DeepLab V3+ 训练自己的数据
一、前提
官网代码:https://github.com/tensorflow/models/tree/master/research/deeplab
1. 依赖
DeepLab依赖于以下库:
- Numpy
- Pillow 1.0
- tf Slim (which is included in the "tensorflow/models/research/" checkout)
- Jupyter notebook
- Matplotlib
- Tensorflow1.6及以上
2. 将库添加到PYTHONPATH
在本地运行时,tensorflow / models / research /和slim目录应该附加到PYTHONPATH。 这可以通过在 tensorflow / models / research /路径下运行以下命令来完成:
# From tensorflow/models/research/
export PYTHONPATH=$PYTHONPATH:`pwd`:`pwd`/slim注意:每次启用新终端,此命令都需要运行。 如果想避免手动运行,可以将其作为新行添加到〜/ .bashrc文件的末尾。
3. 简单测试
可以通过运行以下命令来测试是否已成功安装 Tensorflow DeepLab:
运行 model_test.py 进行快速测试:
# From tensorflow/models/research/
python deeplab/model_test.py在PASCAL VOC 2012数据集上快速运行整个代码:
# From tensorflow/models/research/deeplab
sh local_test.shlocal_test.sh 脚本用于在PASCAL VOC 2012上运行本地测试。
之后在自己数据集上进行训练等操作就可以参照 local_test.sh 来编辑指令。打开脚本看一下,发现它:
(1)执行了model_test.py
(2)执行了download_and_convert_voc2012.sh
(3)从model_zoo(http://download.tensorflow.org/models)下载了模型deeplabv3_pascal_train_aug
(4)执行了train.py
(5)执行了eval.py
(6)执行了vis.py
(7)执行了export_model.py
建议仔细阅读上面提到的脚本和程序,为以后训练自己的数据提供参考。
错误1:
运行 model_test.py 进行快速测试时出错:

参考 https://github.com/tensorflow/models/issues/5523
将 model_test.py 中140行左右的:
self.assertListEqual(scales_to_model_results.keys(),修改为:
self.assertListEqual(list(scales_to_model_results.keys()),错误2:
测试程序需要运行eval.py,我在这里出现了一个错误:
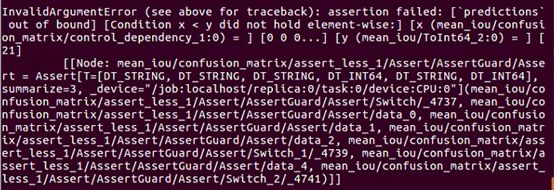
即:InvalidArgumentError (see above for traceback): assertion failed: [`predictions` out of bound] [Condition x < y did not hold element-wise:] [x (mean_iou/confusion_matrix/control_dependency_1:0) = ] [0 0 0...] [y (mean_iou/ToInt64_2:0) = ] [21]
参考https://github.com/tensorflow/models/issues/4203中trobr的说法:
修改 eval.py 中第145 行左右:
将:
metric_map = {}
metric_map[predictions_tag] = tf.metrics.mean_iou(
predictions, labels, dataset.num_classes, weights=weights)修改为: 也就是中间插入了几行
metric_map = {}
# insert by trobr
indices = tf.squeeze(tf.where(tf.less_equal(
labels, dataset.num_classes - 1)), 1)
labels = tf.cast(tf.gather(labels, indices), tf.int32)
predictions = tf.gather(predictions, indices)
# end of insert
metric_map[predictions_tag] = tf.metrics.mean_iou(
predictions, labels, dataset.num_classes, weights=weights)在训练自己的数据集之前,最好将官网提供的 Pascal voc 2012 等数据集跑通。
二、数据准备
参照VOC2012的文件结构,把自己的数据和文件夹准备好。
参考 download_and_convert_voc2012.sh 进行数据转化。
1. 修改label图
label图应该是灰度图,并且类别的像素标记应该是0,1,2,3......n(共计n+1个类别,包含1个背景类和n个目标类),此外,label图上忽略的像素标记为255。
注意:不要把 ignore_label 和 background 混淆,ignore_label 没有做标注,不在预测范围内,即不参与计算loss。我们在mask中将 ignore_label 的灰度值标记为 255,而background 标记为 0。
如果是voc2012这种有 colormap 的标签图,可以利用 remove_gt_colormap.py 先去掉 colormap:【当然,如果你对标签图本来就没有colormap,这步可以忽略】
# from research/deeplab/datasets
python remove_gt_colormap.py \
--original_gt_folder="/path/SegmentationClass" \
--output_dir="/path/SegmentationClassRaw"
其中, original_gt_folder 是原始标签图文件夹,output_dir 是要输出的标签图文件夹的位置。


2. 数据转换为tfrecord
# from research/deeplab/datasets
python build_voc2012_data.py \
--image_folder="/XXX/JPEGImages" \
--semantic_segmentation_folder="/XXX/SegmentationClassRaw" \
--list_folder="/XXX/ImageSets/Segmentation" \
--image_format="jpg" \
--output_dir="/XXX/tfrecord"其中,image_folder 是 jpg 原图文件夹,semantic_segmentation_folder 是转化后label图文件夹,list_folder是 train.txt、val.txt、trainval.txt 所在的文件夹,output_dir是输出数据存放的文件夹。
转换后的数据保存到tfrecord(tfrecord文件夹事先建好)。
注意!!!
关于数据标签问题,参考https://github.com/tensorflow/models/issues/3739#issuecomment-402583877
训练结果不理想,问题往往出在数据上。

三、训练准备
1. 修改segmentation_dataset.py(注册数据集)
(1)在这段代码注册数据集,使我的数据集拥有姓名:
_DATASETS_INFORMATION = {
'cityscapes': _CITYSCAPES_INFORMATION,
'pascal_voc_seg': _PASCAL_VOC_SEG_INFORMATION,
'ade20k': _ADE20K_INFORMATION,
'mydataset': _MYDATESET_INFORMATION,
}(2)参照代码中其他数据集形式,加入个人数据集描述配置:
_MYDATASET_INFORMATION = DatasetDescriptor(
splits_to_sizes={
'train': 1413,
'trainval': 2826,
'val': 1413,
},
num_classes=11,
ignore_label=255,
)2. 修改train_utils.py
(1)exclude_list
109 行左右,将:
exclude_list = ['global_step'] 修改为:
exclude_list = ['global_step', 'logits'] 作用是在使用预训练权重时候,不加载该 logit 层。训练自己的数据集时,此处进行修改。
(2)数据不平衡问题
如果数据存在不平衡问题,可以参考https://github.com/tensorflow/models/issues/3730#issuecomment-387100419

举例说明:如果一个二分类(background,object)问题,其中background占了非常大的比例,例如二者的比例为background:object = 10:1,最终设置的权重比例为1:10,如下所示:
# 针对数据不平衡问题,进行如下修改
ignore_weight = 0
label0_weight = 1 # 背景的权重系数
label1_weight = 10 # 目标的权重系数
not_ignore_mask = tf.to_float(tf.equal(scaled_labels, 0)) * label0_weight + \
tf.to_float(tf.equal(scaled_labels, 1)) * label1_weight + \
tf.to_float(tf.equal(scaled_labels, ignore_label)) * ignore_weight四、训练
模型从官网下载:https://github.com/tensorflow/models/blob/master/research/deeplab/g3doc/model_zoo.md
python deeplab/train.py \
--logtostderr \
--train_split="train" \
--model_variant="xception_65" \
--dataset="voc_turbulent" \#前面注册的数据集名称
--atrous_rates=6 \
--atrous_rates=12 \
--atrous_rates=18 \
--output_stride=16 \
--decoder_output_stride=4 \
--train_crop_size=513 \
--train_crop_size=513 \
--training_number_of_steps=30000 \
--base_learning_rate=0.0001 \
--num_clones=3 \#3块显卡
--train_batch_size=9 \#得是显卡数量的倍数哈
--fine_tune_batch_norm=false \
--initialize_last_layer=false \
--last_layers_contain_logits_only=true \
--tf_initial_checkpoint="/XXX/deeplabv3_pascal_train_aug/model.ckpt" \
--train_logdir="/XXX/exp/train_on_train_set/train" \
--dataset_dir="/XXX/tfrecord"
注意:【更多参数设置可参考 train.py】
(1)学习率

(2)batch size

(3)模型选择及参数
![]()

(4)crop size
参考https://github.com/tensorflow/models/blob/master/research/deeplab/g3doc/faq.md的Q8

