得到新的隶属函数从而确定出新的模糊集合————运算结果。
对比图