Bert实战--阅读理解(一)
run_squad解读
SquadExample
class SquadExample(object):
def __init__(self,
qas_id,
question_text,
doc_tokens,
orig_answer_text=None,
start_position=None,
end_position=None,
is_impossible=False):
self.qas_id = qas_id。#qa模块的ID
self.question_text = question_text #问题
self.doc_tokens = doc_tokens #文本
self.orig_answer_text = orig_answer_text #原始答案
self.start_position = start_position #答案的开始位置
self.end_position = end_position #答案的结束位置
self.is_impossible = is_impossible #是否存在答案
定义了一个输入样本Squad的格式
InputFeatures
class InputFeatures(object):
def __init__(self,
unique_id,
example_index,
doc_span_index,
tokens,
token_to_orig_map,
token_is_max_context,
input_ids,
input_mask,
segment_ids,
start_position=None,
end_position=None,
is_impossible=None):
self.unique_id = unique_id #每个特征的ID
self.example_index = example_index #example的索引,建立feature 和example的对应
self.doc_span_index = doc_span_index #文本片段的索引,该feature对应的doc_span索引
self.tokens = tokens #文本
self.token_to_orig_map = token_to_orig_map #每一个token在原始doc_token的索引
self.token_is_max_context = token_is_max_context #该位置的token在当前span里面是否是上下文最全的
self.input_ids = input_ids #输入的ID
self.input_mask = input_mask #输入的
self.segment_ids = segment_ids。#输入属于第几句话的ID
self.start_position = start_position #答案的开始位置(这里指的是在输入文本片段中的位置,同时也包含了问题的长度)
self.end_position = end_position #答案结束的位置
self.is_impossible = is_impossible #是否有答案
定义了输入的样本特征
read_squad_examples
def read_squad_examples(input_file, is_training):
"""Read a SQuAD json file into a list of SquadExample."""
with tf.gfile.Open(input_file, "r") as reader:
input_data = json.load(reader)["data"]
def is_whitespace(c):
if c == " " or c == "\t" or c == "\r" or c == "\n" or ord(c) == 0x202F:
return True
return False
examples = []
for entry in input_data:
#entry中有title 和 paragraph
for paragraph in entry["paragraphs"]: #遍历这篇文章的每一个段落
paragraph_text = paragraph["context"] #这个段落的文本内容
doc_tokens = [] #文本的token,相当于split操作
char_to_word_offset = [] #列表,存储每个字母中属于第几个单词
prev_is_whitespace = True
for c in paragraph_text: #遍历段落中每一个字母,按照一个字母一个字母加入到doc_tokens
if is_whitespace(c):
prev_is_whitespace = True
else:
if prev_is_whitespace:
doc_tokens.append(c)
else:
doc_tokens[-1] += c
prev_is_whitespace = False
char_to_word_offset.append(len(doc_tokens) - 1)
for qa in paragraph["qas"]: 遍历每个qa
qas_id = qa["id"]
question_text = qa["question"]
start_position = None
end_position = None
orig_answer_text = None
is_impossible = False
if is_training:
if FLAGS.version_2_with_negative:
is_impossible = qa["is_impossible"]
if (len(qa["answers"]) != 1) and (not is_impossible):
raise ValueError(
"For training, each question should have exactly 1 answer.")
if not is_impossible:
answer = qa["answers"][0]
orig_answer_text = answer["text"]
answer_offset = answer["answer_start"]
answer_length = len(orig_answer_text)
start_position = char_to_word_offset[answer_offset]
end_position = char_to_word_offset[answer_offset + answer_length -
1]
# Only add answers where the text can be exactly recovered from the
# document. If this CAN'T happen it's likely due to weird Unicode
# stuff so we will just skip the example.
#
# Note that this means for training mode, every example is NOT
# guaranteed to be preserved.
actual_text = " ".join(
doc_tokens[start_position:(end_position + 1)])
cleaned_answer_text = " ".join(
tokenization.whitespace_tokenize(orig_answer_text))
if actual_text.find(cleaned_answer_text) == -1:
tf.logging.warning("Could not find answer: '%s' vs. '%s'",
actual_text, cleaned_answer_text)
continue
else:
start_position = -1
end_position = -1
orig_answer_text = ""
example = SquadExample(
qas_id=qas_id,
question_text=question_text,
doc_tokens=doc_tokens,
orig_answer_text=orig_answer_text,
start_position=start_position,
end_position=end_position,
is_impossible=is_impossible)
examples.append(example)
return examples
定义了读取数据的方法,将数据放入到example中
读取的input_data的形式:

遍历每个段落的字母,将其加入到doc_token中,char_to_word_offset列表存储该字母属于第几个token。

一个example的例子:

convert_examples_to_features
def convert_examples_to_features(examples, tokenizer, max_seq_length,
doc_stride, max_query_length, is_training,
output_fn):
"""Loads a data file into a list of `InputBatch`s."""
