seq2seq and attention 入门并在tensorflow中使用
Seq2Seq and Attention
汇总理解
参考文献
[1] Cho 在 2014 年在论文《Learning Phrase Representations using RNN Encoder–Decoder
for Statistical Machine Translation》中提出 Encoder–Decoder 结构
[2] Sutskever et al 2014年在论文 《Sequence to Sequence Learning with Neural Networks》中正式提出seq2seq的概念
[3] Dzmitry Bahdanau, Kyunghyun Cho, Yoshua Bengio.在论文
《Neural Machine Translation by Jointly Learning to Align and Translate》 ICLR 2015.中提出BahdanauAttention Mechanism。
[4] Minh-Thang Luong, Hieu Pham, Christopher D. Manning.在论文
《”Effective Approaches to Attention-based Neural Machine Translation.”
EMNLP 2015.》中提出LuongAttention Mechanism.
1. seq2seq
seq2seq的名字全称是序列到序列(sequence to sequence), 从一个序列到另一个序列,可以是从中文的序列到英文的序
列,也可以是从中文语音序列到中文文字序列,总之,实现的是从一个不定长输入序列到一个不定长输出序列的过程。
Encoder-Decoder
要实现从一个序列到另外一个序列的转换,正常思维逻辑是找到一个中间编码,可以实现在两种序列之间实现自由转换。于是乎,Encoder-Decoder结构在2014年被Cho提了出来, 先通过编码器对原序列进行编码,再通过解码器对中间编码进行解码得到输出序列。
Figure 1 为encoder_decoder结构示意图,encoder框中是一个正常的rnn结构,输入序列 (x1,x2,...,xT) ( x 1 , x 2 , . . . , x T ) ,输出 C C 。 C C 是上文中说到的中间序列。decoder框中同样为rnn结构, 其输入是中间编码 C C , 输出为输出序列 (y1,y2,...,yT) ( y 1 , y 2 , . . . , y T ) 。

这里decoder部分的rnn和encoder部分的rnn稍有不同。
encoder的rnn为正常使用,由上一时刻隐状态和该时刻输入进行隐状态更新,公式为:
decoder的rnn隐藏状态更新,因没有输入序列,只有输入隐藏状态,所以由上一时刻隐状态、上一时刻输出和encoder的输出来更新隐藏状态, 公式为:
decoder的rnn在t时刻的输出由 t t 时刻的隐藏状态、 (t−1) ( t − 1 ) 时刻的输出和 C C 计算得出,公式为:
encoder和decoder的训练目标是最大化条件概率分布:
模型参数为θ,出现xn时yn的条件概率P,logP是单调递增,更容易计算,将N个P加起来求平均,就是最终的优化目标,输出序列输出几个符号,N就是几。 模 型 参 数 为 θ , 出 现 x n 时 y n 的 条 件 概 率 P , log P 是 单 调 递 增 , 更 容 易 计 算 , 将 N 个 P 加 起 来 求 平 均 , 就 是 最 终 的 优 化 目 标 , 输 出 序 列 输 出 几 个 符 号 , N 就 是 几 。
大白话说公式:
decoder所有输出的值的条件概率之和求平均值,平均值越大,优化效果越好。而cost损失,就是该结果的负数,cost越小,越接近拟合。
* 以上也是seq2seq的原理部分 *
2. Attention
seq2seq中encoder通过 c c 将信息传给decoder, c c 承载的是训练数据中序列的信息,而 c c 仅仅是rnn隐藏序列的最后一个,表达的是整个序列的信息。而如果想要更好的结果,将encoder序列的所有隐藏状态都给decoder显然更好,因此 c c 可以是encoder所有时刻的隐藏状态之和,此时的 c c 表示encoder 中又包含了各个词的隐藏信息;当然,在解码时生成某一个词有时候并不需要依赖输入序列所有的词的信息,此时,只要给encoder每个时刻隐藏状态一个权值,再相加,就可以得到生成指定词最适合的编码信息了,换种说法就是当生成某个词的时候我们的注意力只放在那些对它有用的词信息上。这就是注意力机制的逻辑。
2.1 Bahdanau Attention Mechanism
先来介绍Bahdanau在2015年提出的attention mechanism。
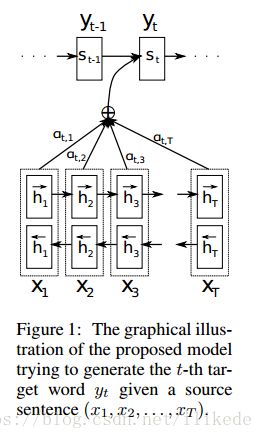
同样,decoder通过计算条件概率分布的方式来预测输出:
注意:encoder-decoder中的 c c 是固定不变得信息,而这里 ci c i 是一个变化信息,同样代表输入句子的表征,不同时刻注意力集中在不同的词上面。
状态 si s i 是time i i 时刻decoder rnn的隐藏状态:
