青春有你利用飞桨给青春有你2的选手们做数据分析
作业任务
1、完成爱奇艺《青春有你2》评论数据爬取:爬取任意一期正片视频下评论,评论条数不少于1000条 2、词频统计并可视化展示 3、绘制词云 4、结合PaddleHub,对评论进行内容审核
首先非常感谢百度能提供相应的培训和算力
需要的配置和准备
- 中文分词需要jieba
- 词云绘制需要wordcloud
- 可视化展示中需要的中文字体
- 网上公开资源中找一个中文停用词表
- 根据分词结果自己制作新增词表
- 准备一张词云背景图(附加项,不做要求,可用hub抠图实现)
- paddlehub配置
安装相应的库
!pip install jieba
!pip install wordcloud
# Linux系统默认字体文件路径
!ls /usr/share/fonts/
# 查看系统可用的ttf格式中文字体
!fc-list :lang=zh | grep ".ttf"
!wget https://mydueros.cdn.bcebos.com/font/simhei.ttf # 下载中文字体
# #创建字体目录fonts
!mkdir .fonts
# # 复制字体文件到该路径
!cp simhei.ttf .fonts/
#安装模型
!hub install porn_detection_lstm==1.1.0
!pip install --upgrade paddlehub
from __future__ import print_function
import requests
import json
import re #正则匹配
import time #时间处理模块
import jieba #中文分词
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
import matplotlib.font_manager as font_manager
from PIL import Image
from wordcloud import WordCloud #绘制词云模块
import paddlehub as hub爬取评论数据
https://www.iqiyi.com/v_19ryi45hd8.html
这是青春有你的视屏网站,
评论是不断下滑加载的,并不是一次加载完毕,因此我们需要拿到加载评论的接口。
通过捕获,可以得到请求评论的接口如下
https://sns-comment.iqiyi.com/v3/comment/get_comments.action?agent_type=118&agent_version=9.11.5&authcookie=null&business_type=17&content_id=15068699100&hot_size=0&last_id=240718226621&page=&page_size=20&types=time&callback=jsonp_1587905040415_94459
主要使用参数:
last_id: 上次加载最后一条评论id,当last_id为空的时候,就是第一页,第一页加载10个
page_size:加载评论条数
经过测试单页加载量不能超过40个
爬虫代码
import datetime
#请求爱奇艺评论接口,返回response信息
def getMovieinfo(url):
'''
请求爱奇艺评论接口,返回response信息
参数 url: 评论的url
:return: response 信息
'''
session=requests.Session()
headers={
"User-Agent":"Mozilla/5.0",
"Accept":"application/json",
"Referer":"http://m.iqiyi.com/v_19rqriflzg.html",
"Origin":"http://m.iqiyi.com",
"Host":"sns-comment.iqiyi.com",
"Connection":"keep-alive",
"Accept=Language":"en-US,en;q=0.9,zh-CN;q=0.8,zh;q=0.7,zh-TW;q=0.6",
"Accept-Encoding":"gzip,deflate"
}
response =session.get(url,headers=headers)
if response.status_code==200:
return response.text
return None
#解析json数据,获取评论
def saveMovieInfoToFile(lastId,arr):
'''
解析json数据,获取评论
参数 lastId:最后一条评论ID arr:存放文本的list
:return: 新的lastId
'''
url="https://sns-comment.iqiyi.com/v3/comment/get_comments.action?agent_type=118&\
agent_version=9.11.5&authcookie=null&business_type=17&content_id=15068699100&\
page=&page_size=40&types=time&last_id="
url+=str(lastId)
responseTxt=getMovieinfo(url)
responseJson=json.loads(responseTxt)
comments=responseJson['data']['comments']
for val in comments:
if 'content' in val.keys():
#print(val['content'])
arr.append(val['content'])
lastId=str(val['id'])
return lastId数据的处理
#去除文本中特殊字符
def clear_special_char():
'''
正则处理特殊字符
参数 content:原文本
return: 清除后的文本
'''
f=open('work/comments.txt','r')
f_clear = open('work/clear_comments.txt','a')
for eachline in f:
#print(type(eachline))
#print(eachline)
clear_content=re.findall('[\u4e00-\u9fa5a-zA-Z0-9]+',eachline,re.S)
#print(clear_content)
#print(type(clear_content))
str=','.join(clear_content)
f_clear.write(str+'\n')
#print(f_clear.read())
f.close()
f_clear.close()这里的作用是去除掉,那些特殊的字符,便于数据分析

去除后

进行分词
这步的作用是将评论数据变成词汇
def fenci():
'''
利用jieba进行分词
参数 text:需要分词的句子或文本
return:分词结果
'''
seg_list=[]
f_clear=open('work/clear_comments.txt','r')
for eachline in f_clear:
jieba.load_userdict(r"start.txt")
tmp=jieba.lcut(eachline)
for s in tmp:
seg_list.append(s)
#seg_list.append(jieba.lcut(eachline))
#seg_list.append("".join(jieba.cut(eachline)))
#print(jieba.lcut(eachline))
f_clear.close()
return seg_list
start的作用是便于将人名作为一个词汇分开。
设置停用词
def stopwordslist():
'''
创建停用词表
参数 file_path:停用词文本路径
return:停用词list
'''
stopwords = [line.strip() for line in open('work/stopwords.txt',encoding='UTF-8').readlines()]
acstopwords=['哦','因此','不然','也好','但是']
stopwords.extend(acstopwords)
return stopwords
def movestopwords(sentence_depart,stopwords):
'''
去除停用词,统计词频
参数 file_path:停用词文本路径 stopwords:停用词list counts: 词频统计结果
return:None
'''
segments = []
# 去停用词
#print(sentence_depart)
for word in sentence_depart:
if word not in stopwords:
if word != '\t':
# outstr += word
# outstr += " "
segments.append(word)
return segments这里解释一下停用词,停用词也是我比较疑惑的地方
人类语言包含很多功能词。与其他词相比,功能词没有什么实际含义。最普遍的功能词是限定词(“the”、“a”、“an”、“that”、和“those”),这些词帮助在文本中描述名词和表达概念,如地点或数量。介词如:“over”,“under”,“above” 等表示两个词的相对位置。 这些功能词的两个特征促使在搜索引擎的文本处理过程中对其特殊对待。第一,这些功能词极其普遍。记录这些词在每一个文档中的数量需要很大的磁盘空间。第二,由于它们的普遍性和功能,这些词很少单独表达文档相关程度的信息。如果在检索过程中考虑每一个词而不是短语,这些功能词基本没有什么帮助。 在信息检索中,这些功能词的另一个名称是:停用词(stopword)。称它们为停用词是因为在文本处理过程中如果遇到它们,则立即停止处理,将其扔掉。将这些词扔掉减少了索引量,增加了检索效率,并且通常都会提高检索的效果。停用词主要包括英文字符、数字、数学字符、标点符号及使用频率特高的单汉字等。
比较适合中文的停用词 https://github.com/goto456/stopwords
可以去github上下载、
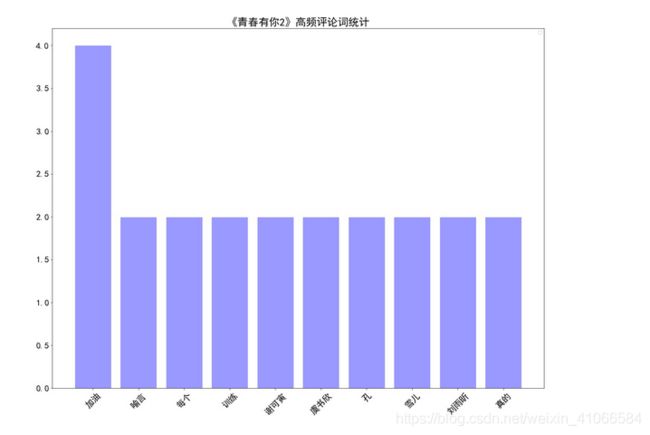
统计词频
import collections
def drawcounts(segments):
'''
绘制词频统计表
参数 counts: 词频统计结果 num:绘制topN
return:none
'''
#segments.pop('\n')
#segments.pop(',')
word_counts = collections.Counter(segments) # 对分词做词频统计
#print(type(word_counts))
word_counts_top10 = word_counts.most_common(12) # 获取前10最高频的词
