建行数据从Teradata迁移到Greenplum大揭秘
了解更多Greenplum技术干货,欢迎访问Greenplum中文社区网站
绿树阴浓夏日长 ,楼台倒影入池塘。又是一年盛夏了,忽然想起了三年前的盛夏,和一帮建行的兄弟们在机房挥汗如雨,加班加点搞“迁移长征”的场景。
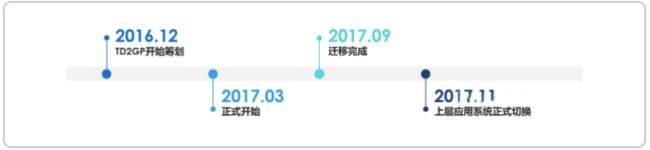
建行的数据平台从Teradata迁移到Pivotal Greenplum(现VMware Greenplum)挺早之前就开始了,本文所说的就是Teradata迁移到Greenplum第一期,从2016年的12月开始筹划,2017年3月算是正式开始,2017年9月迁移完成,2017年11月上层应用系统正式切换。
由于当时是第一次做这种大型的迁移,行内没有过先例,业界也没有找到这么大规模迁移的案例。里面有多少坑、要多久、需要多少人,完全没有个参考。所以当时中心领导和处室领导决定先找个团队做个一期项目,趟出一条路,产出一些迁移工具、迁移经验、迁移的方法论,为后面的迁移寻找最快路径。
最终这个一期的迁移派到了P9平台团队。建行的P9平台团队是专注于以技术服务仓库、数据线各项目的,技术上有沉淀、有积累,但对数据模型、仓库内加工的应用不是很熟悉。所以当时接到这个任务时,有点“风萧萧兮易水寒”的感觉,但对即将到来的挑战也是充满期待的,毕竟这种迁移怎么说也是业内首次,做好了就是业内领先,甚至国际领先嘛,所以我们当时的内心还是蛮激动的。今天我们将为大家逐一揭秘迁移的整个过程。
第一部分 何以一年完成海量数据“长征”
一、为什么要迁移
建行的数据平台为什么要进行Teradata到Greenplum的迁移?这个问题的答案主要来自以下两个方面:
1.新一代要求的开放性
由于Teradata采用一体机,且系统相对封闭,不符合新一代建设原则,所以需要寻找基于x86的开放数据处理产品。经过充分的调研、选型测试、专家评审,最终确定新一代大数据处理产品采用Pivotal Greenplum。
2.当时现状
由于前面的原因,决定了建行后期不会再大规模采购Teradata数据库,但数据建设的需求却不会停,在迁移开始之前,建行的两套Teradata库里面跑了大几十个系统,各个系统不断的在增加数据接入、数据加工任务,所以导致Teradata的负载压力越来越大,上面跑的应用加工经常发生延迟、跑不动,尤其是上线时候,更是亚历山大!
在迁移开始前,像反洗钱这样的复杂系统,时常发生报送延迟的情况,严重的时候甚至延迟到一周以上。改善反洗钱监管报送时效性刻不容缓。在这样的背景下,中心和处室领导,决定开始Teradata迁移Greenplum的“长征之旅”。
二、如何迁移
首先,还是要明确要做什么,到底迁移哪一些。 当时领导选择了反洗钱作为迁移工作的第一期,因为当时反洗钱延迟影响比较大,又是比较重要又比较复杂的系统,如果迁移完成,既能提升反洗钱系统的时效性,又能大量减轻Teradata数据库压力!为了能够更加彻底达到迁移的效果,我们选择了从源数据接入、仓库各层加工、反洗钱基础数据加工一整条线整体迁移的方案。

接着需要梳理具体有哪些工作,哪些事项,再对各项工作进行计划安排。当时我们梳理出主要工作有范围分析、环境准备、数据模型迁移、数据初始化、脚本迁移、调度迁移、数据一致性校验、应用切换等工作。

