Greenplum高级使用
目录
9.1 常用查询语句
9.1.1 查看表的数据分布情况
9.1.2 查看默认的错误数据
9.1.3 查看表的大小
9.1.4 查看数据库的占用大小
9.1.5 获取一个表的schema的信息
9.1.6 查看每个schema的占用大小
9.1.7 查看当前正在执行的语句
9.1.8 释放表的膨胀空间
9.1.9 查看集群的配置信息
9.1.10 数据存放的路径
9.1.11 查看系统的日志
9.1.12 查看索引的占用大小
9.1.13 修改某个数据库为制度状态
9.1.14 查看集群中那些节点挂了
9.1.15 查看GP对应的PostgreSQL版本信息
9.1.16 查看是否锁表
9.1.17 查看集群中有哪些用户
9.2 常见创建表语句
9.2.1 快速复制一张表
9.2.2 重新设计一张表
9.3 分析执行计划
9.3.1 查看执行计划
9.3.2 名词解释
9.4 函数使用
9.4.1 创建函数
9.4.2 使用函数
9.4.3 删除函数
9.5 视图使用
9.5.1 视图命名规范
9.5.2 视图的定义
9.5.3 创建及查询视图语句
9.5.4 创建视图
9.5.5 查看视图结构
9.6 索引使用
9.6.1 支持的索引类型
9.6.2 获取索引的列表
9.6.3 bitmap索引的使用
9.6.4 b-tree索引的使用
9.6.5 查看索引大小
9.7 引用第三方库
9.8 常用设置
9.8.1 终端设置字符编码
9.8.2 设置终端执行时长
9.1 常用查询语句
9.1.1 查看表的数据分布情况
stagging=# select gp_segment_id,count(1) from tablename group by 1;
gp_segment_id | count
---------------+---------
3 | 3252310
19 | 3263648
32 | 3261394
*************
tablename: 需要查看的表的名字
gp_segment_id:segment的ID序列号
count : 当前的segment数据的个数
9.1.2 查看默认的错误数据
select * from gp_read_error_log('tablename');
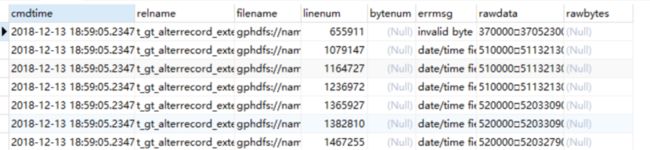
tablename:需要查看表的名字
错误表字段解释:
Column | Type | Modifiers
----------+--------------------------+-----------
cmdtime | timestamp with time zone | --操作时间
relname | text | --表名
filename | text | --文件名
linenum | integer | --错误行号
bytenum | integer |
errmsg | text | --错误信息
rawdata | text | --整行数据
rawbytes | bytea | --行大小
Distributed randomly
详细的说明请查看:Greenplum加载数据常见错误及解决方法
9.1.3 查看表的大小
select pg_size_pretty(pg_relation_size('tablename'));
9.1.4 查看数据库的占用大小
stagging=# select pg_size_pretty(pg_database_size('chinadaas'));
pg_size_pretty
----------------
3402 GB
(1 row)
可以看出当前chinadaas数据库已经占用3402 GB的空间了
9.1.5 获取一个表的schema的信息
9.1.5.1 通过SQL方式获取
9.1.5.1.1 获取方式一
select get_table_structure('main.t_ent_baseinfo');
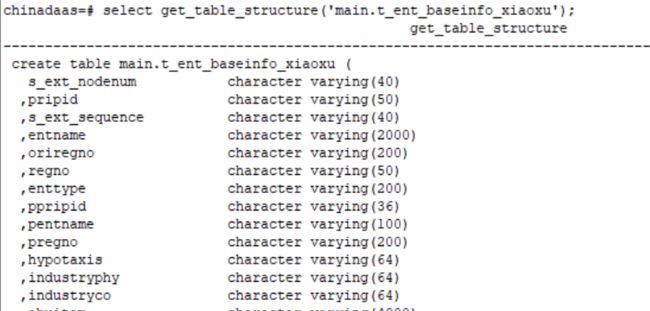
可以获取一个表的schema的相关的信息,好处是把所有的字段信息全部列处理
9.1.5.1.2 获取方式二
# select col.ordinal_position,col.table_schema,col.table_name,col.column_name,col.data_type||'('||col.character_maximum_length||')',col.data_type||'('||col.numeric_precision||','||col.numeric_scale||')' from information_schema.columns col where col.table_schema='****' and col.table_name ='*****' order by col.ordinal_position;

需要在****填写相对应的信息,此方式可以快速的获取字段的个数与字段的列表
9.1.5.2 通过终端方式获取
在以下的操作中可以看出使用\d + 表的名字即可查看到当前表的信息
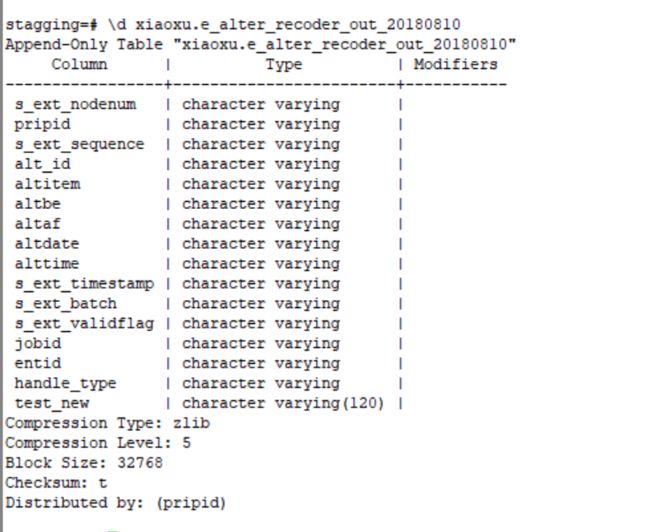
9.1.5.3 查看schema下的所有的表
9.1.5.3.1 使用命令行方式查看
在终端上输入\dt再次按下TAB键即可出现schema的信息
