《C++ Primer》习题参考答案:第2章 - 变量和基本类型
专栏C++学习笔记
《C++ Primer》学习笔记/习题答案 总目录
- https://blog.csdn.net/TeFuirnever/article/details/100700212
——————————————————————————————————————————————————————
- 《C++ Primer》学习笔记(二):变量和基本类型
Cpp-Prime5 + Cpp-Primer-Plus6 源代码和课后题
第2章 - 变量和基本类型
练习2.1
类型 int、long、long long 和 short 的区别是什么?无符号类型和带符号类型的区别是什么?float 和 double的区别是什么?
解:
在 C++ 语言中,int、long、long long 和 short 都属于整型,区别是 C++ 标准规定的尺寸的最小值(即该类型在内存中所占的比特数)不同。其中,short 是短整型,占16位;int 是整型,占16位;long 和 long long 均为长整型,分别占32位和64位。C++ 标准允许不同的编译器赋予这些类型更大的尺寸。某一类型占的比特数不同,它所能表示的数据范围也不一样。
大多数整型都可以划分为无符号类型和带符号类型,在无符号类型中所有比特都用来存储数值,但是仅能表示大于等于0的值;带符号类型则可以表示正数、负数或0。
float 和 double 分别是单精度浮点数和双精度浮点数,区别主要是在内存中所占的比特数不同,以及默认规定的有效位数不同。
练习2.2
计算按揭贷款时,对于利率、本金和付款分别应选择何种数据类型?说明你的理由。
解:
在实际应用中,利率、本金和付款极有可能是整数,也有可能是普通的实数。因此应该选择一种浮点类型来表示。
在三种可供选择的浮点类型 float、double 和 long double 中,double 和 float 的计算代价比较接近且表示范围更广,long double的计算代价则相对较大,一般情况下没有选择的必要。
综合以上分析,选择 double 是比较恰当。
练习2.3
读程序写结果。
unsigned u = 10, u2 = 42;
std::cout << u2 - u << std::endl;
std::cout << u - u2 << std::endl;
int i = 10, i2 = 42;
std::cout << i2 - i << std::endl;
std::cout << i - i2 << std::endl;
std::cout << i - u << std::endl;
std::cout << u - i << std::endl;
解:
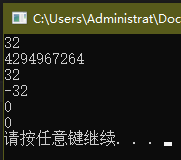
u 和 u2 都是无符号整数,因此 u2 - u 得到了正确的结果(42 - 10 = 32);u - u2 也能正确计算,但是因为直接计算的结果是 -32,所以在表示为无符号整数时自动加上了模,在我的编译环境中 int 占32位,因此加模( 2 32 = 4294967296 2^{32} = 4294967296 232=4294967296)的结果是4294967264。
i 和 i2 都是带符号整数,因此中间两个式子的结果比较直观,42 - 10 = 32,10 - 42 = -32。
在最后两个式子中,u 和 i 分别是无符号整数和带符号整数,计算时编译器先把带符号整数转换为无符号整数,幸运的是,i 本身是一个正数,因此转换后不会出现异常情况,两个式子的计算结果都是0。
不过需要注意的是,一般情况下请不要在同一个表达式中混合使用无符号整数和带符号整数。因为计算前带符号类型会自动转换成无符号类型,当带符号类型取值为负时就会出现异常结果。
练习2.4
编写程序检查你对 练习2.3 的估计是否正确,如果不正确,请仔细研读本节直到弄明白问题所在。
解:
其实最大的问题一般应该是无符号负数的计算,这个需要积累,别问我为啥知道,因为我也错了。
练习2.5
指出下述字面值的数据类型并说明每一组内几种字面值的区别:
(a) 'a', L'a', "a", L"a"
(b) 10, 10u, 10L, 10uL, 012, 0xC
(c) 3.14, 3.14f, 3.14L
(d) 10, 10u, 10., 10e-2
解:
(a): 字符字面值,宽字符字面值且类型是 wchar_t,字符串字面值,宽字符串字面值。
(b): 普通的整数类型字面值,无符号数,长整型数,无符号长整型数,八进制数,十六进制数。
(c): 普通的浮点类型字面值,float 类型的单精度浮点数,long double 类型的扩展精度浮点数。
(d): 整数,无符号整数,浮点数,科学计数法表示的浮点数。
练习2.6
下面两组定义是否有区别,如果有,请叙述之:
int month = 9, day = 7;
int month = 09, day = 07;
解:
第一组定义是正确的,定义了两个十进制数9和7。
第二组定义是错误的,编译时将报错。因为以0开头的数是八进制数,而数字9显然超出了八进制数能表示的范围,所以第二组定义无法被编译通过。
练习2.7
下述字面值表示何种含义?它们各自的数据类型是什么?
(a) "Who goes with F\145rgus?\012"
(b) 3.14e1L
(c) 1024f
(d) 3.14L
解:
(a) 是一个字符串,包含两个转义字符,其中 \145 表示字符 e,\012 表示一个换行符,因此该字符串的输出结果是:Who goes with Fergus?(换行)
(b) 是一个科学计数法表示的扩展精度浮点数,大小为 3.14 ∗ 1 0 1 = 31.4 3.14 * 10^1 = 31.4 3.14∗101=31.4
(c) 试图表示一个单精度浮点数,但是该形式在某些编译器中将报错,因为后缀 f 直接跟在了整数 1024 后面,改成 1024.f 就可以了
(d) 是一个扩展精度浮点数,类型是 long double,大小是 3.14
练习2.8
请利用转义序列编写一段程序,要求先输出 2M,然后转到新一行。修改程序使其先输出 2,然后输出制表符,再输出 M,最后转到新一行。
解:
#include 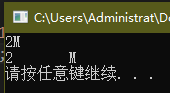
主函数的前两行分别实现了题目中要求的两种输出形式。
其中,字符串 2\xed\012 先输出字符 2,紧接着利用转义字符 \x4d 输出字符串 M,最后利用转义字符 \012 转到新一行。
字符串 2\tM\n 先输出字符 2,然后利用转义字符 \t 输出一个制表符,接着输出字符 M,最后利用转移字符 \n 转到新一行。
可以发现,输出同一字符有多重方式可供选择。例如,可以直接输出字符 M,也可以通过转义字符 \x4d 输出字符 M;可以用转义字符 \012 换行,也可以用转移字符 \n 换行。
练习2.9
解释下列定义的含义,对于非法的定义,请说明错在何处并将其改正。
(a) std::cin >> int input_value;
(b) int i = {
3.14};
(c) double salary = wage = 9999.99;
(d) int i = 3.14;
解:
(a): 是错误的,输入运算符的右侧需要一个明确的变量名称,而非定义变量的语句,应该先定义再使用。改正后的结果是:
int input_value;
std::cin >> input_value;
(b): 引发警告,该语句定义了一个整型变量 i,但是试图通过列表初始化的方式把浮点数 3.14 赋值给 i,这样做将造成小数部分丢失,是一种不被建议的窄化操作。改正后的结果是:
double i = {
3.14};
(c): 是错误的,该语句试图将 9999.99 分别赋值给 salary 和 wage,但是在声明语句中声明多个变量时需要用逗号将变量名隔开,而不是直接用赋值运算符连接。改正后的结果是:
double salary, wage;
salary = wage = 9999.99;
(d): 引发警告,该语句定义了一个整型变量 i,但是试图把浮点数 3.14 赋值给 i,这样做将造成小数部分丢失,与(b)一样,是不被建议的窄化操作。改正后的结果是:
double i = 3.14;
练习2.10
下列变量的初值分别是什么?
