mac下 如何简单粗暴 使用Python进行网络爬虫(1)
首先推荐几个 必须要掌握的类库
Requests: HTTP for Humans
它是以这么一句话介绍自己的,为人类使用的HTTP库
http://docs.python-requests.org/zh_CN/latest/user/quickstart.html 中文文档
Beautifulsoup
用Beautiful Soup解析网站源代码 代替正则
https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html 中文文档
开发环境:Mac
IDE:PyCharm (个人感觉非常好用)
游览器:Safari
第一步 我们进行最简单的爬虫 我选择的目标是 糗事百科 https://www.qiushibaike.com/text/
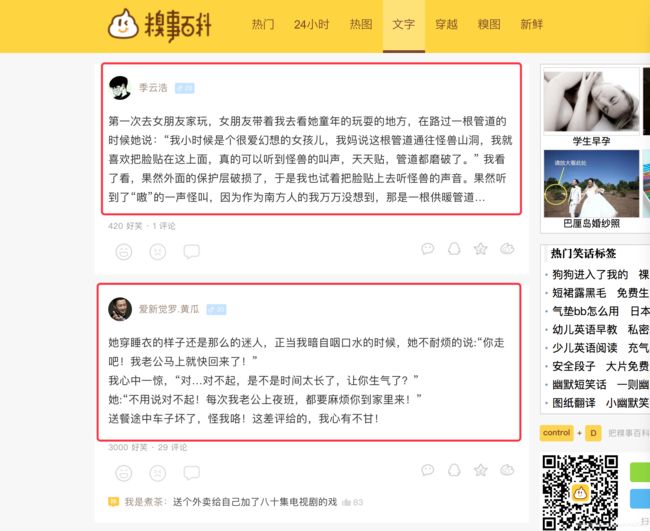
我们所需要的 就是 红框里这些文字 其余乱七八糟的广告 我们压根也不用 怎么办呢? Safari游览器中 右键点击 检查元素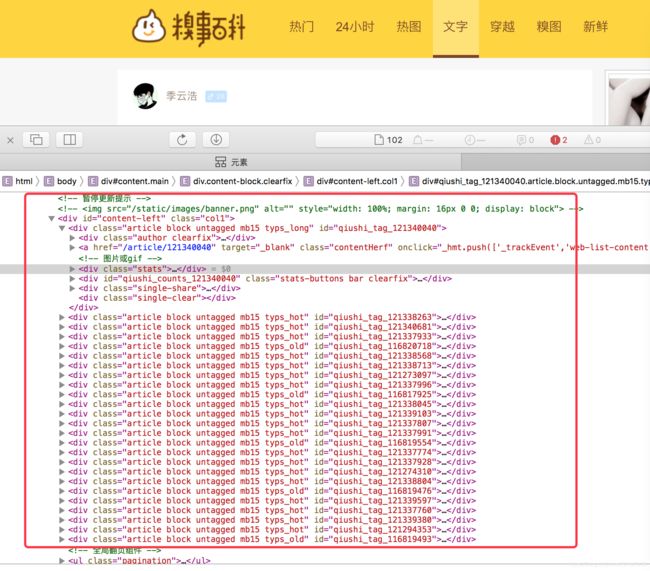
好了 所需的内容 就在这里面 但是这个只是个标题 内容 在点击进去的详情页 ,我们随便打开一个
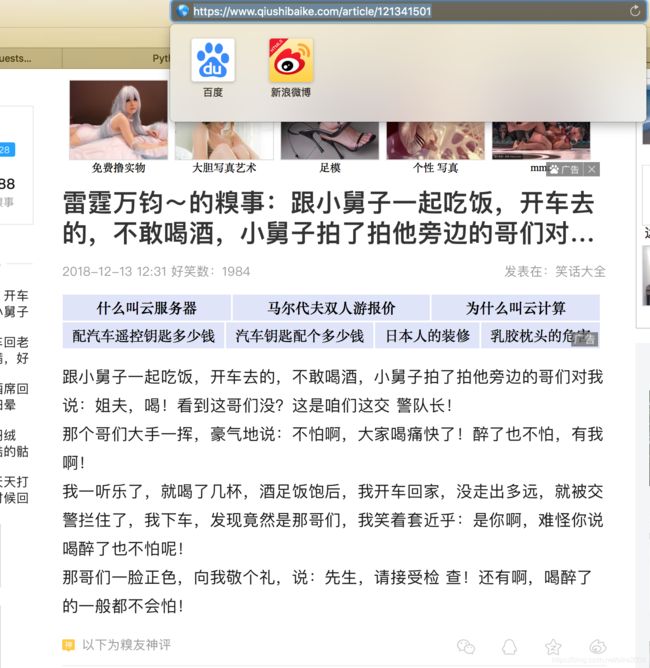
/article/121341501 注意这个后缀 https://www.qiushibaike.com/article/121341501 前缀+后缀 就是每一篇笑话的详情
那么我们首要的目的 就是要找到这个后缀列表
开始编写代码时 我们需要 安装所需的类库 网上很多教程 都是从命令行里安装 倒是也可以 但是用Pycharm里面有更方便的办法.