stagging=# \dt
pg_toast. public. t_hash xiaoxu.
查看schema下的所有的表
stagging=# \dt xiaoxu.
List of relations
Schema | Name | Type | Owner | Storage
--------+------------------------------+-------+---------+----------------------
xiaoxu | b_tree_test | table | gpadmin | append only columnar
xiaoxu | e_alter_recoder_out_20180810 | table | gpadmin | append only
xiaoxu | e_alter_recoder_out_20180814 | table | gpadmin | append only columnar
xiaoxu | test_yml | table | gpadmin | heap
(4 rows)
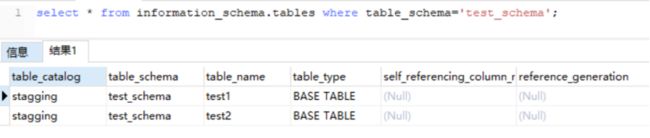
9.1.5.3.2 使用SQL方式查看
stagging=# select * from information_schema.tables where table_schema='test_schema';
table_catalog | table_schema | table_name | table_type | self_referencing_column_name | reference_generation | user_defined_type_catalog | user_defined_type_schema | user_defined
_type_name | is_insertable_into | is_typed | commit_action
---------------+--------------+------------+------------+------------------------------+----------------------+---------------------------+--------------------------+-------------
-----------+--------------------+----------+---------------
stagging | test_schema | test1 | BASE TABLE | | | | |
| YES | NO |
stagging | test_schema | test2 | BASE TABLE | | | | |
| YES | NO |
(2 rows)
9.1.5.4 查询schema下的外部表的列表
select c.relname
from pg_catalog.pg_class c, pg_catalog.pg_namespace n
where
n.oid = c.relnamespace
and n.nspname='main'
and c.relkind='r' and relstorage='x'
main: 代表当前的schema的信息
9.1.5.5 查询schema下的普通表的列表
9.1.5.5.3 获取类型的表
chinadaas=# select distinct relstorage from pg_class ;
relstorage
------------
h
a
x
v
c
(5 rows)
Time: 30.556 ms
参数说明:
a -- 行存储AO表
h -- heap堆表、索引
x -- 外部表(external table)
v -- 视图
c -- 列存储AO表
9.1.5.5.2 获取制定类型的表
select c.relname from pg_catalog.pg_class c, pg_catalog.pg_namespace n where n.oid = c.relnamespace and n.nspname='main' and c.relkind='r' and relstorage in ('h', 'a');
main: 代表当前的schema的信息
9.1.6 查看每个schema的占用大小
select pg_size_pretty(cast(sum(pg_relation_size( schemaname || '.' || tablename)) as bigint)), schemaname
from pg_tables t inner join pg_namespace d on t.schemaname=d.nspname group by schemaname;
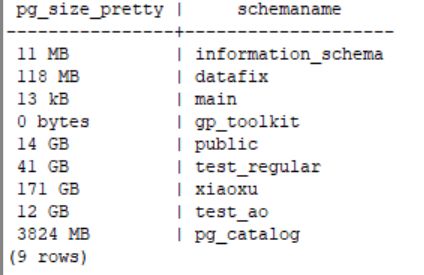
在以上中可以详细的看出每个schema的占用大小。
9.1.7 查看当前正在执行的语句
chinadaas=# select * from gp_toolkit.gp_resq_priority_statement;

rqpdatname : 当前数据库的名字
rqpusename : 当前用户的名字
rqpsession : 当前session的ID
rqpcommand : 当前的命令
