吴恩达Coursera深度学习(5-1)递归神经网络 RNN
参考博客:http://blog.csdn.net/koala_tree/article/details/79299358
Class 5:序列模型 Sequence Models
Week 1:循环神经网络 RNN(Recurrent)
目录
- Class 5:序列模型 Sequence Models
- Week 1:循环神经网络 RNN(Recurrent)
- 目录
- 1、序列模型的应用
- 2、数学符号
- 3、循环神经网络
- 4、穿越时间的反向传播
- 5、不同类型的RNN
- 6、语言模型和序列生成
- 7、Sampling novel sequences
- 8、RNN的梯度消失
- 9、GRU单元
- 10、LSTM(long short term memory)
- 11、双向RNN(Bidirectional)
- 12、Deep RNNs
本课程将教你如何建立自然语言,音频和其他序列数据的模型。 由于深入的学习,序列算法的运行速度远远超过两年前,这使得语音识别,音乐合成,聊天机器人,机器翻译,自然语言理解等许多令人兴奋的应用成为可能。
- 了解如何构建和训练递归神经网络(RNN)以及常用模型,如GRU和LSTM。
- 能够将序列模型应用于自然语言问题,包括文本合成。
- 能够将序列模型应用于音频应用,包括语音识别和音乐合成。
递归神经网络:这种模型已被证明在时态数据上表现得非常好。它有多种变体,包括LSTM,GRU和双向RNN
1、序列模型的应用
- 语音识别:将输入的语音信号直接输出相应的语音文本信息。无论是语音信号还是文本信息均是序列数据。
- 音乐生成:生成音乐乐谱。只有输出的音乐乐谱是序列数据,输入可以是空或者一个整数。
- 情感分类:将输入的评论句子转换为相应的等级或评分。输入是一个序列,输出则是一个单独的类别。
- DNA序列分析:找到输入的DNA序列的蛋白质表达的子序列。
- 机器翻译:两种不同语言之间的想换转换。输入和输出均为序列数据。
- 视频行为识别:识别输入的视频帧序列中的人物行为。
- 命名实体识别:从输入的句子中识别实体的名字。

2、数学符号

3、循环神经网络
传统标准的神经网络
对于学习X和Y的映射,我们可以很直接的想到一种方法就是使用传统的标准神经网络。也许我们可以将输入的序列X以某种方式进行字典编码以后,如one-hot编码,输入到一个多层的深度神经网络中,最后得到对应的输出Y。如下图所示:

但是,结果表明这种方法并不好,主要是存在下面两个问题:
- 输入和输出数据在不同的例子中可以有不同的长度;
- 这种朴素的神经网络结果并不能共享从文本不同位置所学习到的特征。(如卷积神经网络中学到的特征的快速地推广到图片其他位置)
循环神经网络
循环神经网络作为一种新型的网络结构,在处理序列数据问题上则不存在上面的两个缺点。在每一个时间步中,循环神经网络会传递一个激活值到下一个时间步中,用于下一时间步的计算。如下图所示:

这里需要注意在零时刻,我们需要编造一个激活值,通常输入一个零向量,有的研究人员会使用随机的方法对该初始激活向量进行初始化。同时,上图中右边的循环神经网络的绘制结构与左边是等价的。
循环神经网络是从左到右扫描数据的,同时共享每个时间步的参数。

上述循环神经网络结构的缺点:每个预测输出y< t>仅使用了前面的输入信息,而没有使用后面的信息。Bidirectional RNN(双向循环神经网络)可以解决这种存在的缺点。
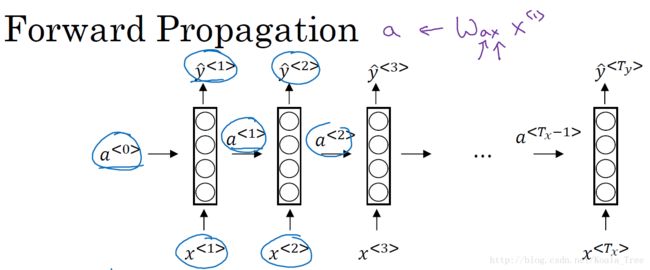
循环神经网络的前向传播
下图是循环神经网络结构图:


4、穿越时间的反向传播
为了进行反向传播计算,使用梯度下降等方法来更新RNN的参数,我们需要定义一个损失函数,如下:

上式表示将每个输出的损失进行求和即为整体的损失函数。反向传播算法按照前向传播相反的方向进行导数计算,来对参数进行更新。其中比较特别的是在RNN中,从右向左的反向传播计算是通过时间来进行,如穿越时间的反向计算。
一般可以通过成熟的深度学习框架自动求导,例如PyTorch、Tensorflow等
5、不同类型的RNN
对于RNN,不同的问题需要不同的输入输出结构。
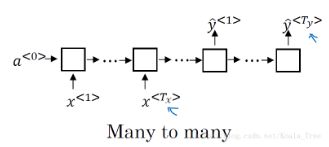
Many-to-Many (Tx=Ty)
这种情况下的输入和输出的长度相同,是上面例子的结构,如下图所示:

many-to-one:
如在情感分类问题中,我们要对某个序列进行正负判别或者打星操作。在这种情况下,就是输入是一个序列,但输出只有一个值:

one-to-many
如在音乐生成的例子中,输入一个音乐的类型或者空值,直接生成一段音乐序列或者音符序列。在这种情况下,就是输入是一个值,但输出是一个序列:

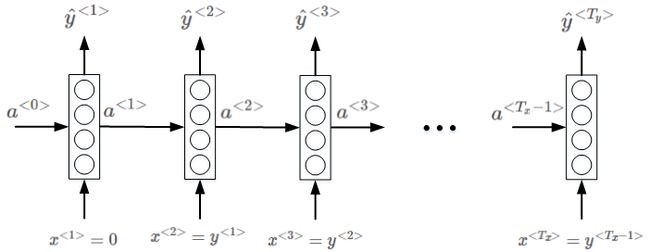
many-to-many (Tx != Ty)
我们上面介绍的一种RNN的结构是输入和输出序列的长度是相同的,但是像机器翻译这种类似的应用来说,输入和输出都是序列,但长度却不相同,这是另外一种多对多的结构:
6、语言模型和序列生成
语言模型是自然语言处理(NLP)中最基本和最重要的任务之一。使用RNN能够很好地建立需要的不同语言风格的语言模型。
什么是语言模型呢?举个例子,在语音识别中,某句语音有两种翻译:
The apple and pair salad.
The apple and pear salad.
很明显,第二句话更有可能是正确的翻译。语言模型实际上会计算出这两句话各自的出现概率。比如第一句话概率为 10−13 10 − 13 ,第二句话概率为 10−10 10 − 10 。也就是说,利用语言模型得到各自语句的概率,选择概率最大的语句作为正确的翻译。概率计算的表达式为:
![]()
如何使用RNN构建语言模型?首先,我们需要一个足够大的训练集,训练集由大量的单词语句语料库(corpus)构成。然后,对corpus的每句话进行切分词(tokenize)。做法就跟第2节介绍的一样,建立vocabulary,对每个单词进行one-hot编码。例如下面这句话:
The Egyptian Mau is a bread of cat.
One-hot编码已经介绍过了,不再赘述。还需注意的是,每句话结束末尾,需要加上< EOS >作为语句结束符。另外,若语句中有词汇表中没有的单词,用< UNK >表示。假设单词“Mau”不在词汇表中,则上面这句话可表示为:
The Egyptian < UNK > is a bread of cat. < EOS >
准备好训练集并对语料库进行切分词等处理之后,接下来构建相应的RNN模型。


7、Sampling novel sequences
利用训练好的RNN语言模型,可以进行新的序列采样,从而随机产生新的语句。与上一节介绍的一样,相应的RNN模型如下所示:

8、RNN的梯度消失
RNN在NLP中具有很大的应用价值,但是其存在一个很大的缺陷,那就是梯度消失的问题。例如下面的例句中:
The cat, which already ate ………..,was full;
The cats, which already ate ………..,were full.
在这两个句子中,cat对应着was,cats对应着were,(中间存在很多很长省略的单词),句子中存在长期依赖(long-term dependencies),前面的单词对后面的单词有很重要的影响。但是我们目前所见到的基本的RNN模型,是不擅长捕获这种长期依赖关系的。
如下图所示,和基本的深度神经网络结构类似,输出y得到的梯度很难通过反向传播再传播回去,也就是很难对前面几层的权重产生影响,所以RNN也有同样的问题,也就是很难让网络记住前面的单词是单数或者复数,进而对后面的输出产生影响。

对于梯度消失问题,在RNN的结构中是我们首要关心的问题,也更难解决;虽然梯度爆炸在RNN中也会出现,但对于梯度爆炸问题,因为参数会指数级的梯度,会让我们的网络参数变得很大,得到很多的Nan或者数值溢出,所以梯度爆炸是很容易发现的,我们的解决方法就是用梯度修剪,也就是观察梯度向量,如果其大于某个阈值,则对其进行缩放,保证它不会太大。
9、GRU单元
门控循环单元(Gated Recurrent Unit, GRU)改变了RNN的隐藏层,使其能够更好地捕捉深层次连接,并改善了梯度消失的问题。
RNN单元 ,RNN的隐藏层单元结构如下图所示:

为了解决梯度消失问题,对上述单元进行修改,添加了记忆单元,构建GRU,如下图所示:
简化的GRU单元
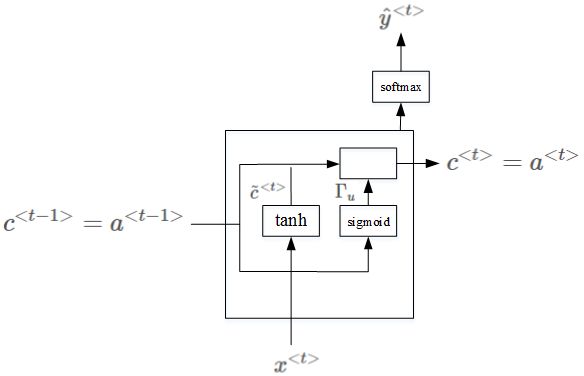
我们以时间步从左到右进行计算的时候,在GRU单元中,存在一个新的变量称为c,(代表cell),作为“记忆细胞”,其提供了长期的记忆能力。

上面介绍的是简化的GRU模型,完整的GRU添加了另外一个gate,即 Γr Γ r ,表达式如下:
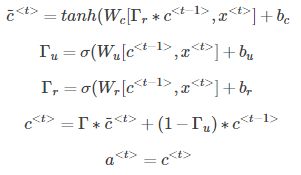
注意,以上表达式中的∗表示元素相乘,而非矩阵相乘。
10、LSTM(long short term memory)
LSTM是另一种更强大的解决梯度消失问题的方法。它对应的RNN隐藏层单元结构如下图所示:

GRU可以看成是简化的LSTM,两种方法都具有各自的优势。
11、双向RNN(Bidirectional)
对于下图的单向RNN的例子中,无论我们的RNN单元是基本的RNN单元,还是GRU,或者LSTM单元,对于例子中第三个单词”Teddy”很难判断是否是人名,仅仅使用前面的两个单词是不够的,需要后面的信息来进行判断,但是单向RNN就无法实现获取未来的信息。
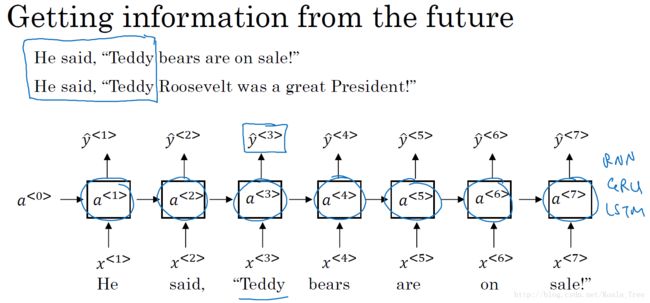
双向RNN结构如下图所示:

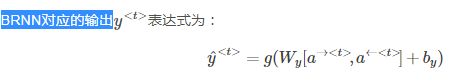
BRNN能够同时对序列进行双向处理,性能大大提高。但是计算量较大,且在处理实时语音时,需要等到完整的一句话结束时才能进行分析。
在NLP问题中,常用的就是使用双向RNN的LSTM。
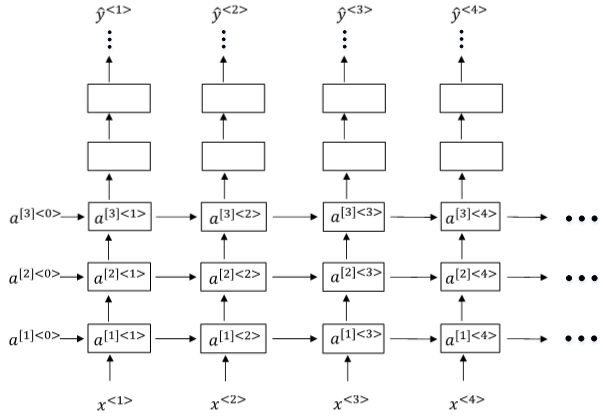
12、Deep RNNs
Deep RNNs由多层RNN组成,其结构如下图所示:
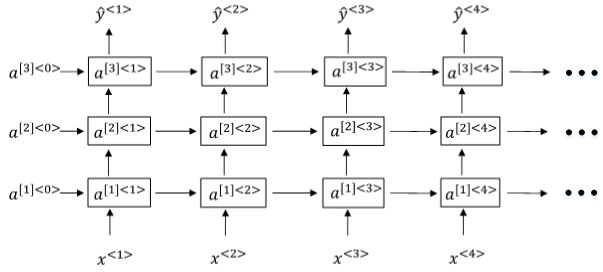
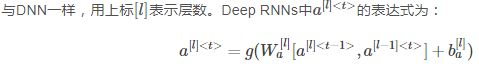
我们知道DNN层数可达100多,而Deep RNNs一般没有那么多层,3层RNNs已经较复杂了。
另外一种Deep RNNs结构是每个输出层上还有一些垂直单元,如下图所示: