牛客网——题解2
1、以下叙述中正确的是(B)
题解:
A、任何情况下都不能用函数名作为实参
B、函数既可以直接调用自己,也可以间接调用自己
C、函数的递归调用不需要额外开销,所以效率很高
D、简单递归不需要明确的结束递归的条件
因为在某些情况下,函数名可以作为实参传递,所以 A 选项错误。函数递归调用使用栈区来递归,需要额外开销,并且效率不高, C 选项错误。递归调用需要明确指出递归结束条件,否则就陷入死循环了,D选项错误。故选B
2、
程序段的执行结果是(14)
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
|
题解:在该源程序中,fun1函数是传的引用,引用直接通过内存地址访问变量,所以可以通过该引用改变main函数中的xyz的值,而func2是传值参数,当fanc2函数结束时,局部变量x也没有了,所以无法改变主函数中的值。 因此该运行结果为14;是因为fun1改变了值,fun2并没有把实际的值修改。
3、 (引用)是给对象取了一个别名,他引入了对象的同义词:
题解:引用即给别的变量起别名,正因为如此,系统不为引用另外分配内存空间,与所代表的变量占用同一段内存空间
4、函数名代表该函数的入口地址
5、SPOOLing 系统实现设备管理的虚拟技术,即将独占设备改造为共享设备,这样的说法正确吗?
题解:正确;
SPOOLing是Simultaneous Peripheral Operation On-Line (即外部设备联机并行操作)的缩写,它是关于慢速字符设备如何与计算机主机交换信息的一种技术,通常称为“假脱机技术。Spooling技术:利用高速共享设备(通常是磁鼓或者是磁带)将低速的独享设备模拟为高速的共享设备,这样,从逻辑上讲,计算机系统为每一个用户都分配了一***立的高速独享设备。
6、在下面的字符数组定义中,哪一个有语法错误。( D )。
题解:
char a[20]="abcdefg";char a[]="x+y=55.";char a[15];char a[10]='5';//错误由于选项D中的'5' 是一个字符常量,不能给字符型数组a初始化,应该是char a[10]={5};或者char a[10]="5";
7、完整的计算机系统应该包括(软硬件系统)
题解:软硬件系统
8、 请问下列代码的输出是多少()
#include
int main()
{
int m []={1,2,3,4,5,6,7,8,9,0};
int(*p)[4]=(int(*)[4])m;
printf(“%”,p[1][2]);
return 0;
}
题解:1、int (*p)[4]:表示行指针,单位移动量为4个int类型。即p+1,则一次移动4个int类型
2、(int (*)[4])m:表示以数组指针类型组织m,每4个为一个数组
3、这样一来,m为{{1,2,3,4},{5,6,7,8},{9,0, , }},p指向第一行
4、故p[1][2]即*(*(p+1)+2),表示第二行第三个元素,为7
9、DOS 系统中打印机设备名是(PRN )
题解:PRN
10、设 A,B的八位二进制补码为 1111 1010 和 0000 1010 ,那么 AB乘积的补码为:(1100 0100)
题解:
看补码知道 A为负数,B为正数,因此B原码和补码一致,A原码=(A补码-1) 取反 保持符号位不变。
原码: A 1000 0110;B 0000 1010,不考虑符号位,直接竖式相乘
1010 x 0110 = 11 1100,为结果的绝对值。取反加一,符号位置1 就得到 1100 0100
11、 顺序存储方式插入和删除时效率太低,因此它不如链式存储方式好。
题解:后半句不正确。顺序存储在查询时效率高于链式,所以不存在谁比谁好,只是适用情况不同。
12、若有以下程序
| 1 2 3 4 5 6 7 |
|
则程序的输出结果是