rqppriority : 权限信息
rqpweight : 重要级别
rqpquery : 查询的语句
9.1.8 释放表的膨胀空间
只会通知释放空间,不会使用排它锁
vacuum tablename;
以下会全部释放空间,会使用排它锁
vacuum full;
tablename : 表的名字
建议在update之后及时执行vacuum释放表的空间,vacuum full使用时需要谨慎,会占用大量的资源,比较耗时。同事vacuum只是简单的回收空间且令其可以再次使用,通过简单的vacuum可以缓解表的增长,在执行这个命令时,其他的操作也可以执行,因为vacuum没有请求排它锁。
9.1.9 查看集群的配置信息
select * from gp_segment_configuration ORDER BY hostname;

9.1.10 数据存放的路径
select * from pg_filespace_entry;

9.1.11 查看系统的日志
SELECT * FROM gp_toolkit.__gp_log_segment_ext limit 10;

9.1.12 查看索引的占用大小
SELECT soisize/1024/1024 as size_MB, relname as indexname
FROM pg_class, gp_toolkit.gp_size_of_index
WHERE pg_class.oid = gp_size_of_index.soioid
AND pg_class.relkind='i';

9.1.13 修改某个数据库为制度状态
alter database mp_mvt set default_transaction_read_only= on ;
9.1.14 查看集群中那些节点挂了
select * from gp_segment_configuration where status = 'd';
如果没有数据代表没有节点挂。
9.1.15 查看GP对应的PostgreSQL版本信息
stagging=# SELECT VERSION(); version
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
-------------------
PostgreSQL 8.3.23 (Greenplum Database 5.11.1 build commit:540866674a4dd1ef5f19c2670d020e336369dfd2) on x86_64-pc-linux-gnu, compiled by GCC gcc (GCC) 6.2.0, 64-bit compiled on Se
p 20 2018 18:12:07
(1 row)
9.1.16 查看是否锁表
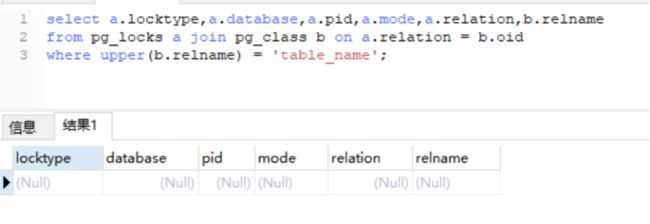
9.1.16.1 查看表中存在的锁
select a.locktype,a.database,a.pid,a.mode,a.relation,b.relname
from pg_locks a join pg_class b on a.relation = b.oid
where upper(b.relname) = 'table_name';
9.1.16.2 杀掉锁住表的进程
以下操作需要特别谨慎
方式一:
SELECT pg_cancel_backend(PID);
这种方式只能kill select查询,对update、delete 及DML不生效
方式二:
SELECT pg_terminate_backend(PID);
这种可以kill掉各种操作(select、update、delete、drop等)操作
9.1.17 查看集群中有哪些用户
SELECT u.usename AS "User name",u.usesysid AS "User ID",
CASE WHEN u.usesuper AND u.usecreatedb THEN CAST('superuser, create
database' AS pg_catalog.text)
WHEN u.usesuper THEN CAST('superuser' AS pg_catalog.text)
WHEN u.usecreatedb THEN CAST('create database' AS
pg_catalog.text) ELSE CAST('' AS pg_catalog.text)
END AS "Attributes" FROM pg_catalog.pg_user u
ORDER BY 1;
User name : 用户名
User ID : 当前用户的ID
Attributes : 当前用户的权限
9.2 常见创建表语句
9.2.1 快速复制一张表
stagging=# create table tablename (like originaltablename);
NOTICE: Table doesn't have 'DISTRIBUTED BY' clause, defaulting to distribution columns from LIKE table
CREATE TABLE
Time: 70.439 ms
tablename : 需要创建的表明
originaltablename : 原始表明
使用like创建的表,只是表结构会与原表一模一样,表的一些特殊属性并不会一样,例如压缩、只增(appendonly)等属性。如果不指定分布键,则默认分布键与原表一样。
9.2.2 重新设计一张表
create table tablename with (appendonly = true, compresstype = zlib, compresslevel = 7
,orientation=column, checksum = false,blocksize = 2097152) as
****
Distributed by (field)
tablename : 需要创建的表明
field : 分布键的字段,也可以是多个
9.3 分析执行计划
9.3.1 查看执行计划
stagging=# EXPLAIN select count(*),id from t_person4insert3 group by id having count(*) > 2;
QUERY PLAN
--------------------------------------------------------------------------------------------
Gather Motion 48:1 (slice1; segments: 48) (cost=0.00..431.00 rows=1 width=16)
-> Result (cost=0.00..431.00 rows=1 width=16)
Filter: (count()) > 2
-> GroupAggregate (cost=0.00..431.00 rows=1 width=16)
Group By: id
-> Sort (cost=0.00..431.00 rows=1 width=8)
Sort Key: id
-> Table Scan on t_person4insert3 (cost=0.00..431.00 rows=1 width=8)
Optimizer status: PQO version 2.75.0
(9 rows)
Time: 17.226 ms
9.3.2 名词解释
t_person4insert3 : 索引的名字,说明此查询已经使用索引了
slice: Greenplum在实现分布式执行计划的时候,需要将SQL拆分成多个切片,每个slice是单裤执行的一部分SQL,每一个广播或者重分布会产生一个切片,每一个切片在每一个数据结点上都会对应的发起一个进程来处理该slice负责的数据,上一层负责该slice的进程会读取下级slice广播或重分布的数据,之后进行相应的计算。
segment: 每个sdw中设置两个primary(greenplum安装时gpinitsystem使用的文件中设置),所以看到的segment是48。
cost: 数据库自定义的消耗单位,通过统计信息来估计SQL消耗。(查询分析是根据analyze的固执生成的,生成之后按照这个查询计划执行,执行过程中analyze是不会变的。所以如果估值和真是情况差别较大,就会影响查询计划的生成。)
rows: 根据统计信息估计SQL返回结果集的行数。
width: 返回结果集每一行的长度,这个长度值是根据pg_statistic表中的统计信息来计算的。
9.4 函数使用
9.4.1 创建函数
9.4.1.1 创建函数方式一
请仔细阅读以下函数的定义与说明
create or replace function sp_ent_test_function(_date text)
returns int
as $$
-- 以下为说明部分
-- 程序名:sp_ent_test_function
-- 用途:测试储存过程
-- 需要传入的表:ods.test_yml,ods.test_regular
-- 参数:_date 当前日期
-- 返回值: 1 正确 其他为错误
-- 需要条件: 需要先执行***储存过程,在执行此过程
-- 版本:v1.0
-- 当前维护人:xiaoxu
-- 创建时间:2018-12-27
declare
-- 定义变量
vs_function_name varchar(50) default null; -- 函数名字
vs_function_return_value int; -- 返回值
vs_num_rows numeric; -- 记录行数
vs_logtype varchar(5) default 'I'; --日志类型 I-正常;W-警告;E-错误
vs_step varchar(8); -- 程序执行的断点的位置
vs_errorcode varchar(10) default ''; --数值型 1 为正常,其他的为异常
vs_data_date varchar(20); -- 数据日期
begin
vs_function_name :='sp_ent_test_function';
vs_step :='01';
vs_logtype :='I';
vs_data_date :=_date;
vs_function_return_value = 1;
vs_errorcode := 1;
-- 复制一张表
drop table if exists xiaoxu.test_function;
create table xiaoxu.test_function with (appendonly = true, compresstype = zlib, compresslevel = 5