当然,首先要清楚的是,迁移绝对不是一次成功的,必然是要迭代进行的,一定是迁移-数据校验-发现问题改进-迁移-数据检验-发现问题改进-….
具体的各项工作如何开展,我们做了哪些工作将在后续的系列文章中陆续讲解,先就各项工作做简单介绍:
1.范围分析
范围分析工作看着比较虚,实则非常重要,在迁移迭代过程的深入中,我们越发感觉范围分析精确的重要性。因为如果在范围分析阶段,少分析了一张表,甚至一个视图,这种缺失经常在最终的数据校验阶段才能被发现,这意味着,必须有下一轮的迁移迭代,这个成本无疑是巨大的。
2.环境准备
主要是测试环境和生产环境中数据库、ETL、调度等环境的准备。
3.数据模型迁移
模型这个词用的地方太多了,容易产生歧义,此处的模型指的是表、视图等结构。要实现迁移,首先要把模型迁移到Greenplum。
4.数据初始化
主要是将Teradata上的初始化截面数据复制到Greenplum中,作为初始化数据。
5.脚本迁移
脚本的迁移其实就是语法的迁移。整个迁移中,脚本迁移是重中之重,虽然不是耗时最长、最困难的,但一定是最具技术挑战的。所幸,经过我们P9平台迁移团队的努力,最终制作出了实现95%以上的脚本自动迁移工具。在此需要特别感谢林舒杨同学,在我们原本只能做到90%,实在无法更进一步的情况下,找到林舒杨同学,其凭借强大的技术能力硬是生生的做到了95%以上。
6.调度迁移
主要是将原本在数据仓库调度系统中的作业配置迁移到P9的新一代调度系统中。
7.数据一致性校验
如果脚本迁移是最具技术挑战的环节,那么数据一致性校验就是最困难、耗时耗力最大的一个环节。迁移完后,经常被邀请去和别的团队交流,我经常会说一个数字‘334’,意思是如果迁移时间是10分,那么数据初始化要占3分,所有的模型迁移、脚本迁移、作业迁移、性能优化等一堆工作占3分,最后的4分都是在做数据的一致性校验,而且这还是在我们的数据一致性校验工具在做到极致的情况下。整个迁移产出的一系列工具中,让我们最有成就感、做得最极致的,也是这个数据一致性校验工具。
8.应用切换
应用系统在确认迁移数据质量满足其加工需求后,将数据源从Teradata切换成Greenplum。
三、迁移成果如何
迁移的过程还是蛮艰苦的,尤其是数据一致校验阶段,感觉就像是长征路上的过雪山、过沼泽地,但最终我们迁移团队顺利的到达了延安。经过半年多的努力,最终我们成功迁移了300T左右的初始化数据,1000多个物理表,1500多个作业,1200多个脚本,迁移系统至今稳定运行。
对迁移系统影响:
反洗钱系统切换到我们迁移后的Greenplum仓库数据后,这两年甚少听到报送延迟问题,这与迁移之前时常报送延迟一周以上的情况对比,效果是非常明显的。而且切换后,整个反洗钱日常报送时效性提升了78小时,月末提升23天(2018年1月统计数字)。
对Teradata影响:
反洗钱系统切换到Greenplum以后,正常运行了一段时间后,Teradata下线了一些不再需要加工的作业,并且减少了原本反洗钱每天需要从Teradata复制基础数据的大量复制作业,整个Teradata的负载下降也相当明显,Teradata上的各应用加工时效也实现一定程度提升。
对后续TD2GP迁移项目影响:
作为第一期项目,我们成功的制作出了一系列迁移工具,包括自动化脚本迁移工具、自动化模型迁移工具、自动化数据一致性校验工具,使后续的迁移项目直接使用工具实现自动化的迁移,极大地减少了人力迁移成本,缩短了迁移周期,实现了敏捷迁移。此外产出了整体迁移方案,使后续迁移项目实现清晰的项目管控,项目、成本计划,有的放矢!
第二部分 从无例可循到创造先例的技术路径
数据模型迁移和数据迁移都紧密依赖于范围分析,需要根据范围分析的结果进行工作量评估、方案设计、计划排期等相关工作,接下来,我们将介绍范围分析、数据模型迁移、数据迁移模块的相关实施经验,以及一些经验总结。
一、范围分析
范围分析是整个迁移工作的第一步,也是非常重要的一步。关于它的重要性,在第一期有过简单的说明。范围分析完不完备,准不准确,影响到后面迭代迁移次数的多少,范围分析相关工作做得完备、准确,那么会减少真正迁移时因模型缺失或作业缺失等范围缺失而导致的返工。既然范围分析工作这么重要,那该如何开展呢?
一般而言,迁移之初都需要明确具体的迁移目标。我们当时的目标就是把反洗钱基础数据迁移到Greenplum上进行加工,并实现端到端迁移,使得反洗钱加工完全不需要Teradata。因为是要实现端到端的迁移,所以需要根据已知的范围逆向逐层分析出来。

一.范围分析步骤
1. 已知范围识别
对于本案例来说就是FXQ基础数据及相关模型和作业配置等。
2. 作业范围分析
通过作业依赖关系分析出数据仓库的M层、P层、S层等各层需迁移的作业范围清单。作业范围分析一般可以通过作业依赖血缘图,逆向分析出各层需迁移的相关作业,如下图。

3. 脚本范围分析
由于作业配置与脚本有一定映射关系,所以可以根据前面步骤得到的需迁移作业范围清单,分析出需迁移的脚本范围清单。
4. 模型范围分析
一般而言,由于各个脚本中使用的数据模型的方式是固定,且有限的,所以可以通过关键字匹配识别出脚本中使用的所有数据模型。因此模型范围的分析是通过写脚本工具,实现对上一步骤得到的需迁移脚本范围清单中所有脚本的批量采集,并获得需迁移的模型范围清单。
5. 初始化数据范围分析
初始化数据范围分析其实就是需迁移数据范围分析。这步会比较复杂,因为Teradata负载太高,数据迁移速度不高,所以数据迁移范围需要尽可能的小,同时又要满足应用加工需求。也就是说要在满足应用加工需求的情况下,获取数据迁移范围的最小集。这就需要范围分析人员了解应用加工模型,以及应用加工对各个数据实体精确的使用范围,但通常迁移人员不是能很了解应用加工,所以只能深入各个脚本,通过阅读代码去获取精确的数据迁移范围。
二.经验总结
通过以上的范围分析,一般能获取需迁移的作业范围、脚本范围、模型范围、和数据范围,但这些范围可能无法一下子做到完全准确,需要后面迁移的过程中不断地迭代,不断地完善。接下来根据现有的经验,总结范围分析这个阶段的一些主要问题:
1. 作业依赖不能完全体现实际上的加工依赖,导致部分需迁移范围不能通过最开始的范围分析确定出来,有些缺失的范围需在后续的测试、数据验证阶段发现,如下图。

- 除对应用加工模型有经验丰富人员外,初始化数据范围分析通常需要范围分析人员通过深入脚本阅读代码的方式来分析、确定初始化的数据范围,效率较低,且容易有遗漏、缺失。
二、数据模型迁移
数据模型迁移,其实就是把Greenplum的物理表结构和视图结构迁移到Teradata上,简单地说就是在Teradata上创建出和Greenplum上一样的表或者视图。数据模型迁移主要分如下几个步骤:

一.范围分析
分析出具体有哪些表或者视图,这在前一节有详细的描述,即可以通过写脚本工具的方式,从需要迁移的脚本中批量获取到需要迁移的表和视图清单。但这种方式只能识别面上一层的模型,也就是在脚本中有直接使用到的表和视图,至于这些表和视图是怎么加工出来的,脚本工具就没办法获取到。如果是物理表,它的数据血缘可能会体现在作业依赖上,当然也不一定完全准确。但更重要的是分析出来的需要迁移的视图或表是依赖于其他视图或物理表生成的,这个依赖关系不会体现在作业依赖上,只体现在模型语句中,所以这需要在后续的转换后模型创建步骤中,逐步发现缺失模型,不断完善分析出的数据模型迁移范围。
二.批量模型转换
根据Teradata和Greenplum语法差异,制作出模型自动转换工具,并利用数据模型自动转换工具,批量实现物理表和视图的迁移。
三.转换后模型创建
为什么需要将转换后模型创建单独成一个步骤?是因为这一过程通常需要耗费一定的时间去迭代才能最终将转换后的模型都创建成功。视图创建的时候,容易出现该视图所需要的其他视图或者物理表未迁移,而导致该视图创建不成功的情况。这就需要将该视图需要的其他视图或者物理表加入到迁移范围中,再重新梳理更新需要迁移的作业范围、脚本范围、模型范围和数据范围。更新完后,再将新分析出来并转换完后的模型再进行创建,若又发现有模型的缺失,则需要再更新各迁移范围,依此类推,不断地迭代更新迁移范围。
四.脚本空跑
脚本空跑也是验证数据模型迁移范围是否完备的重要一步,只有真正的脚本空跑过了,才能算是数据模型迁移范围的基本确定(当然,后面数据验证的时候,也可能会发现一些模型的缺失,但一般不会太多)。
三、数据初始化
数据初始化主要是将Teradata上的初始化截面数据复制到Greenplum中,作为初始化数据。这方面建行有个占优的地方,就是P9平台本身有为各个数据线系统提供了数据同步组件,这个组件既能实现全量或者增量将各类型数据库(GP/TD/ORACLE/HD)的数据非常高效地同步到各类型数据库(GP/TD/ORACLE/HD)中去。所以在做数据迁移的时候,可以复用P9平台的数据同步组件,当然,为了适应迁移工作的特殊性,在该组件的基础上,额外做了一定的改造。主要是为了数据迁移工作的效率,去掉了该数据同步组件的自动数据校验功能,并改为由人工批量校验方式来保证数据迁移的准确性。接下来阐述初始化数据迁移工作主要步骤。

一.数据迁移步骤
1. 范围分析
分析确认哪些表需要做数据初始化,并且尽量精确每张表在满足加工用数的需求下的最小初始化量,即确认初始化时源表的最精准筛选条件。
2. 数据搬迁前处理
主要有两个工作,其一是确定初始化截面日期,即以哪个业务日期作为初始化的截面日期。在截面日期之前的数据,通过数据初始化的方式,用数据迁移工具,从Teradata同步到Greenplum;在初始化截面日期以后的数据,在Greenplum上以加工跑批的方式生成。其二是当前表备份,因为数据初始化是长期过程,当前表有时点问题,如果某张当前表没有及时备份,那么等当前表开始数据初始化迁移时,可能已经过了那个时点,那么里面的初始化数据就是错误的,所以当前表需要及时备份,初始化时从备份表迁移数据。
3. 数据搬迁
将数据从Teradata数据库复制到Greenplum数据库;大表容易失败,需拆分为小表复制。
4. 数据验证
前面有介绍到,迁移过程中,为了保证数据迁移的效率,去除了原本P9数据同步工具中的自动数据校验功能,改为由人工批量的方式去校验。所以,需要批量进行验证初始化结果、范围是否准确,主要是确认各张表的各个批次是否有丢失,每个批次数据量是否准确。
5. 数据搬迁后处理
这步主要有两个工作,其一是拉链表退链,由于初始化截面后的数据需要在初始化数据的基础上进行跑批加工,所以需要将已经闭链的截面数据进行退链处理。其二是初始化数据去有空格处理等,由于Teradata可以自动去有空格,而Greenplum无法自动去有空格,为了保证数据加工的一致性,需要对迁移后的数据统一做去有空格处理。
二.经验总结
根据我们迁移经验,总结了数据初始化迁移工作中遇到的主要问题:
-
初始化数据体量大,初始化效率一般,耗时久
-
单表数据量大,容易超时等失败
-
Teradata负载过高,容易报资源不足
据此,我们为后面做类似迁移工作的实施团队,总结了几点优化建议,希望对各位有用:
1. 初始化路径优化:
像我们当时来说,我们有两套Teradata集群,TD2系和TD6系。TD2系负载较高,所以如果在TD6系上存在的表尽量从TD6系迁移,如果模型Greenplum集群上有,且能满足数据初始化需求,则最好直接从Greenplum集群复制。
2. 初始化范围优化:
在不影响用数情况下,精简初始化量。这在前面强调过好几次了,因为确实很重要!实在是趟过太多这方面的坑!
3.初始化工具优化:
初始化数据迁移工具尽量摒弃非必须功能,生成专门初始化工具,做到“短小精悍”,提升效率。