word_counts_top10=word_counts_top10[2:]
print (word_counts_top10)
dic=dict(word_counts_top10)
print(dic)
x_values=[]
y_values=[]
for k in dic:
x_values.append(k)
y_values.append(dic[k])
# 设置显示中文
plt.rcParams['font.sans-serif'] = ['SimHei'] # 指定默认字体
plt.figure(figsize=(20,15))
plt.bar(range(len(y_values)), y_values,color='r',tick_label=x_values,facecolor='#9999ff',edgecolor='white')
# 这里是调节横坐标的倾斜度,rotation是度数,以及设置刻度字体大小
plt.xticks(rotation=45,fontsize=20)
plt.yticks(fontsize=20)
plt.legend()
plt.title('''《青春有你2》高频评论词统计''',fontsize = 24)
plt.savefig('highwords.jpg')
plt.show()
return word_counts因为我做的有点问题,统计词频的时候统计了\n和‘,’导致我的词频统计不对,因此我才用了一个切片来避免。
def drawcloud(word_counts):
'''
根据词频绘制词云图
参数 word_f:统计出的词频结果
return:none
'''
font=r'simHei.ttf'
cloud_mask=np.array(Image.open('Background.png'))
st=set(['东西','这是'])
wc=WordCloud(background_color='white',
mask=cloud_mask,
max_words=150,
font_path='simhei.ttf',
min_font_size=10,
max_font_size=100,
width=400,
relative_scaling=0.3,
stopwords=st)
wc.fit_words(word_counts)
wc.to_file('pic.png')背景图
利用飞桨上的Al智能抠图
import sys
import os
import paddlehub as hub
# 加载模型
humanseg = hub.Module(name = "deeplabv3p_xception65_humanseg")
# 抠图
results = humanseg.segmentation(data = {"image":['sendpix0.jpg']})
for result in results:
print(result['origin'])
print(result['processed'])
 抠图的结果
抠图的结果
评论审核
porn_detection_lstm = hub.Module(name="porn_detection_lstm")
import six
def text_detection():
'''
使用hub对评论进行内容分析
return:分析结果
'''
comment_text = [line.strip() for line in open('work/clear_comments.txt',encoding='UTF-8').readlines()]
input_dict = {"text": comment_text}
results = porn_detection_lstm.detection(data=input_dict,use_gpu=True, batch_size=1)
f_dect=open('work/text_detection.txt','w')
for index, text in enumerate(comment_text):
results[index]["text"] = text
for index, result in enumerate(results):
if six.PY2:
detection= json.dumps(results[index], encoding="utf8", ensure_ascii=False)
else:
detection=results[index]
# print(detection)
print("检测句子:%s,检测结果not_porn_probs:%f\n"%(detection['text'],detection['not_porn_probs']))
f_dect.write("检测句子:%s,检测结果not_porn_probs:%f\n"%(detection['text'],detection['not_porn_probs']))
f_dect.close
基于PaddlePaddle的porn_detection_lstm预训练模型,可自动判别文本是否涉黄并给出相应的置信度,对文本中的色情描述、低俗交友、污秽文爱进行识别。porn_detection_lstm采用LSTM网络结构并按字粒度进行切词,具有较高的分类精度。该模型最大句子长度为256字,仅支持预测。
我在做作业的时候忘记做这部分了,。。。。
展示词云
display(Image.open('pic.png')) #显示生成的词云图像