,orientation=column, checksum = false,blocksize = 2097152) as
select * from xiaoxu.e_alter_recoder_out_20180810 limit 100
Distributed by (pripid);
GET DIAGNOSTICS vs_num_rows = ROW_COUNT;
raise notice '复制的数量为:%', vs_num_rows;
return vs_function_return_value;
end;
$$ language plpgsql;
9.4.1.2 创建函数方式二
create or replace function write_lo_test (i_bytea bytea)
returns text
as $$
declare
oid_new_lo boolean;
fd_new_lo int;
begin
drop table table3;
insert into table1 values('test--','52.5','2');
EXECUTE 'create table table3 as select * from '||i_bytea||'';
raise notice 'exectue Success....';
return 'exectue Success....';
end;
$$ language plpgsql;
或写成以下形式
create or replace function prc_test(_from_table text,_create_table text)
returns TEXT
as $$
declare
_count varchar;
temp_sql varchar;
BEGIN
temp_sql:='create temp table temp_test as select * from table1';
--
-- EXECUTE 'drop temp table if exixts temp_test';
EXECUTE temp_sql;
-- 删除表
EXECUTE 'drop table if exists '||_create_table||'';
EXECUTE 'create table '||_create_table||' as select * from temp_test';
raise notice 'create table Success..';
return 'create table Success..';
END
$$
LANGUAGE plpgsql VOLATILE
COST 100;
这个的返回值是text类型,使用EXECUTE也可以执行语句
9.4.2 使用函数
只需要使用正常的SQL查询即可,拿创建函数方式一为例,效果如下所示:
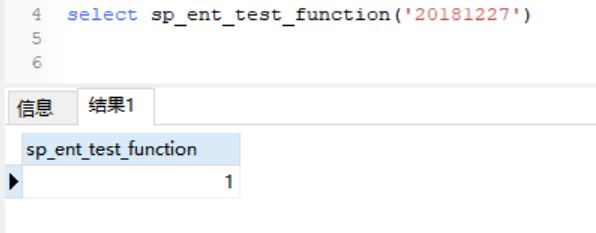

可以看出已经正确的打印出了日志
9.4.3 删除函数
drop function sp_ent_test_function(_date text);
在删除时注意函数的参数问题,因为函数支持重写
9.5 视图使用
9.5.1 视图命名规范
格式:普通视图 v_具体业务含义名称。
9.5.2 视图的定义
视图本身只定义sql语句,实际数据存在于sql定义内容的实体表中。视图本身不保存任何数据,不能在视图上创建索引。
9.5.3 创建及查询视图语句
普通视图语句
CREATE [ OR REPLACE ] [ TEMP | TEMPORARY ] VIEW name [ ( column_name [, ...] ) ]
在schmea下查询视图的列表
select c.relname from pg_catalog.pg_class c, pg_catalog.pg_namespace n where n.oid = c.relnamespace and n.nspname='public' and c.relkind like '%v%';
9.5.4 创建视图
stagging=# create view v_t_person as select * from t_person where id=1000;
CREATE VIEW
Time: 85.100 ms
stagging=# select * from v_t_person;
id | name
------+---------------
1000 | atlasdata1000
(1 row)
Time: 25.020 ms
9.5.5 查看视图结构
stagging=# \d v_t_person;
View "public.v_t_person"
Column | Type | Modifiers
--------+------------------------+-----------
id | bigint |
name | character varying(255) |
View definition:
SELECT t_person.id, t_person.name
FROM t_person
WHERE t_person.id = 1000;
9.6 索引使用
9.6.1 支持的索引类型
Greenplum支持 b-tree、bitmap、hash索引、函数索引等。Bitmap index索引的列,不能有太多的value,最好是100到10万个value,也就是说,这样的表的bitmap索引有100到10万条bit串。
9.6.2 获取索引的列表
stagging=# SELECT n.nspname as "Schema", c.relname as "Name", c2.relname as "Table"
FROM pg_catalog.pg_class c
JOIN pg_catalog.pg_roles r ON r.oid = c.relowner
LEFT JOIN pg_catalog.pg_namespace n ON n.oid = c.relnamespace
LEFT JOIN pg_catalog.pg_index i ON i.indexrelid = c.oid
LEFT JOIN pg_catalog.pg_class c2 ON i.indrelid = c2.oid
WHERE c.relkind IN ('i','')
AND n.nspname NOT IN ('pg_catalog', 'pg_toast', 'pg_aoseg')
AND c2.relname NOT LIKE '%_prt_%'
ORDER BY 1,2;
Schema | indexName | Table
--------------+-----------------------+----------------------------------
test_regular | idx_tb | tb
test_regular | test_json_pkey | test_json
xiaoxu | idx_tb | tb
xiaoxu | test_pkey | test
(5 rows)
Time: 10.263 ms
Schema : 表示schrma的名字
indexName : 索引的名字
Table : 涉及的表的名字
9.6.3 bitmap索引的使用
9.6.3.1 获取测试表的信息
stagging=# select pg_size_pretty(pg_relation_size('xiaoxu.e_alter_recoder_out_20180810_com'));
pg_size_pretty
----------------
11 GB
(1 row)
Time: 33.207 ms
stagging=# select count(*) from xiaoxu.e_alter_recoder_out_20180810_com;
count
-----------
156784862
(1 row)
Time: 1849.456 ms
9.6.3.2 查看不使用索引耗时
stagging=# select count(*) from xiaoxu.e_alter_recoder_out_20180810_com where pripid='34994E73838D417E9E4677C4ADC3AFB6';
count
-------
3
(1 row)
Time: 1818.625 ms
不适用索引在156784862行中正则匹配34994E73838D417E9E4677C4ADC3AFB6耗时 1818.625 ms
9.6.3.3 创建索引
stagging=#create index index_e_alter_recoder_test on xiaoxu.e_alter_recoder_out_20180810_com using bitmap (pripid);
或
stagging=# create index index_e_alter_recoder on xiaoxu.e_alter_recoder_out_20180810_com (pripid);
CREATE INDEX
Time: 40486.832 ms
index_e_alter_recoder : 索引的名字
xiaoxu.e_alter_recoder_out_20180810_com : 表明
pripid : 添加索引的列
创建索引耗时 40486.832 ms,大概40多s
9.6.3.4 查看使用索引耗时
stagging=# select count(*) from xiaoxu.e_alter_recoder_out_20180810_com where pripid='34994E73838D417E9E4677C4ADC3AFB6';
count
-------
3
(1 row)
Time: 16.225 ms
stagging=# select count(*) from xiaoxu.e_alter_recoder_out_20180810_com where pripid='34994E73838D417E9E4677C4ADC3AFB6';
count
-------
3
(1 row)
Time: 15.415 ms
stagging=# select count(*) from xiaoxu.e_alter_recoder_out_20180810_com where pripid='34994E73838D417E9E4677C4ADC3AFB6';
count
-------
3
(1 row)
Time: 15.094 ms
仔细看查询三次最高用时16.225 ms比不用索引的 1818.625 ms节省113倍的时间,值得拥有,看来晚上不用加班了.....