我使用的IDE是 PyCharm 安装request BeautifulSoup方法如下 :点击 Pycharm->Preferences
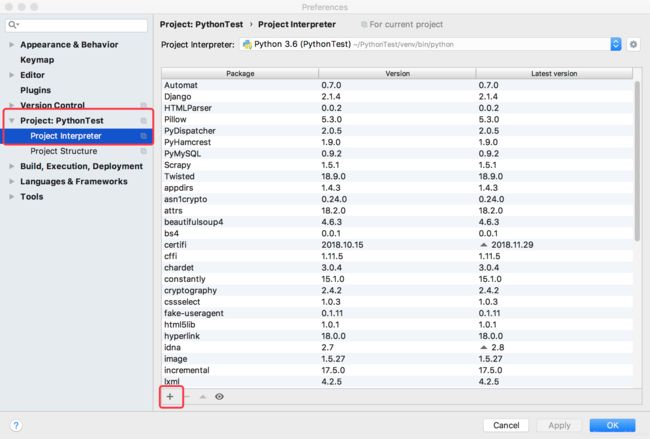
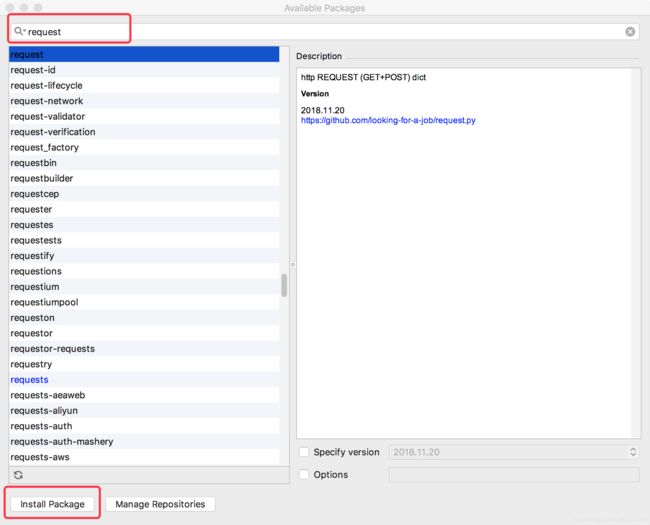
点击 Install Package 就可以安装了
好了 现在开始进入正题
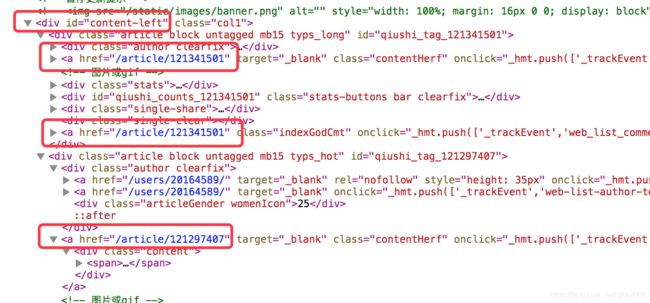
我们所需的href 都在 content-left 这下面 那我们就解析他
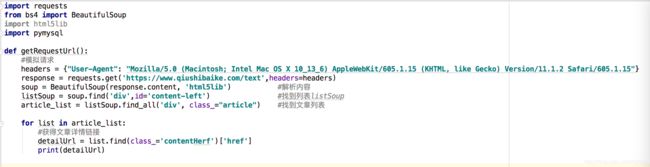
解释一下 这个模拟请求 是我用charles抓包得到的 你可以换成 你对应的请求 自己下载一个charles搞定 就行
通过解析 div 标签 content-left下面的 article 得到 一个列表数组 也就是我们所需的文章详情链接
按照上面代码 执行后 :
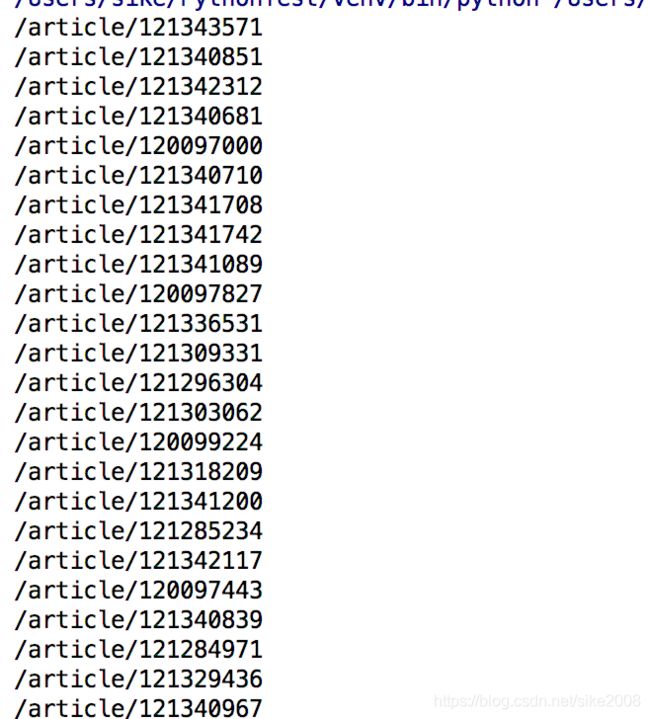
我们得到了 每个列表 所对应的文章详情链接
接下来 我们 再抓去 每个 详情的链接

通过 观察得知 文章在div class="content" 里面 作者 在href里面的 继续爬


抓包的数据 如上
这样 通过一个简单的抓包教程 我们就完成了 虽然没有太多技术含量 献给和我一样 刚开始学习爬虫的朋友
完整代码如下
import requests
from bs4 import BeautifulSoup
import html5lib
import pymysql
def getRequestUrl():
#模拟请求
headers = {"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/11.1.2 Safari/605.1.15"}
response = requests.get('https://www.qiushibaike.com/text',headers=headers)
soup = BeautifulSoup(response.content, 'html5lib') #解析内容
listSoup = soup.find('div',id='content-left') #找到列表listSoup
article_list = listSoup.find_all('div', class_="article") #找到文章列表
for list in article_list:
#获得文章详情链接
detailUrl = list.find(class_='contentHerf')['href']
getDetailUrl(detailUrl)
def getDetailUrl(url):
#得到文章详情
detailUrl = ('https://www.qiushibaike.com%s'%url)
print(detailUrl)
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/11.1.2 Safari/605.1.15"}
response = requests.get(detailUrl,headers=headers)
#result = response.content.decode('utf-8') #处理乱码
soup = BeautifulSoup(response.content, 'html5lib')
author = soup.find('a',class_='side-left-userinfo').find('img')['alt'] #获得作者
print('作者:%s'%author)
content = soup.find('div',class_='content').get_text() #获得文章
print('文章:%s'%content)
if __name__ =='__main__':
getRequestUrl()
爬虫后续文章 只发布 在简书 csdn 不再更新了
https://www.jianshu.com/u/3b35ac7a2ce1
欢迎大家来我的简书