#加载数据,转换成batch size 的输入特征
#将example转换成feature [CLS]问题[SEP]阅读材料片段[SEP]
unique_id = 1000000000
for (example_index, example) in enumerate(examples):
query_tokens = tokenizer.tokenize(example.question_text)
if len(query_tokens) > max_query_length:
#对每个问题进行max_query_length判断,超过最大长度则截断
query_tokens = query_tokens[0:max_query_length]
tok_to_orig_index = []
orig_to_tok_index = []
all_doc_tokens = []
for (i, token) in enumerate(example.doc_tokens):
#example.doc_tokens的token是一个paragraph单词组成的list['','',]
orig_to_tok_index.append(len(all_doc_tokens))
sub_tokens = tokenizer.tokenize(token)
#这里对paragraph单词用各个模型设计的tokenizer分词法再进行分词。
for sub_token in sub_tokens:
tok_to_orig_index.append(i)
#这里是tokenizer之后 第sub_token对应的原始单词的index
all_doc_tokens.append(sub_token)
#这里添加用tokenizer分词之后的tokens
# 下面这一段是得到通过model.tokenizer分词之后的答案所在位置
tok_start_position = None
tok_end_position = None
if is_training and example.is_impossible: #若是训练且没答案
tok_start_position = -1
tok_end_position = -1
if is_training and not example.is_impossible:#若是训练且有答案
tok_start_position = orig_to_tok_index[example.start_position]
#根据example.start_position(文本中答案的开始位置)找到切分后 all_doc_tokens中对应的答案开始位置
if example.end_position < len(example.doc_tokens) - 1:
tok_end_position = orig_to_tok_index[example.end_position + 1] - 1
else:
tok_end_position = len(all_doc_tokens) - 1
# 获取tokenizer之后答案所在位置
(tok_start_position, tok_end_position) = _improve_answer_span(
all_doc_tokens, tok_start_position, tok_end_position, tokenizer,
example.orig_answer_text)
#主要是将 (1895-1943) 处理为 ( 1895 - 1943 )
# The -3 accounts for [CLS], [SEP] and [SEP]
max_tokens_for_doc = max_seq_length - len(query_tokens) - 3
#max_tokens_for_doc可以允许的文章的长度
# We can have documents that are longer than the maximum sequence length.
# To deal with this we do a sliding window approach, where we take chunks
# of the up to our max length with a stride of `doc_stride`.
# 我们有可能会有比maximum sequence length 更长的 documents,为了处理这种情况,
# 我们做一个滑动窗口,我们取一个达到我们最大长度的窗口,
#doc_span,将超过最大长度的文件进行窗口移动截断成多个片段
_DocSpan = collections.namedtuple( # pylint: disable=invalid-name
"DocSpan", ["start", "length"])
doc_spans = []
start_offset = 0
while start_offset < len(all_doc_tokens):
length = len(all_doc_tokens) - start_offset
if length > max_tokens_for_doc:
length = max_tokens_for_doc
doc_spans.append(_DocSpan(start=start_offset, length=length))
if start_offset + length == len(all_doc_tokens):
break
start_offset += min(length, doc_stride)
#把每篇文章剪裁成doc_spans=[[start,length],[start,length].......]