上下文向量 ci c i 由输入序列的annotation(表示) h1,...,hTx h 1 , . . . , h T x 产生。每个annotation hi h i 包含整个序列的信息的同时更多的关注第 i i 个字的上下文信息。 ci c i 的计算:
这里的 αij α i j 是每个annotation hj h j 的权重得分,范围为(0,1):
eij e i j 为decoder (i−1) ( i − 1 ) 位置的隐藏状态和encoder中 j j 位置的隐藏状态经过计算方式 a a 得到的分值。
a a 的计算方式为:
这里的W为参数矩阵,作为可训练参数加入整个网络。
网络经过训练可以学习到:解码器在输出一个序列元素时,哪些编码器信息更有价值,更值得被关注,这就是注意力机制的通俗解释。
2.2 Luong Attention Mechanism
Luong 在论文4中提出一种 a(对齐函数) a ( 对 齐 函 数 ) 的新计算方式,
需要注意的是在Luong中,通过t时刻decoder的state和当前计算出的来自encoder的 c c 来确定decoder的下一时刻状态。
rnn的隐藏状态,也称 thinking parameters 或 annotation informations,每一时刻的隐藏状态表示整个输入句子的前后关系,逻辑,顺序等信息,同时更加关注(focus on)该时刻前后时刻的关系的表示信息。
当使用bilstm时,隐藏状态包括 前向隐藏状态(forward state) 和 后向隐藏状态(back state),将这两个状态对应时刻的状态相加就可以。具体实现:
encoder_outputs = tf.concat((encoder_fw_outputs, encoder_bw_outputs), 2)
encoder_final_state_c = tf.concat(
(encoder_fw_final_state.c, encoder_bw_final_state.c), 1)
encoder_final_state_h = tf.concat(
(encoder_fw_final_state.h, encoder_bw_final_state.h), 1)
encoder_final_state = LSTMStateTuple(
c=encoder_final_state_c,
h=encoder_final_state_h
)3. seq2seq + attention 使用部分
以下代码构建了tensorflow的图,可以执行
import tensorflow as tfInput
batch_size = 5
encoder_input = tf.placeholder(shape=[batch_size, None], dtype=tf.int32 )
decoder_target = tf.placeholder(shape=[batch_size, None], dtype=tf.int32)- 序列中每个元素转换成one_hot方式,方便得到embedding
- 通过申请变量的方式创建embedding 矩阵
- 如果输入序列和输出序列不是同源的,需要创建两个embedding
Embedding
input_vocab_size = 10
target_vocab_size = 10
input_embedding_size = 20
target_embedding_size = 20
encoder_input_ = tf.one_hot(encoder_input,depth=input_vocab_size, dtype=tf.int32)
decoder_target_ = tf.one_hot(decoder_target,depth=target_vocab_size, dtype=tf.int32)
input_embedding = tf.Variable(tf.random_uniform(shape=[input_vocab_size, input_embedding_size],minval=-1.0,maxval= 1.0), dtype=tf.float32)
target_embedding = tf.Variable(tf.random_uniform(shape=[target_vocab_size, target_embedding_size], minval=-1.0, maxval=1.0), dtype=tf.float32)
input_embedd = tf.nn.embedding_lookup(input_embedding, encoder_input)
target_embedd = tf.nn.embedding_lookup(target_embedding, decoder_target)Encoder
rnn_hidden_size = 20
cell = tf.nn.rnn_cell.GRUCell(num_units=rnn_hidden_size)
init_state = cell.zero_state(batch_size, dtype=tf.float32)