题解:本题考查字符变量以及printf( )函数相关知识,字符变量c1被赋值为'C'+'8'-'3',即ASSCII码的运算,67十54-49=72,即H;字符变量 c2被赋值为'9'-'0',但输出时,需要注意的是c1以字符变量输出,而c2是以十进制整型变量输出。因此B选项正确。
13、设有两个串p和q,其中q是p的子串,求q在p中首次出现的位置的算法称为
题解:子串很多个,不是首次出现才是子串,首次出现的叫模式匹配
14、以下选项中非法的C语言字符常量是?"\09"
'\007''\b''a'"\09"题解:
合法的字符常量。
注意: 1 、 C 语言区分大小写:单引号中的大小写字母代表不同的字符常量,例如 ’A’ 与 ’a’ 是不同的字符常量; 2 、单引号中的空格符也是一个字符常量 3 、字符常量只能包括一个字符,所以 ’ab’ 是非法的; 4 、字符常量只能用单引号括起来,不能用双引号。比如 ”a” 不是一个字符常量而是一个字符串。
(2) :转义字符常量 :转义字符又称反斜线字符,这些字符常量总是以一个反斜线开头后跟一个特定的字符,用来代表某一个特定的 ASCII 字符,这些字符常量也必须括在一对单引号内。
字符
作用
\n
换行
\t
横向跳格
\v
竖向跳格
\f
换页
\r
回车
\b
退格( Backspace )
\\
反斜杠( \ )
\’
单引号
\”
双引号
\ddd
3 位八进制数
\xhh
两位十六进制数
\0
空值 (ASCII 码值为 0)
注意:
1: 转义字符常量只代表一个字符,例如 ’\n’ 、 ’\101’;
2: 反斜线后的八进制数可以不用 0 开头;
3: 反斜线后的十六进制数只可由小写字母 x 开头,不能以大写字母 X 或 0X 开头。
15、
若有以下定义和语句:
| 1 |
|
则不能表示a数组元素的表达式是a[10]
*pa[10]*aa[p-a]题解:
A的值为1
B越界
C和A相同
D p-a地址相减为0,访问数组第一个元素
16、 从一个长度为n的顺序表中删除第i个元素(1≤i≤n)时,需向前移动(n-i)_个元素。
n-in-i+1n-i-1i题解:A 假设顺序表长度为1,若要删除第1个元素,则只需移动0个元素即可。 将n=1,i=1代入到四个选项中,只有n-i是正确的
17、已知 10*12 的二维数组 A ,以行序为主序进行存储,每个元素占 1 个存储单元,已知 A[1][1] 的存储地址为 420 ,则 A[5][5] 的存储地址为 (472 )
题解:对于本题,不用纠结于起始位置到底在哪里,题目已经告诉我们了A[1][1]的地址,只需要求题目要求的元素与A[1][1]之间有多少个元素就阔以了。 A[5][5]与A[1][1]之间有4*12+4=52个元素,而A[1][1]地址为420,那么A[5][5]的地址就为420+52=472
18、请问下面哪种方式可以在不改变原来数组的情况下,拷贝出数组 b ,且满足 b!=a 。例如数组 a 为 [1,2,3] 。——let b=a.concat();
let b=a;let b=a.slice();let b=a.splice(0,0);let b=a.concat();题解:A,b与a相同引用,b===a B,slice方法删除原数组元素,并返回删除的元素作为新数组 C,不改变原数组,但返回原数组的0开始,长度为0的元素,为空 D,返回新数组并不改变原数组
19、一个5*4的矩阵,有多少个长方形?(正方形也算是长方形)——150
题解:可以这样理解:五行四列的表格有6*5条边,从六条边选两条(横向),从四条边中选两条(纵向),就可以确定一个矩形。C(6,2)*C(5,2)=15*10=150
20、数组A=array[1..100,1..100]以行序为主序存储,设每个数据元素占2个存储单元,基地址为10,则LOC[5,5]应为818下面 是"abcd321ABCD"的子串。。
题解:

21、 下面 是"abcd321ABCD"的子串。——"21AB"
abcd
321ab
"abc ABC"
"21AB"
题解:子串也是串,因此abcd、321ab错误,又因为子串也是连续的,故为"21AB"。
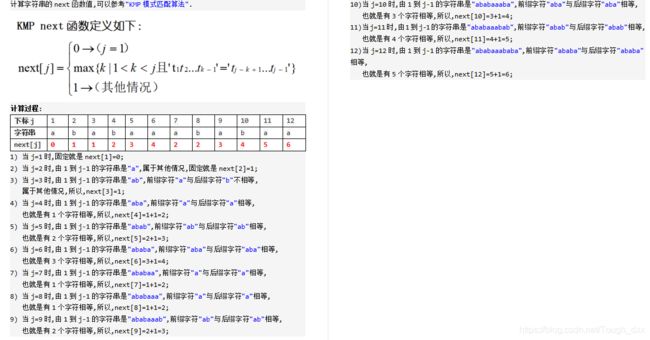
22、串'ababaaababaa'的next数组为
题解:011234223456
23、若有 18 个元素的有序表存放在一维数组 A[19] 中,第一个元素放 A[1] 中,现进行二分查找,则查找 A [ 3 ]的比较序列的下标依次为 ( 9,4,2,3 )
题解: 注意题目意思:第一元素放到A[1],说明该数组下表1开始。第一次查找 , high = 18, M1 = (1 + 18)/2 = 9 ; A[3] < A[9],high = M1 -1 = 8; M2 = (1 + 8) / 2 =4, 依次类推;故为9,4,2,3
24、char str[]=”Hello”,sizeof(str)=(6)
题解:sizeof计算长度包括字符串结束符\0
strlen不包括
25、对于长度为n的线性表,建立其对应的单链表的时间复杂度为(O(n))。
题解:我们使用头插式或尾插式创建链表都只需要一次循环遍历就可实现,所以时间复杂度为O(n)。
线性表是最基本、最简单、也是最常用的一种数据结构。线性表中数据元素之间的关系是一对一的关系,即除了第一个和最后一个数据元素之外,其它数据元素都是首尾相接的(注意,这句话只适用大部分线性表,而不是全部。比如,循环链表逻辑层次上也是一种线性表(存储层次上属于链式存储),但是把最后一个数据元素的尾指针指向了首位结点)。
链表是一种物理存储单元上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。链表由一系列结点(链表中每一个元素称为结点)组成,结点可以在运行时动态生成。每个结点包括两个部分:一个是存储数据元素的数据域,另一个是存储下一个结点地址的指针域。 相比于线性表顺序结构,链表比较方便插入和删除操作
26、一个栈的输入序列为123、、、、、n,若输出序列的第一个元素是n,输出第i(1<=i<=n)个元素是((n - i + 1))
不确定
n-i+1
i
n-i
题解:
当 i = 2时,输出元素是(n - 1)
符合公式(n - i + 1)
27、 线性表的顺序存储结构是一种(随机存取) 的存储结构,线性表的链式存储结构是一种顺序存取 的存储结构。
题解:顺序存储结构中,数据元素存放在一组地址连续的存储单元中,每个数据元素地址可通过公式LOC(ai)=LOC(a1)+(i-1)L计算得到,从而实现了随机存取。对于链式存储结构,要对某结点进行存取,都得从链的头指针指向的结点开始,这是一种顺序存取的存储结构。
一:顺序表的特点是逻辑上相邻的数据元素,物理存储位置也相邻,并且,顺序表的存储空间需要预先分配。
它的优点是:
(1)方法简单,各种高级语言中都有数组,容易实现。
(2)不用为表示节点间的逻辑关系而增加额外的存储开销。
(3)顺序表具有按元素序号随机访问的特点。
缺点:
(1)在顺序表中做插入、删除操作时,平均移动表中的一半元素,因此对n较大的顺序表效率低。
(2)需要预先分配足够大的存储空间,估计过大,可能会导致顺序表后部大量闲置;预先分配过小,又会造成溢出。
二、在链表中逻辑上相邻的数据元素,物理存储位置不一定相邻,它使用指针实现元素之间的逻辑关系。并且,链表的存储空间是动态分配的。
链表的最大特点是:
插入、删除运算方便。
缺点:
(1)要占用额外的存储空间存储元素之间的关系,存储密度降低。存储密度是指一个节点中数据元素所占的存储单元和整个节点所占的存储单元之比。
(2)链表不是一种随机存储结构,不能随机存取元素。
28、设二维数组A[0..m-1][0..n-1]按行优先顺序存储,则元素A[i][j]的地址为(LOC(A[0][0])+(i*n+j))
题解: 特别提醒:i、j表示的是数组的下标
首先,注意数组是从0开始还是从1开始
其次,数组的大小,数组的列数表示每行有几个元素,数组的行数表示每列有多少个元素