#若文章的长度超过max_tokens_for_doc,则用长度为doc_stride的窗口在文章上面滑动
for (doc_span_index, doc_span) in enumerate(doc_spans):
tokens = []
token_to_orig_map = {}
token_is_max_context = {}
segment_ids = []
tokens.append("[CLS]")
segment_ids.append(0)
for token in query_tokens:
tokens.append(token)
segment_ids.append(0)
tokens.append("[SEP]")
segment_ids.append(0)
#[cls]+问题+[sep]
#segment_id[0 0 0 0 0 0]
for i in range(doc_span.length): #遍历这个doc_span中的每个token
split_token_index = doc_span.start + i
token_to_orig_map[len(tokens)] = tok_to_orig_index[split_token_index]
#token_to_orig_map 是每一个token在原始doc_token的索引
is_max_context = _check_is_max_context(doc_spans, doc_span_index,
split_token_index)
#返回当前这个token最好的文本片段的索引值
token_is_max_context[len(tokens)] = is_max_context
tokens.append(all_doc_tokens[split_token_index])
segment_ids.append(1)
tokens.append("[SEP]")
segment_ids.append(1)
#[cls]+问题[sep]+第一个文本片段+[sep]
#segment_id[0 0 0 0 0 0 1 1 1 1 1 1]
input_ids = tokenizer.convert_tokens_to_ids(tokens)
#把token转换成id
# The mask has 1 for real tokens and 0 for padding tokens. Only real
# tokens are attended to.
input_mask = [1] * len(input_ids)
# Zero-pad up to the sequence length.若长度小于sequence length
while len(input_ids) < max_seq_length:
input_ids.append(0)
input_mask.append(0)
segment_ids.append(0)
assert len(input_ids) == max_seq_length
assert len(input_mask) == max_seq_length
assert len(segment_ids) == max_seq_length
start_position = None
end_position = None
if is_training and not example.is_impossible:#有答案
# For training, if our document chunk does not contain an annotation
# we throw it out, since there is nothing to predict.
doc_start = doc_span.start
doc_end = doc_span.start + doc_span.length - 1
out_of_span = False #判断答案的位置是否超过文本片段的范围
if not (tok_start_position >= doc_start and
tok_end_position <= doc_end):
out_of_span = True
if out_of_span: #若答案不在这个文本范围内,则答案开始和结束位置设为0
start_position = 0
end_position = 0
else:
doc_offset = len(query_tokens) + 2 #句子的长度加上[sep]和[cls]
start_position = tok_start_position - doc_start + doc_offset
#开始位置要包括句子的长度 这个start_position计算的是在这个序列doc_span中答案的开始位置
end_position = tok_end_position - doc_start + doc_offset
#结束位置要包括句子的长度
if is_training and example.is_impossible:#没有答案
start_position = 0
end_position = 0
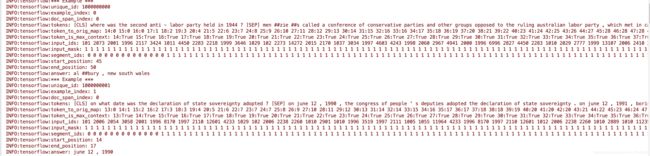
if example_index < 20:
tf.logging.info("*** Example ***")
tf.logging.info("unique_id: %s" % (unique_id))
tf.logging.info("example_index: %s" % (example_index))
tf.logging.info("doc_span_index: %s" % (doc_span_index))
tf.logging.info("tokens: %s" % " ".join(
[tokenization.printable_text(x) for x in tokens]))
tf.logging.info("token_to_orig_map: %s" % " ".join(
["%d:%d" % (x, y) for (x, y) in six.iteritems(token_to_orig_map)]))
tf.logging.info("token_is_max_context: %s" % " ".join([
"%d:%s" % (x, y) for (x, y) in six.iteritems(token_is_max_context)
]))
tf.logging.info("input_ids: %s" % " ".join([str(x) for x in input_ids]))
tf.logging.info(
"input_mask: %s" % " ".join([str(x) for x in input_mask]))
tf.logging.info(
"segment_ids: %s" % " ".join([str(x) for x in segment_ids]))
if is_training and example.is_impossible:#没答案
tf.logging.info("impossible example")
if is_training and not example.is_impossible:#有答案
answer_text = " ".join(tokens[start_position:(end_position + 1)])
tf.logging.info("start_position: %d" % (start_position))
tf.logging.info("end_position: %d" % (end_position))
tf.logging.info(
"answer: %s" % (tokenization.printable_text(answer_text)))
feature = InputFeatures(
unique_id=unique_id,
example_index=example_index,
doc_span_index=doc_span_index,
tokens=tokens,
token_to_orig_map=token_to_orig_map,
token_is_max_context=token_is_max_context,
input_ids=input_ids,
input_mask=input_mask,
segment_ids=segment_ids,
start_position=start_position,
end_position=end_position,
is_impossible=example.is_impossible)
# Run callback回调函数主要作用是进行特征写入
output_fn(feature)
unique_id += 1
定义了将example转换成feature的方法。
tok_to_orig_index列表中是切分后的单词对应的索引
orig_to_tok_index列表是每一个单词切分后加入all_doc_token的长度


当文本过长的时候,用一个滑动窗口上面截取最大的长度
输入成为:
[cls]问题[sep]文本片段1[sep]
[cls]问题[sep]文本片段2[sep]
[cls]问题[sep]文本片段3[sep]
![]()
![]()
![]()
create_model
def create_model(bert_config, is_training, input_ids, input_mask, segment_ids,
use_one_hot_embeddings):
"""Creates a classification model."""
model = modeling.BertModel(
config=bert_config,
is_training=is_training,
input_ids=input_ids,
input_mask=input_mask,
token_type_ids=segment_ids,
use_one_hot_embeddings=use_one_hot_embeddings)
final_hidden = model.get_sequence_output()
#[batch size,seq_len,hidden size]
final_hidden_shape = modeling.get_shape_list(final_hidden, expected_rank=3)
batch_size = final_hidden_shape[0]
seq_length = final_hidden_shape[1]
hidden_size = final_hidden_shape[2]
output_weights = tf.get_variable(
"cls/squad/output_weights", [2, hidden_size],
initializer=tf.truncated_normal_initializer(stddev=0.02))
output_bias = tf.get_variable(
"cls/squad/output_bias", [2], initializer=tf.zeros_initializer())
final_hidden_matrix = tf.reshape(final_hidden,
[batch_size * seq_length, hidden_size])
#shape=[batch_size * seq_length, hidden_size]
logits = tf.matmul(final_hidden_matrix, output_weights, transpose_b=True)
#shape=[batch_size * seq_length, 2]
logits = tf.nn.bias_add(logits, output_bias)
#维度转换与句子分解
logits = tf.reshape(logits, [batch_size, seq_length, 2])
logits = tf.transpose(logits, [2, 0, 1])
#shape=[2,batch size,seq_len]
unstacked_logits = tf.unstack(logits, axis=0)
#shape=[1,batch size,seq_len]
#模型输出[batch size,seq_len]
(start_logits, end_logits) = (unstacked_logits[0], unstacked_logits[1])
#例如:起始概率=[[0.01, 0.02, ...], [0.80, 0.10, ...]],结束概率=[[0.01, 0.02, ...], [0.01, 0.01, ...]]
return (start_logits, end_logits)
#返回的是[batch size,seq_len]
model_fn_builder
def model_fn_builder(bert_config, init_checkpoint, learning_rate,
num_train_steps, num_warmup_steps, use_tpu,
use_one_hot_embeddings):
"""Returns `model_fn` closure for TPUEstimator."""
def model_fn(features, labels, mode, params): # pylint: disable=unused-argument
"""The `model_fn` for TPUEstimator."""
tf.logging.info("*** Features ***")
for name in sorted(features.keys()):
tf.logging.info(" name = %s, shape = %s" % (name, features[name].shape))
unique_ids = features["unique_ids"]
input_ids = features["input_ids"]
input_mask = features["input_mask"]
segment_ids = features["segment_ids"]
is_training = (mode == tf.estimator.ModeKeys.TRAIN)
#创建transformer模型
(start_logits, end_logits) = create_model(
bert_config=bert_config,
is_training=is_training,
input_ids=input_ids,
input_mask=input_mask,
segment_ids=segment_ids,
use_one_hot_embeddings=use_one_hot_embeddings)
#返回的是[batch size,seq_len]
tvars = tf.trainable_variables()
initialized_variable_names = {}
scaffold_fn = None
#从init_checkpoint恢复参数变量
if init_checkpoint:
(assignment_map, initialized_variable_names
) = modeling.get_assignment_map_from_checkpoint(tvars, init_checkpoint)
if use_tpu:
def tpu_scaffold():
tf.train.init_from_checkpoint(init_checkpoint, assignment_map)
return tf.train.Scaffold()
scaffold_fn = tpu_scaffold
else:
tf.train.init_from_checkpoint(init_checkpoint, assignment_map)
tf.logging.info("**** Trainable Variables ****")
for var in tvars:#遍历训练变量
init_string = ""
if var.name in initialized_variable_names:
init_string = ", *INIT_FROM_CKPT*"
tf.logging.info(" name = %s, shape = %s%s", var.name, var.shape,
init_string)
output_spec = None
#构造训练的spec
if mode == tf.estimator.ModeKeys.TRAIN:
seq_length = modeling.get_shape_list(input_ids)[1]