std::string global_str;
int global_int;
int main()
{
int local_int;
std::string local_str;
}
解:
对于 string 类型的变量来说,因为 string 类型本身接受无参数的初始化方式,所以不论变量定义在函数内还是函数外都被默认初始化为空字符串。
对于内置类型 int 来说,变量 global_int 定义在所有函数体之外,根据 C++ 的规定,global_int 默认初始化为 0,而变量 local_int 定义在 main 函数的内部,将不被初始化,如果程序试图拷贝或输出未初始化的变量,将遇到一个为定义的奇异值。
练习2.11
指出下面的语句是声明还是定义:
(a) extern int ix = 1024;
(b) int iy;
(c) extern int iz;
解:
声明与定义的关系是:声明使得名字为程序所知,而定义负责创建与名字关联的实体。
(a): 定义了变量 ix
(b): 声明并定义了变量 iy
(c): 声明了变量 iz
练习2.12
请指出下面的名字中哪些是非法的?
(a) int double = 3.14;
(b) int _;
(c) int catch-22;
(d) int 1_or_2 = 1;
(e) double Double = 3.14;
解:
(a)是非法的,因为 double 是c++关键字,代表一种数据类型,不能作为变量的名字。
(b)是合法的命名。
(c)是非法的,在标识符中只能出现字母、数字和下划线,不能出现符号 -,如果改成 int catch_22; 就是合法的了。
(d)是非法的,因为标识符必须以字母或下划线开头,不能以数字开头。
(e)是合法的命名。
练习2.13
下面程序中j的值是多少?
int i = 42;
int main()
{
int i = 100;
int j = i;
}
解:
j 的值是100。
c++允许内层作用域重新定义外层作用域中已有的名字,在本题中,int i = 42; 位于外层作用域,但是变量 i 在内层作用域被重新定义了,因此真正赋予 j 的值是定义在内层作用域中的 i 的值,即100。
练习2.14
下面的程序合法吗?如果合法,它将输出什么?
int i = 100, sum = 0;
for (int i = 0; i != 10; ++i)
sum += i;
std::cout << i << " " << sum << std::endl;
解:
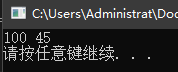
该程序是合法的。输出结果是 100 45。
该程序存在嵌套的作用域,其中 for 循环之外是外层作用域,for 循环内部是内层作用域。首先在外层作用域中定义了 i 和 sum,但是在 for 循环内部 i 被重新定义了,因此 for 循环实际上是从 i=0 循环到了 i=9,内层作用域中没有重新定义 sum,因此 sum 的初始值是0并在此基础上依次累加。最后一句输出语句位于外层作用域中,此时在 for 循环内部重新定义的 i,值为100;而 sum 经由循环累加,值变为了45。
练习2.15
下面的哪个定义是不合法的?为什么?
(a) int ival = 1.01;
(b) int &rval1 = 1.01;
(c) int &rval2 = ival;
(d) int &rval3;
解:
(a) 是合法的。
(b) 是非法的,引用必须指向一个实际存在的对象而非字面值常量。
(c) 是合法的。
(d) 是非法的,因为无法令引用重新绑定到另外一个对象,所以引用必须初始化。
练习2.16
考察下面的所有赋值然后回答:哪些赋值是不合法的?为什么?哪些赋值是合法的?它们执行了哪些操作?
int i = 0, &r1 = i; double d = 0, &r2 = d;
(a) r2 = 3.14159;
(b) r2 = r1;
(c) i = r2;
(d) r1 = d;
解:
(a) 是合法的,为引用赋值实际上是把值赋给了与引用绑定的对象,在这里是把 3.14159 赋给了变量 d。
(b) 是合法的,以引用作为初始值实际上是以引用绑定的对象作为初始值,在这里是把 i 的值赋给了变量 d。
(c) 是合法的,把 d 的值赋给了变量 i,因为 d 是双精度浮点数而 i 是整数,所以该语句实际上执行了窄化操作。
(d) 是合法的,把 d 的值赋给了变量 i,与上一条语句一样执行了窄化操作。
练习2.17
执行下面的代码段将输出什么结果?