(5)关于initialize_last_layer和last_layers_contain_logits_only
参考https://github.com/tensorflow/models/issues/3730#issuecomment-380168917
(6)训练时监控
在 train_logdir 存储文件夹的上层(例如我的路径是 /XXX/exp/train_on_train_set)执行命令:
tensorboard --logdir=train终端得到一个网址,如下所示:
![]()
复制到浏览器打开即可:
五、验证
python deeplab/eval.py \
--logtostderr \
--eval_split="val" \
--model_variant="xception_65" \
--dataset="voc_turbulent" \
--num_clones=3 \#3块显卡
--atrous_rates=6 \
--atrous_rates=12 \
--atrous_rates=18 \
--output_stride=16 \
--decoder_output_stride=4 \
--eval_crop_size=513 \
--eval_crop_size=513 \
--checkpoint_dir="/XXXh/exp/train_on_train_set/train" \
--eval_logdir="/XXX/exp/train_on_train_set/eval" \
--dataset_dir="/XXX/tfrecord" \
--max_number_of_evaluations=1
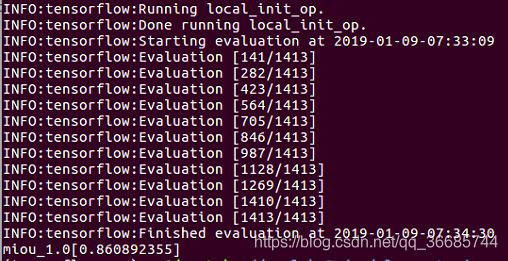
结果如下:
六、可视化
为了最后输出的分割图便于观看,可以为其添加颜色,修改 research\deeplab\utils 下的 get_dataset_colormap.py 即可:
(1)下面两处添加自己数据集的信息
# Dataset names.
_ADE20K = 'ade20k'
_CITYSCAPES = 'cityscapes'
_MAPILLARY_VISTAS = 'mapillary_vistas'
_PASCAL = 'pascal'
_MYDATASET = 'mydataset'
# Max number of entries in the colormap for each dataset.
_DATASET_MAX_ENTRIES = {
_ADE20K: 151,
_CITYSCAPES: 19,
_MAPILLARY_VISTAS: 66,
_PASCAL: 256,
_MYDATASET: 11
}(2)创建自己数据的 colormap:
def create_mydataset_label_colormap():
"""Creates a label colormap used in mydatasets segmentation benchmark.
Returns:
A colormap for visualizing segmentation results.
"""
return np.asarray([
[128, 64, 128],
[244, 35, 232],
[70, 70, 70],
......
])(3) 在下面两处添加自己的数据集:
def get_ade20k_name():
return _ADE20K
def get_cityscapes_name():
return _CITYSCAPES
def get_mapillary_vistas_name():
return _MAPILLARY_VISTAS
def get_pascal_name():
return _PASCAL
def get_mydataset_name():
return _MYDATASET
......
if dataset == _ADE20K:
return create_ade20k_label_colormap()
elif dataset == _CITYSCAPES:
return create_cityscapes_label_colormap()
elif dataset == _MAPILLARY_VISTAS:
return create_mapillary_vistas_label_colormap()
elif dataset == _PASCAL:
return create_pascal_label_colormap()
elif dataset == _MYDATASET:
return create_mydataset_label_colormap()
else:
raise ValueError('Unsupported dataset.')随后就可以进行可视化了:
python deeplab/vis.py \
--logtostderr \
--vis_split="val" \
--model_variant="xception_65" \
--dataset="voc_turbulent" \
--num_clones=3 \
--atrous_rates=6 \
--atrous_rates=12 \
--atrous_rates=18 \
--output_stride=16 \
--decoder_output_stride=4 \
--vis_crop_size=513 \
--vis_crop_size=513 \
--checkpoint_dir="/xxx/exp/train_on_train_set/train" \
--vis_logdir="/xxx/exp/train_on_train_set/vis" \
--dataset_dir="/xxx/tfrecord" \
--max_number_of_iterations=1七、输出模型
python deeplab/export_model.py \
--logtostderr \
--checkpoint_path="/xxx/exp/train_on_train_set/train/model.ckpt-30000" \
--export_path="/xxx/exp/train_on_train_set/export/frozen_inference_graph.pb" \
--model_variant="xception_65" \
--atrous_rates=6 \
--atrous_rates=12 \
--atrous_rates=18 \
--output_stride=16 \
--decoder_output_stride=4 \
--num_classes=11 \
--crop_size=513 \
--crop_size=513 \
--inference_scales=1.0即可在export文件夹下得到自己的输出模型 frozen_inference_graph.pb,下面进行单张图像预测时可以使用此模型。
八、预测单张图片
在deeplab_demo.ipynb的基础上做些修改,为方便使用,给出网盘链接,使用时修改路径即可。
链接:https://pan.baidu.com/s/16iffY6WkOwjRezttAuulFQ
提取码:06fy
效果如下:
