elasticsearch插件 —— 分词 IK analyzer插件安装详解
一、 IK Analyzer 介绍
IK Analyzer是一个开源的,基于Java语言开发的轻量级的中文分词工具包,最初的时候,它是以开源项目Lucene为应用主体的,结合词典分词和文法分析算法的中文分词组件,从3.0版本之后,IK逐渐成为面向java的公用分词组件,独立于Lucene项目,同时提供了对Lucene的默认优化实现,IK实现了简单的分词 歧义排除算法,标志着IK分词器从单纯的词典分词向模拟语义分词衍化。
当安装完Elasticsearch之后,默认已经含有一个分词法,就是standard,这个分词法对英文的支持还可以,但是对中文的支持非常差劲,如图所示:
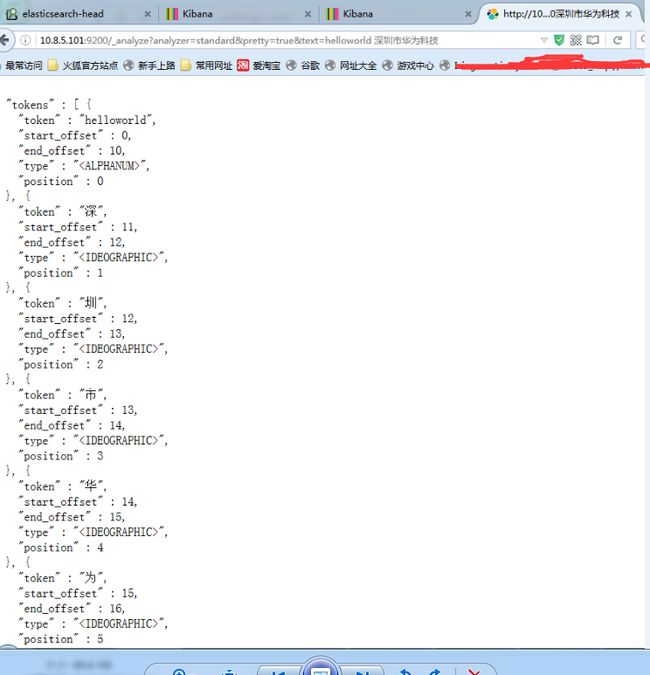
二、IK analyzer 安装步骤
首先下载相应的版本的ik分词器安装包,下载地址:
https://github.com/medcl/elasticsearch-analysis-ik/releases


对应es是6.4.0的版本,下载后解压到ik文件夹下,解压后目录如下

把ik文件夹放到es的plugins目录下,重启es测试
curl -XGET 'http://localhost:9200/_analyze?pretty&analyzer=ik_max_word' -d '联想是全球最大的笔记本厂商
返回结果
{
"tokens" : [
{
"token" : "联想",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "是",
"start_offset" : 2,
"end_offset" : 3,
"type" : "CN_CHAR",
"position" : 1
},
{
"token" : "全球",
"start_offset" : 3,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 2
},
{
"token" : "最大",
"start_offset" : 5,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 3
},
{
"token" : "的",
"start_offset" : 7,
"end_offset" : 8,
"type" : "CN_CHAR",
"position" : 4
},
{
"token" : "笔记本",
"start_offset" : 8,
"end_offset" : 11,
"type" : "CN_WORD",
"position" : 5
},
{
"token" : "笔记",
"start_offset" : 8,
"end_offset" : 10,
"type" : "CN_WORD",
"position" : 6
},
{
"token" : "本厂",
"start_offset" : 10,
"end_offset" : 12,
"type" : "CN_WORD",
"position" : 7
},
{
"token" : "厂商",
"start_offset" : 11,
"end_offset" : 13,
"type" : "CN_WORD",
"position" : 8
}
]
}
ik分词器安装成功