def compute_loss(logits, positions):
#定义计算损失
#logit--start_logits模型的得到开始位置的概率[batch size,seq_len]
#position--start_position输入特征中答案开始的位置,是个int
one_hot_positions = tf.one_hot(
positions, depth=seq_length, dtype=tf.float32)
log_probs = tf.nn.log_softmax(logits, axis=-1)
loss = -tf.reduce_mean(
tf.reduce_sum(one_hot_positions * log_probs, axis=-1))
#[1,seq_len]*[batch size, seq_len]=[1,batch size]
#求这个向量的累加和
return loss
start_positions = features["start_positions"]
end_positions = features["end_positions"]
start_loss = compute_loss(start_logits, start_positions)
end_loss = compute_loss(end_logits, end_positions)
total_loss = (start_loss + end_loss) / 2.0
train_op = optimization.create_optimizer(
total_loss, learning_rate, num_train_steps, num_warmup_steps, use_tpu)
output_spec = tf.contrib.tpu.TPUEstimatorSpec(
mode=mode,
loss=total_loss,
train_op=train_op,
scaffold_fn=scaffold_fn)
# 构造预测的spec,输出的是答案开始和结束位置的一组概率
elif mode == tf.estimator.ModeKeys.PREDICT:
predictions = {
"unique_ids": unique_ids,
"start_logits": start_logits,
"end_logits": end_logits,
}
output_spec = tf.contrib.tpu.TPUEstimatorSpec(
mode=mode, predictions=predictions, scaffold_fn=scaffold_fn)
else:
raise ValueError(
"Only TRAIN and PREDICT modes are supported: %s" % (mode))
return output_spec
return model_fn
根据create_model函数,构建estimator的model_fn
这个函数需要提供代码来处理三种mode(TRAIN,EVAL,PREDICT)值,返回tf.estimator.EstimatorSpec的一个实例
tf.estimator.ModeKeys.TRAIN模式:主要是需要返回loss,train_op(优化器)
tf.estimator.ModeKeys.PREDICT模式:主要是需要返回predictions结果
input_fn_builder
def input_fn_builder(input_file, seq_length, is_training, drop_remainder):
"""Creates an `input_fn` closure to be passed to TPUEstimator."""
#创建一个' input_fn '闭包传递给TPUEstimator。
name_to_features = {
"unique_ids": tf.FixedLenFeature([], tf.int64),
"input_ids": tf.FixedLenFeature([seq_length], tf.int64),
"input_mask": tf.FixedLenFeature([seq_length], tf.int64),
"segment_ids": tf.FixedLenFeature([seq_length], tf.int64),
}
if is_training:
name_to_features["start_positions"] = tf.FixedLenFeature([], tf.int64)
name_to_features["end_positions"] = tf.FixedLenFeature([], tf.int64)
def _decode_record(record, name_to_features):
"""Decodes a record to a TensorFlow example."""
#把record decode成TensorFlow example
example = tf.parse_single_example(record, name_to_features)
# tf.Example only supports tf.int64, but the TPU only supports tf.int32.
# So cast all int64 to int32.
for name in list(example.keys()):
t = example[name]
if t.dtype == tf.int64:
t = tf.to_int32(t)
example[name] = t
return example
#返回example
def input_fn(params):
"""The actual input function."""
batch_size = params["batch_size"]
# For training, we want a lot of parallel reading and shuffling.
## 对于训练来说,我们会重复的读取和shuffling
# For eval, we want no shuffling and parallel reading doesn't matter.
# 对于验证和测试,我们不需要shuffling和并行读取。
d = tf.data.TFRecordDataset(input_file)
if is_training:
d = d.repeat()
d = d.shuffle(buffer_size=100) #buffer_size代表将被加入缓冲器的元素的最大数
d = d.apply(
tf.contrib.data.map_and_batch(
lambda record: _decode_record(record, name_to_features),
batch_size=batch_size,
drop_remainder=drop_remainder))
return d
return input_fn
这个函数用于根据tfrecord文件,构建estimator的input_fn,把TFRecord的一条Record变成tf.Example对象。