int i, &ri = i;
i = 5; ri = 10;
std::cout << i << " " << ri << std::endl;
解:
程序的输出结果是10, 10。
引用不是对象,它只是为已经存在的对象起了另外一个名字,因此 ri 实际上是 i 的别名。在上面的程序中,首先将 i 赋值为 5,然后把这个值更新为 10。因为 ri 是 i 的引用,所以它们的输出结果是一样的。
练习2.18
编写代码分别改变指针的值以及指针所指对象的值。
解:
#include 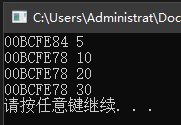
在上面的例子中,首先定义了两个整型变量 i 和 j 以及一个整型指针 p,初始情况下指针 p 指向变量 i,此时分别输出 p 的值(即 p 所指对象的内存地址)以及 p 所指对象的值,得到 00BCFE84 和 5。
随后依次改变指针的值以及指针所指对象的值。p=&j; 更改了指针的值,令指针 p 指向另外一个整数对象 j。*p=20; 和 j=30; 是两种更改指针所指对象值的方式,前者显式地更改指针 p 所指的内容,后者则通过更改变量 j 的值实现同样的目的。
练习2.19(这个题面试经常考察)
说明指针和引用的主要区别
解:
指针“指向”内存中的某个对象,而引用“绑定到”内存中的某个对象,它们都实现了对其他对象的间接访问,二者的区别主要有两个方面:
- 第一,指针本身就是一个对象,允许对指针赋值和拷贝,而且在指针的声明周期内它可以指向几个不同的对象;引用不是一个对象,无法令引用重新绑定到另外一个对象。
- 第二,指针无需在定义时赋初值,和其他内置类型一样,在块作用域内定义的指针如果没有被初始化,也将拥有一个不确定的值;引用则必须在定义时赋初值。
练习2.20
请叙述下面这段代码的作用。
int i = 42;
int *p1 = &i;
*p1 = *p1 * *p1;
解:
这段代码首先定义了一个整型变量 i 并设其初值为 42;接着定义了一个整型指针 p1,令其指向变量 i;最后取出 p1 所指的当前值,计算平方后重新赋给 p1 所指的变量 i,即 42 * 42 (1764)。
第二行的 * 表示声明一个指针,第三行的 * 表示解引用运算,即取出指针 p1 所指对象的值。
编写一个小程序实现一下,就知道结果了:
#include 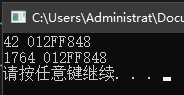
练习2.21
请解释下述定义。在这些定义中有非法的吗?如果有,为什么?
int i = 0;
(a) double* dp = &i;
(b) int *ip = i;
(c) int *p = &i;
解:
(a) 是非法的,dp 是一个 double 指针,而 i 是一个 int 变量,类型不匹配。
(b) 是非法的,不能直接把 int 变量赋给 int 指针,正确的做法是,通过取地址运算 &i 得到变量 i 在内存中的地址,然后再将该地址赋给指针。
(c) 是合法的。
练习2.22
假设 p 是一个 int 型指针,请说明下述代码的含义。
if (p) // ...
if (*p) // ...
解:
指针 p 作为 if 语句的条件时,实际检验的是指针本身的值,即指针所指的地址值。如果指针指向一个真实存在的变量,则其值必不为0,此时条件为真;如果指针没有指向任何对象或者是无效指针,则对 p 的使用将引发不可预计的后果。
解引用运算符 *p 作为 if 语句的条件时,实际检验的是指针所指的对象内容,在上面的例子中是指针 p 所指的 int 值。如果该 int 值为0,则条件为假;否则,如果该 int 值不为0,对应条件为真。
举个简单的例子:
#include 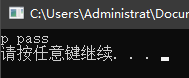
在这段程序中,p 和 p1 是两个整型指针,其中 p1 被定义为空指针(nullptr),p 则指向整数 i。在3个判断条件中,p1 指向空,意即指向地址为0,条件不满足;p 指向 i,在内存中有一个实际的地址值且不为0,因此该条件满足;*p 表示 p 所指对象的内容,即整数 i 的值,因为程序开始处 i 被赋予了初值0,所以这个条件不满足。
练习2.23
给定指针 p,你能知道它是否指向了一个合法的对象吗?如果能,叙述判断的思路;如果不能,也请说明原因。
解:
在c++程序中,应该尽量初始化所有指针,并且尽可能等定义了对象之后再定义指向它的指针。如果实在不清楚应该指向何处,就把它初始化为 nullptr 或0,这样程序就能检测并指导它有没有指向一个具体的对象了。
其中 nullptr 是c++11新标准刚刚引入的一个特殊字符值,它可以转换成任意其他的指针类型。在此前提下,判断 p 是否指向合法的对象,只需把 p 作为 if 语句的条件即可,如果 p 的值是 nullptr,则条件为假;反之,条件为真。
如果不注意初始化所有指针而贸然判断指针的值,则有可能引发不可预知的结果。一种处理的办法是把 if(p) 置于 try 结构中,当程序块顺利执行时,表示 p 指向了合法的对象;当程序块出错跳转到 catch 语句时,表示 p 没有指向合法的对象。
练习2.24
在下面这段代码中为什么 p 合法而 lp 非法?
int i = 42;
void *p = &i;
long *lp = &i;
解:
p 是合法的,因为 void* 是一种特殊的指针类型,可用于存放任意对象的地址。
lp 是非法的,因为 lp 是一个长整型指针,而 i 只是一个普通整型数,二者的类型不匹配。
练习2.25
说明下列变量的类型和值。
(a) int* ip, i, &r = i;
(b) int i, *ip = 0;
(c) int* ip, ip2;
解:
(a) ip 是一个整型指针,指向一个整型数,它的值是所指整型数在内存中的地址;i 是一个整型数;r 是一个引用,它绑定了 i,可以看作是 i 的别名,r 的值就是 i 的值。
(b) i 是一个整型数;ip 是一个整型指针,但是它不指向任何具体的对象,它的值被初始化为0。
(c) ip 是一个整型指针,指向一个整型数,它的值是所指整型数在内存中的地址;ip2 是一个整型数。
练习2.26
下面哪些语句是合法的?如果不合法,请说明为什么?
解:
const int buf;
int cnt = 0;
const int sz = cnt;
++cnt; ++sz;
(a) 是非法的,const 对象一旦创建后其值就不能改变,所以 const 对象必须初始化。该句应修改为 const int buf = 10。
(b) 是合法的。
(c) 是合法的。
(d) 是非法的,sz 是一个 const 对象,其值不能被改变,当然不能执行自增操作。
练习2.27
下面的哪些初始化是合法的?请说明原因。
解:
(a) int i = -1, &r = 0;
(b) int *const p2 = &i2;
(c) const int i = -1, &r = 0;
(d) const int *const p3 = &i2;
(e) const int *p1 = &i2;
(f) const int &const r2;
(g) const int i2 = i, &r = i;
解:
(a) 是非法的,非常量引用 r 不能引用字面值常量0。
(b) 是合法的,p2 是一个常量指针,p2 的值永不改变,即 p2 永远指向变量 i2。
© 是合法的,i 是一个常量,r 是一个常量引用,此时 r 可以绑定到字面值常量0。