9.6.3.5 删除索引
stagging=# drop index xiaoxu.index_e_alter_recoder;
DROP INDEX
Time: 290.728 ms
注意在删除索引时一定要加上schema的名字,默认的是找public下的索引
9.6.3.6 查看执行计划
stagging=# explain select count(*) from xiaoxu.e_alter_recoder_out_20180810_com where pripid='34994E73838D417E9E4677C4ADC3AFB6';
WARNING: gpmon - bad magic 0
QUERY PLAN
-------------------------------------------------------------------------------------------------------------
Aggregate (cost=0.00..204.38 rows=1 width=8)
-> Gather Motion 48:1 (slice1; segments: 48) (cost=0.00..204.38 rows=1 width=8)
-> Aggregate (cost=0.00..204.38 rows=1 width=8)
-> Bitmap Table Scan on e_alter_recoder_out_20180810_com (cost=0.00..204.38 rows=1 width=1)
Recheck Cond: pripid::text = '34994E73838D417E9E4677C4ADC3AFB6'::text
-> Bitmap Index Scan on index_e_alter_recoder (cost=0.00..0.00 rows=0 width=0)
Index Cond: pripid::text = '34994E73838D417E9E4677C4ADC3AFB6'::text
Optimizer status: PQO version 2.75.0
(8 rows)
Time: 25.395 ms
在以上看出已经正确的使用了bitmap索引
9.6.4 b-tree索引的使用
9.6.4.1 b-tree索引的特点
B-tree索引适合所有的数据类型,支持排序,支持大于小于,等于等运算操作符的搜索。
索引与递归查询的结合,还能实现快速的稀疏检索。
9.6.4.2 获取测试表的信息
stagging=# select pg_size_pretty(pg_relation_size('xiaoxu.b_tree_test'));
pg_size_pretty
----------------
9703 MB
(1 row)
Time: 32.202 ms
stagging=# select count(*) from xiaoxu.b_tree_test;
count
-----------
156784862
(1 row)
Time: 1827.218 ms
在以上中可以看出了测试表中的大小为9703 MB,156784862行的数据
需要创建索引列的信息
![]()
在以上可以看出s_ext_nodenum是int4类型
9.6.4.3 查看不使用索引时的耗时
stagging=# select count(*) from xiaoxu.b_tree_test where s_ext_nodenum =310000 limit 10;
count
----------
11335472
(1 row)
Time: 1345.852 ms
不适用索引的耗时为1345.852 ms
9.6.4.4 创建索引
stagging=# create index idx_t_btree_1 on xiaoxu.b_tree_test using btree (s_ext_nodenum);
CREATE INDEX
Time: 19165.698 ms
9.6.4.5 查看使用索引的耗时
stagging=# select count(*) from xiaoxu.b_tree_test where s_ext_nodenum =310000 limit 10;
count
----------
11335472
(1 row)Time: 640.843 ms
使用索引的耗时为640.843 ms是不适用索引的耗时1345.852 ms的2倍
9.6.4.6 查看执行计划信息
# explain select count(*) from xiaoxu.b_tree_test where s_ext_nodenum =310000 limit 10;
QUERY PLAN
----------------------------------------------------------------------------------------------
Limit (cost=0.00..1212.89 rows=1 width=8)
-> Aggregate (cost=0.00..1212.89 rows=1 width=8)
-> Gather Motion 48:1 (slice1; segments: 48) (cost=0.00..1212.89 rows=1 width=8)
-> Aggregate (cost=0.00..1212.89 rows=1 width=8)
-> Table Scan on b_tree_test (cost=0.00..1212.89 rows=1306541 width=1)
Filter: s_ext_nodenum = 310000
Optimizer status: PQO version 2.75.0
(7 rows)
Time: 25.948 ms
在以上中可以看出已经正确的使用了索引,使用的b_tree_test索引
9.6.5 查看索引大小
SELECT soisize/1024/1024 as size_MB,relname as indexname,soiindexname,soitableschemaname,soitablename
FROM pg_class, gp_toolkit.gp_size_of_index
WHERE pg_class.oid = gp_size_of_index.soioid
AND pg_class.relkind='i';

9.7 引用第三方库
9.8 常用设置
9.8.1 终端设置字符编码
设置终端编码
stagging=# \encoding UTF8
查看终端编码
stagging=# \encoding
UTF8
9.8.2 设置终端执行时长
第一次是开启运行时长
stagging=# \timing
Timing is on.
第二次是关闭运行时长
stagging=# \timing
Timing is off.