encoder_output, encoder_state = tf.nn.dynamic_rnn(cell, input_embedd, initial_state=init_state)Decoder
- helper
inference = False
seq_len = tf.constant([3,4,5,2,3], tf.int32)
if not inference:
helper = tf.contrib.seq2seq.TrainingHelper(target_embedd, sequence_length=seq_len)
if inference:
helper = tf.contrib.seq2seq.InferenceHelper(target_embedd, sequence_length=seq_len)- rnn_cell
d_cell = tf.nn.rnn_cell.GRUCell(rnn_hidden_size)- attention cell
attention_mechanism = tf.contrib.seq2seq.BahdanauAttention(rnn_hidden_size, encoder_output)
decoder_cell = tf.contrib.seq2seq.AttentionWrapper(d_cell, attention_mechanism, attention_layer_size=rnn_hidden_size)
de_state = decoder_cell.zero_state(batch_size,dtype=tf.float32)
out_cell = tf.contrib.rnn.OutputProjectionWrapper(decoder_cell, target_vocab_size)with tf.variable_scope('decoder'):
decoder = tf.contrib.seq2seq.BasicDecoder(
out_cell,
helper,
de_state,
tf.layers.Dense(target_embedding_size))- dynamic decoder
final_outputs, final_state, final_sequence_lengths = tf.contrib.seq2seq.dynamic_decode(decoder,swap_memory=True)回忆
seq2seq 整个过程终于整明白了,真是不容易。
seq2seq是序列到序列,即可以从一种序列到另一种序列,无论这两种序列是什么类型,只要这两者存在某种联系就可以。
首先创建输入,输入包括输入序列和输入出序列;然后对两个输入序列做embedding, 通过tensorflow 申请变量的方式创建embedding矩阵, 大小是对应的[vocab_size, embedding_size](两种序列vocab不一样的话,得分别创建),矩阵内容随机生成,生成方式采用平均分布,范围(-1,1)。通过lookup得到两个序列矩阵表示。
- lookup接受的ids参数是个onehod向量,因此需要对输入数据进行转换。
- 当然这里也可以省去lookup的步骤,只要helper使用Greedyembeddinghelper类。
输入部分完成后,开始创建编码器,这里的编码器只是一个普通的rnn_cell, 在不使用attention的情况下,seq2seq只需要用到rnn的state就可以了,在使用attention的情况下,attention机制中计算编码器中每个步骤结果的权重是需要用到encoder的output,确切的用在basic_attention中。
- 需要说明的是,这里还是不太明白,好像原理里面并没有用到output。
编码器创建完就开始创建解码器,解码器包含 申请rnn_cell,使用attention, 申请helper, 创建decoder,应用dynamic_decoder将整体循环执行。
- rnn_cell 是一个简单的rnn部分,可以是任何形式的rnn
- attention 是在对rnn_cell 做更多的包装,需要申请attention 的方式(tensorflow中实现了两种),然后使用attentionWrapper将rnn_cell 和attention机制封装到一起,生成一个新的具备attention功能的cell,
- helper 中定义了解码过程中需要用到的三个函数
- 转移函数(transition_fn)用在将前一步的输出和状态传给下一步的输入和state,中间的输出还要经过project部分得到新的元素的embedding作为下一个time的输入;
第三个函数:循环函数(loop_fn),指定time=0时执行initial_fn,time>0时执行trainsition_fn。 - tricky:这里的小tricky是要对序列拼接eos和pad,训练时eos表示开始,pad表示结束,都在vocab中有特定的表示。
- 这里不明白的是,在写程序的时候发现训练时,只输入了开始eos,并没有做结尾的符号。
- helper可用可不用,不用helper的时候需要自己写上述三个函数,同时使用tf.nn.raw_rnn来将自己写的三个函数串起来。
- dynamic_decode 是在使用helper的情况下动态执行整个解码过程的函数,序列结果会通过该步骤输出。