(d) 是合法的,p3 是一个常量指针,p3 的值永不改变,即 p3 永远指向变量 i2;同时 p3 指向的是常量,即不能通过 p3 改变所指对象的值。
(e) 是合法的,p1 指向一个常量,即不能通过 p1 改变所指对象的值。
(f) 是非法的,引用本身不是对象,因此不能让引用恒定不变。
(g) 是合法的,i2 是一个常量,r 是一个常量引用。
练习2.28
说明下面的这些定义是什么意思,挑出其中不合法的。
解:
int i, *const cp;
int *p1, *const p2;
const int ic, &r = ic;
const int *const p3;
const int *p;
解:
(a) 是非法的,cp 是一个常量指针,因其值不能被改变,所以必须初始化。
(b) 是非法的,p2 是一个常量指针,因其值不能被改变,所以必须初始化。
(c) 是非法的,ic 是一个常量,因其值不能被改变,所以必须初始化。
(d) 是非法的,p3 是一个常量指针,因其值不能被改变,所以必须初始化;同时 p3 指向的是常量,即不能通过 p3 改变所指对象的值。
(e) 是合法的,但是 p 没有指向任何实际的对象。
练习2.29
假设已有上一个练习中定义的那些变量,则下面的哪些语句是合法的?请说明原因。
解:
i = ic;
p1 = p3;
p1 = ⁣
p3 = ⁣
p2 = p1;
ic = *p3;
解:
(a) 是合法的,常量 ic 的值赋给了非常量 i。
(b) 是非法的,普通指针 p1 指向了一个常量,从语法上说,p1 的值可以随意改变,显然是不合理的。
© 是非法的,普通指针 p1 指向了一个常量,错误情况与上一条类似。
(d) 是非法的,p3 是一个常量指针,不能被赋值。
(e) 是非法的,p2 是一个常量指针,不能被赋值。
(f) 是非法的,ic 是一个常量,不能被赋值。
练习2.30
对于下面的这些语句,请说明对象被声明成了顶层const还是底层const?
const int v2 = 0; int v1 = v2;
int *p1 = &v1, &r1 = v1;
const int *p2 = &v2, *const p3 = &i, &r2 = v2;
解:
v2 和 p3 是顶层 const,分别表示一个整型常量和一个整型常量指针;
p2 和 r2 是底层 const,分别表示它们所指(所引用)的对象是常量。
练习2.31
假设已有上一个练习中所做的那些声明,则下面的哪些语句是合法的?请说明顶层const和底层const在每个例子中有何体现。
解:
r1 = v2;
p1 = p2;
p2 = p1;
p1 = p3;
p2 = p3;
解:
在执行拷贝操作时,顶层 const 和底层 const 区别明显。其中,顶层 const 不受影响,这是因为拷贝操作并不会改变被拷贝对象的值。底层 const 的限制则不容忽视,拷入和拷出的对象必须具有相同的底层 const 资格,或者两个对象的数据类型必须能够转换。一般来说,非常量可以转换成常量,反之则不行。
-
r1=v2;是合法的,r1是一个非常量引用,v2是一个常量(顶层 const),把v2的值拷贝给r1不会对v2有任何影响。 -
p1=p2;是非法的,p1是普通指针,指向的对象可以是任意值,p2是指向常量的指针(底层 const),令p1指向p2所指的内容,有可能错误地改变常量的值。 -
p2=p1;是合法的,与上一条语句相反,p2可以指向一个非常量,只不过不会通过p2更改它所指的值。 -
p1=p3;是非法的,p3包含底层 const 定义(p3所指的对象是常量),不能把p3的值赋给普通指针。 -
p2=p3;是合法的,p2和p3包含相同的底层 const,p3的顶层 const 则可以忽略不计。
练习2.32
下面的代码是否合法?如果非法,请设法将其修改正确。
int null = 0, *p = null;
解:
上述代码是非法的,null 是一个 int 变量,p 是一个 int 指针,二者不能直接绑定。
仅仅从语法角度来说,可以将代码修改为:
int null = 0, *p = &null;
显然,这种写法与代码的愿意不一定相符。另一种改法是使用 nullptr ;
int null = 0, *p = nullptr;
练习2.35
判断下列定义推断出的类型是什么,然后编写程序进行验证。
const int i = 42;
auto j = i; const auto &k = i; auto *p = &i;
const auto j2 = i, &k2 = i;
解:
i 是一个整型常量,j 的类型判断结果是整数,k 的类型判断结果是整型常量,p 的类型判断结果是指向整型常量的指针,j2 的类型判断结果是整数,k2 的类型判断结果是整数。
程序如下:
#include 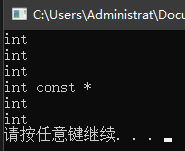
练习2.36
关于下面的代码,请指出每一个变量的类型以及程序结束时它们各自的值。
int a = 3, b = 4;
decltype(a) c = a;
decltype((b)) d = a;
++c;
++d;
解:
在本题的程序中,初始情况下 a 的值是3、b 的值是4。
decltype(a) c=a; 使用的是一个不加括号的变量,因此 c 的类型就是 a 的类型,即该语句等同于 int c=a;,此时 c 是一个新整型变量,值为3。
decltype((b))d=a; 使用的是一个加了括号的变量,因此 d 的类型是引用,即该语句等同于 int &d=a;,此时 d 是变量 a 的别名。
执行 ++c; ++d; 时,变量 c 的值自增为4,因为 d 是 a 的别名,所以 d 自增1意味着 a 的值变成了4。当程序结束时,a、b、c、d 的值都是4。
#include 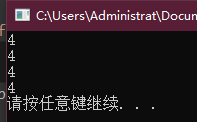
练习2.37
赋值是会产生引用的一类典型表达式,引用的类型就是左值的类型。也就是说,如果 i 是 int,则表达式 i=x 的类型是 int&。根据这一特点,请指出下面的代码中每一个变量的类型和值。
int a = 3, b = 4;
decltype(a) c = a;
decltype(a = b) d = a;
解:
根据 decltype 的上述性质可知,c 的类型是 int,值为3;表达式 a=b 作为 decltype 的参数,编译器分析表达式并得到它的类型作为 d 的推断类型,但是不实际计算该表达式,所以 a 的值不发生改变,仍然是3;d 的类型是 int&,d 是 a 的别名,值是3;b 的值一直没有发生改变,为4。
练习2.38
说明由decltype 指定类型和由auto指定类型有何区别。请举一个例子,decltype指定的类型与auto指定的类型一样;再举一个例子,decltype指定的类型与auto指定的类型不一样。
解:
auto 和 decltype 的区别主要有三个方面:
第一,aut0 类型说明符用编译器计算变量的初始值来推断其类型,而 decltype 虽然也让编译器分析表达式并得到它的类型,但是不实际计算表达式的值。
第二,编译器推断出来的 auto 类型有时候和初始值的类型并不完全一样,编译器会适当地改变结果类型使其更符合初始化规则。例如,auto 一般会忽略掉顶层 const,而把底层 const 保留下来。与之相反,decltype 会保留变量的顶层 const。
第三,与 auto 不同,decltype 的结果类型与表达式形式密切相关,如果变量名加上了一对括号,则得到的类型与不加括号时会有不同。如果 decltype 使用的是一个不加括号的变量,则得到的结果就是该变量的类型;如果给变量加上了一层或多层括号,则编译器将推断得到引用类型。
例子如下:
#include 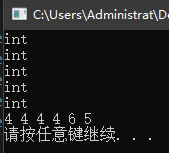
对于第一组类型推断来说,a 是一个非常量整数,c1 的推断结果是整数,c2 的推断结果也是整数,c3 的推断结果由于变量 a 额外加了一对括号,所以是整数引用。c1、c2、c3 依次执行自增操作,因为 c3 是变量 a 的别名,所以 c3 自增等同于 a 自增,最终 a、c1、c2、c3 的值都变为4。
对于第二组类型推断来说,d 是一个常量整数,含有顶层 const 使用 auto 推断类型自动忽略掉顶层 const,因此 f1 的推断结果是整数;decltype 则保留顶层 const ,所以 f2 的推断结果是整数常量。f1 可以正常执行自增操作,而常量 f2 的值不能被改变,所以无法自增。
练习2.39 - 2.42放在后期类的章节中再做。
如果想要更多的资源,欢迎关注 @我是管小亮,文字强迫症MAX~
回复【福利】即可获取我为你准备的大礼,包括C++,编程四大件,NLP,深度学习等等的资料。
想看更多文(段)章(子),欢迎关注微信公众号「程序员管小亮」~
